数据湖:下一代数据仓库的解决方案
PDF格式 | 304KB |
更新于2024-08-28
| 198 浏览量 | 举报
数据湖(DataLake)是当前大数据领域的一个重要概念,它的出现主要针对传统数据仓库存在的问题,如长开发周期、高成本和细节数据丢失等。数据湖的初衷是提供一个灵活、可扩展的平台,以处理日益多样化的数据类型,包括结构化、半结构化和非结构化数据。
传统的数据仓库通常基于关系型数据库管理系统(RDBMS),它们在处理结构化数据方面表现出色,但对于半结构化和非结构化数据处理能力有限。随着Hadoop的崛起,数据仓库开始转向以Hadoop为基础的技术栈,这使得数据仓库能够容纳更多种类的数据,具备了部分数据湖的功能。然而,数据湖的概念不仅限于Hadoop,它也可以涵盖其他技术,如MPP数据库、云存储解决方案等。
数据湖的核心特性在于其“原始”和“未经加工”的特性。在数据湖中,数据以原始格式存储,不预先设定特定的模式或结构,允许用户在需要时进行灵活的分析和探索。这与数据仓库的预先定义模式和ETL(抽取、转换、加载)过程形成鲜明对比。数据仓库倾向于将数据清洗、转换为一致的格式,以便进行高效查询和报表生成,而数据湖强调保留数据的原始状态,以备后续分析使用。
数据湖的实现方式多样,可以是Hadoop分布式文件系统(HDFS),也可以是结合MPP数据库(如Greenplum、Hive)和传统的数据仓库(如Oracle、Teradata)的混合架构。这种“混搭”模式旨在平衡处理速度、灵活性和成本效益,以满足不同业务场景的需求。
数据湖的实施并不意味着它可以解决所有数据管理问题。事实上,数据湖可能带来新的挑战,如数据治理、数据质量管理和安全性。没有适当的治理,数据湖可能会变成“数据沼泽”,充斥着无用或低质量的数据。因此,建立有效的元数据管理、数据生命周期管理策略以及安全访问控制是确保数据湖成功的关键。
未来的数据湖发展趋势可能会更加侧重于自动化、智能化和集成化。例如,利用人工智能和机器学习技术进行自动化的数据清理和预处理,以及通过数据目录和自助式分析工具提升用户体验。同时,随着云计算的发展,云数据湖成为趋势,提供弹性伸缩的存储和计算能力,降低了企业的运维负担。
数据湖作为下一代数据仓库的候选者,为企业提供了处理大数据的新途径,但同时也要求企业在实施过程中充分考虑数据治理、安全和性能优化,以实现其潜力。
数据湖数据湖(DataLake)-剑指下一代数据仓库剑指下一代数据仓库
数据湖是数据仓库的补充,是为了解决数据仓库漫长的开发周期,高昂的开发、维护成本,细节数据丢失等问题出现的。
数据湖大多是相对于传统基于RDBMS的数据仓库,而从2011年前后,也就是数据湖概念出现的时候,很多数据仓库逐渐迁移
到以Hadoop为基础的技术栈上,而且除了结构化数据,半结构化、非结构数据也逐渐的存储到数据仓库中,并提供此类服
务。这样的数据仓库,已经具有了数据湖的部分功能。
数据湖正在成为一种越来越流行的大数据解决方案,而数据湖这个词已经被大数据供应商赋予了太多不同的含义,如果有什么
工作是传统数据仓库做不了的,那就把它塞进数据湖,以至于数据湖已经变成了一个定义模糊的概念。数据湖是不是就是传说
中的银弹,可以解决所有数据仓库不能解决的问题呢。本文将讲述,关于数据湖的定义,与数据仓库的区别,以及现实中的数
据湖解决方案和未来会怎样发展。
什么是数据湖
维基百科对数据湖的定义是,数据湖是一种在系统或存储库中以自然格式存储数据的方法,它有助于以各种模式和结构形式配
置数据,通常是对象块或文件。数据湖的主要思想是对企业中的所有数据进行统一存储,从原始数据(源系统数据的精确副
本)转换为用于报告、可视化、分析和机器学习等各种任务的目标数据。数据湖中的数据包括结构化数据(关系数据库数
据),半结构化数据(CSV、XML、JSON等),非结构化数据(电子邮件,文档,PDF)和二进制数据(图像、音频、视
频),从而形成一个容纳所有形式数据的集中式数据存储。
可见,企业使用数据湖架构,核心出发点就是把不同结构的数据统一存储,使不同数据有一致的存储方式,在使用时方便连
接,真正解决数据集成问题。因此,数据湖架构最主要的特点,一是支持异构数据聚合,二是无需预定义数据模型即可进行数
据分析。
数据湖从本质上来讲,是一种企业数据架构方法,物理实现上则是一个数据存储平台,用来集中化存储企业内海量的、多来
源,多种类的数据,并支持对数据进行快速加工和分析。从实现方式来看,目前Hadoop是最常用的部署数据湖的技术,但并
不意味着数据湖就是指Hadoop集群。为了应对不同业务需求的特点,MPP数据库+Hadoop集群+传统数据仓库这种“混搭”架构
的数据湖也越来越多出现在企业信息化建设规划中。
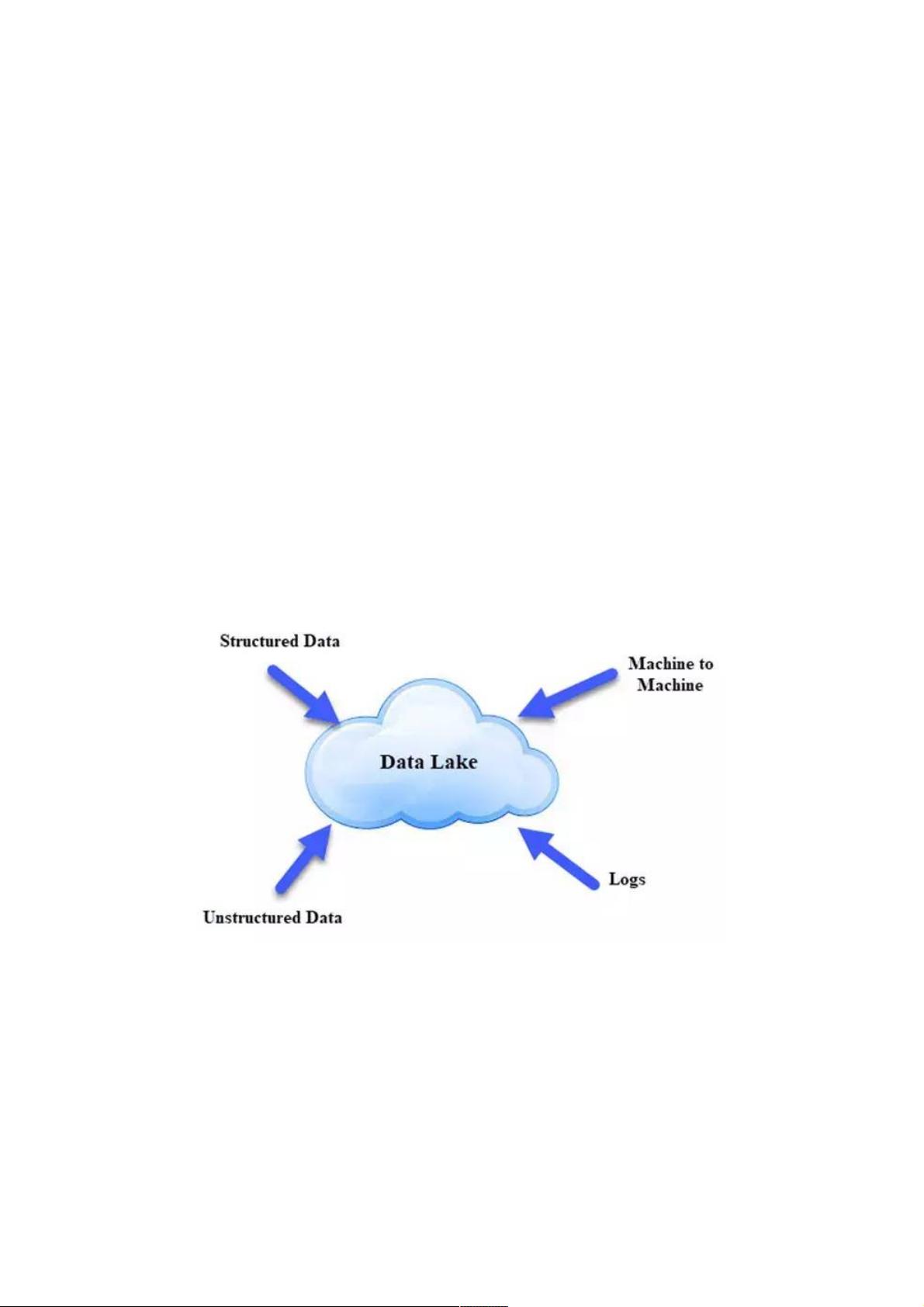
Data Lake是一个存储库,可以存储大量结构化,半结构化和非结构化数据。它是以原生格式存储每种类型数据的地方,对帐
户大小或文件没有固定限制。它提供高数据量以提高分析性能和本机集成。
Data Lake就像一个大型容器,与真正的湖泊和河流非常相似。就像在湖中你有多个支流进来一样,数据湖有结构化数据,非
结构化数据,机器到机器,实时流动的日志。
Data Lake使数据民主化,是一种经济有效的方式来存储组织的所有数据以供以后处理。研究分析师可以专注于在数据中找到
意义模式而不是数据本身。与数据存储在文件和文件夹中的分层数据仓库不同,Data湖具有扁平的架构。Data Lake中的每个
数据元素都被赋予唯一标识符,并标记有一组元数据信息。
数据湖与传统数据仓库的区别
数据仓库是一个优化的数据库,用于分析来自事务系统和业务线应用程序的关系数据。事先定义数据结构和 Schema 以优化
快速 SQL 查询,其中结果通常用于操作报告和分析。数据经过了清理、丰富和转换,因此可以充当用户可信任的“单一信息
源”。
数据湖有所不同,因为它存储来自业务线应用程序的关系数据,以及来自移动应用程序、IoT 设备和社交媒体的非关系数据。
捕获数据时,未定义数据结构或 Schema。这意味着您可以存储所有数据,而不需要精心设计也无需知道将来您可能需要哪些
下载后可阅读完整内容,剩余4页未读,立即下载
相关推荐

380 浏览量


8 浏览量


weixin_38637805
- 粉丝: 4
- 资源: 952
 我的内容管理
展开
我的内容管理
展开







最新资源
- ConvBert
- mineops:Minecraft自动化wDocker和AWS CDK
- 我的日常学习资料整合信息:nodejs,java,oracle
- fl_demo_container:扑扑的应用程序,以了解容器小部件
- flux-jsf:Flux JSF 2 托管 Bean 示例
- C# WinForm客户端连接 WebSocket
- 电子竞技团队:计算机科学与技术学院(Tralbalho deconclusãocurso do curso)。 (电子竞技团队)MEAN Stack的电子竞技平台(MongoDB,Express,Angular e Node.js)
- scrollBox_visualbasic_
- JavaTasks-Tutorials
- BBSort:BB排序的实现,计数和存储桶样式的混合,稳定的排序算法,即使对于非均匀分布的数字也可以使用O(N)时间工作
- 使您的桌面数据库应用程序更好的10件事
- 构建Linux
- APx500_4.6_w_dot_Net 音频分析仪软件 apx515 apx525
- android-NavigationDrawer-master
- Yelp-Camp:一个完整的Node.js项目,允许用户创建,读取,更新和删除营地信息
- ksolve_石川法啮合刚度改良程序_石川_
