Hadoop 2.0 HA与Federation实战:应对单点故障的革命
需积分: 0 5 浏览量
更新于2024-06-30
收藏 332KB DOCX 举报
在Hadoop 2.0之前,HDFS(Hadoop分布式文件系统)面临着单点故障的重大挑战,这严重影响了系统的可用性和数据完整性。为了解决这个问题,Apache Hadoop在2012年5月发布的2.0 alpha版本引入了两个关键特性:High Availability (HA) 和 Federation。这些新特性旨在提升系统的可靠性与扩展性。
1. **HA(High Availability)**:
HA的主要目标是消除NameNode(名称节点)的单点故障。在Hadoop 2.0以前,尝试过的解决方案如Secondary NameNode虽然可以在一定程度上缓解问题,但它并非真正的HA。Secondary NameNode仅能阶段性地合并edits(编辑日志)和fsimage(文件系统镜像),用于加速集群启动,但当主NameNode失效时,它不能立即接管服务,且不能保证数据完整性。Backup NameNode作为Warm Standby,虽然能在内存中复制NN状态,但只支持阶段性的checkpoint,同样无法提供完整的故障转移功能。
2. **Federation**:
Federation则是将多个独立的Hadoop集群作为一个统一的命名空间来管理,这有助于处理大规模的数据分布和跨集群的操作。通过Federation,用户可以在不同的Hadoop集群之间透明地访问数据,无需关心数据实际存储在哪一个集群中。这对于需要处理海量数据和复杂数据分片的场景极其重要。
3. **其他解决方案**:
非Hadoop官方提供的解决方案还包括将name.dir指向NFS(网络文件系统),这是一种冷备方式,虽然能保证元数据安全,但恢复过程依赖手动操作。Facebook的AvatarNode是另一种Hot Standby,需要人工干预切换,避免脑裂问题。还有一些解决方案依赖外部的高可用性工具,比如DRBD(分布式复制块设备)、Linux HA或VMware FT等。
总结来说,Hadoop 2.0引入的HA和Federation是针对HDFS单点故障和集群扩展的重大改进。HA提供了可靠的NameNode故障转移机制,提高了服务可用性;而Federation则增强了数据管理和操作的灵活性。这些特性对于满足大型企业的高可用性需求,尤其是金融行业,具有重要意义。在实际应用中,根据业务规模和特定需求,可能需要结合多种技术手段来构建一个稳定、高效的Hadoop环境。
▪ 如果现有的客户端只连某台 NN 的话,代码和配置也无需改动。
▪ 分离命名空间管理和块存储管理
▪ 提供良好扩展性的同时允许其他文件系统或应用直接使用块存储池
▪ 统一的块存储管理保证了资源利用率
▪ 可以只通过防火墙配置达到一定的文件访问隔离,而无需使用复杂的
Kerberos 认证
▪ 客户端挂载表
▪ 通过路径自动对应 NN
▪ 使 Federation 的配置改动对应用透明
五、测试环境
以上是 HA 和 Federation 的简介,对于已经比较熟悉 HDFS 的朋友,这些信息应该
已经可以帮助你快速理解其架构和实现,如果还需要深入了解细节的话,可以去详
细阅读设计文档或是代码。这篇文章的主要目的是总结我们的测试结果,所以现在
才算是正文开始。
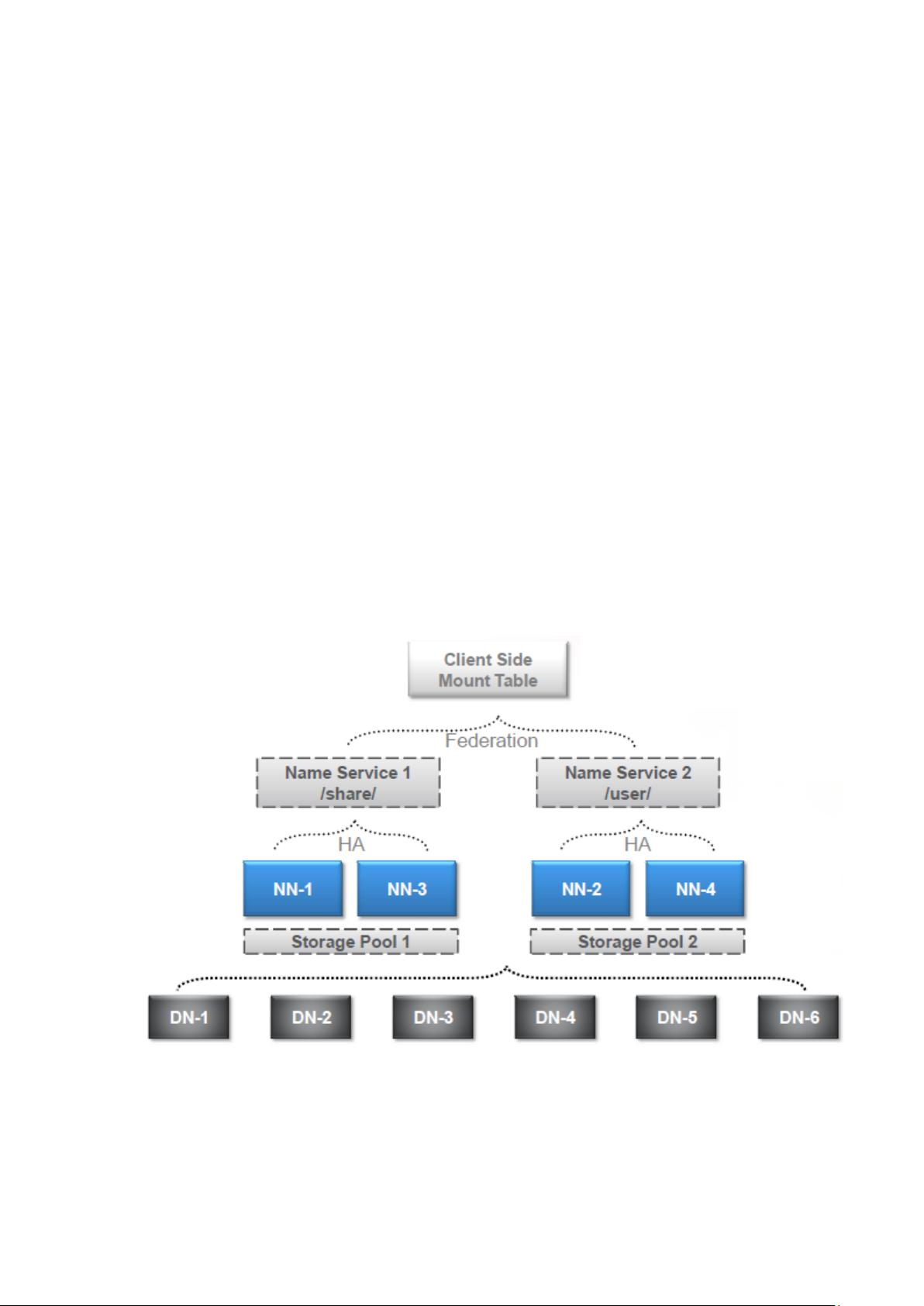
为了彻底搞清 HA 和 Federation 的配置,我们直接一步到位,选择了如下的测试场
景,结合了 HA 和 Federation:
这张图里有个概念是前面没有说明的,就是 NameService。Hadoop 2.0 里对 NN
进行了一层抽象,提供服务的不再是 NN 本身,而是 NameService(以下简称 NS)。
Federation 是由多个 NS 组成的,每个 NS 又是由一个或两个(HA)NN 组成的。在接
下里的测试配置里会有更直观的例子。
剩余20页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2017-09-23 上传
2017-07-31 上传
2022-08-03 上传
点击了解资源详情
点击了解资源详情
2018-11-22 上传

glowlaw
- 粉丝: 28
- 资源: 274
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
