大数据管理与挖掘:Twitter应用深度解析
需积分: 10 5 浏览量
更新于2024-07-23
收藏 3.3MB PDF 举报
"大数据管理和数据挖掘及它们在twitter的应用实例"
大数据是现代计算行业中备受关注的现象,自“互联网”以来,它已经引发了广泛的关注。大数据的主要特征在于其海量性、多样性、高速性和价值密度低。这些特性使得传统数据处理方法无法应对,因此催生了新的技术和工具。
大数据管理的关键技术之一是Hadoop,这是一个开源框架,专门设计用于处理和存储大规模数据集。Hadoop基于分布式文件系统HDFS,能够将数据分布在多台计算机上,实现数据的并行处理,提高处理效率。此外,Hadoop的核心组件MapReduce提供了数据处理的编程模型,使得开发者可以编写应用程序来处理大规模数据。
在数据挖掘方面,大数据挖掘是当前研究的热点。它涉及到从大数据中发现模式、关联规则和预测模型等有价值的信息。常见的数据挖掘方法包括分类、聚类、回归和关联分析。数据挖掘不仅应用于商业智能,还在社交网络分析、网络安全、医疗健康等领域发挥着重要作用。
提到大数据在Twitter的应用,Twitter是一个海量信息的平台,每天都有数亿条推文产生。这些数据包含了大量的用户行为、情感和趋势信息。Twitter利用大数据管理技术收集、存储和处理这些数据,例如通过实时流处理系统如Apache Storm或Spark Streaming进行实时分析。数据挖掘则用于理解用户行为模式、预测热门话题、检测网络舆情以及个性化推荐等。通过分析用户的推文内容、时间、地理位置等信息,Twitter可以提供更精准的广告定向,提升用户体验。
在学术界,大数据和数据挖掘的研究得到了广泛的关注。一些重要的会议如知识发现与数据挖掘(KDD)、国际数据挖掘大会(ICDM)和欧洲机器学习与数据挖掘大会(ECML PKDD)都围绕这一主题展开。同时,专业期刊如《数据挖掘与知识发现》和《机器学习》发表了大量关于大数据挖掘的最新研究成果。
定义大数据,2001年的3V模型(Volume、Velocity、Variety)被广泛接受,后来又增加了Value(价值)和Veracity(真实性)。随着技术的发展,大数据的定义也在不断演变,现在还包括Variability(易变性)、Vicinity(邻近性)等维度。
大数据管理和数据挖掘是当今信息技术领域的核心组成部分,它们在Twitter等社交媒体平台上的应用,揭示了大数据的潜力和影响力,同时也推动了相关技术的不断创新和发展。
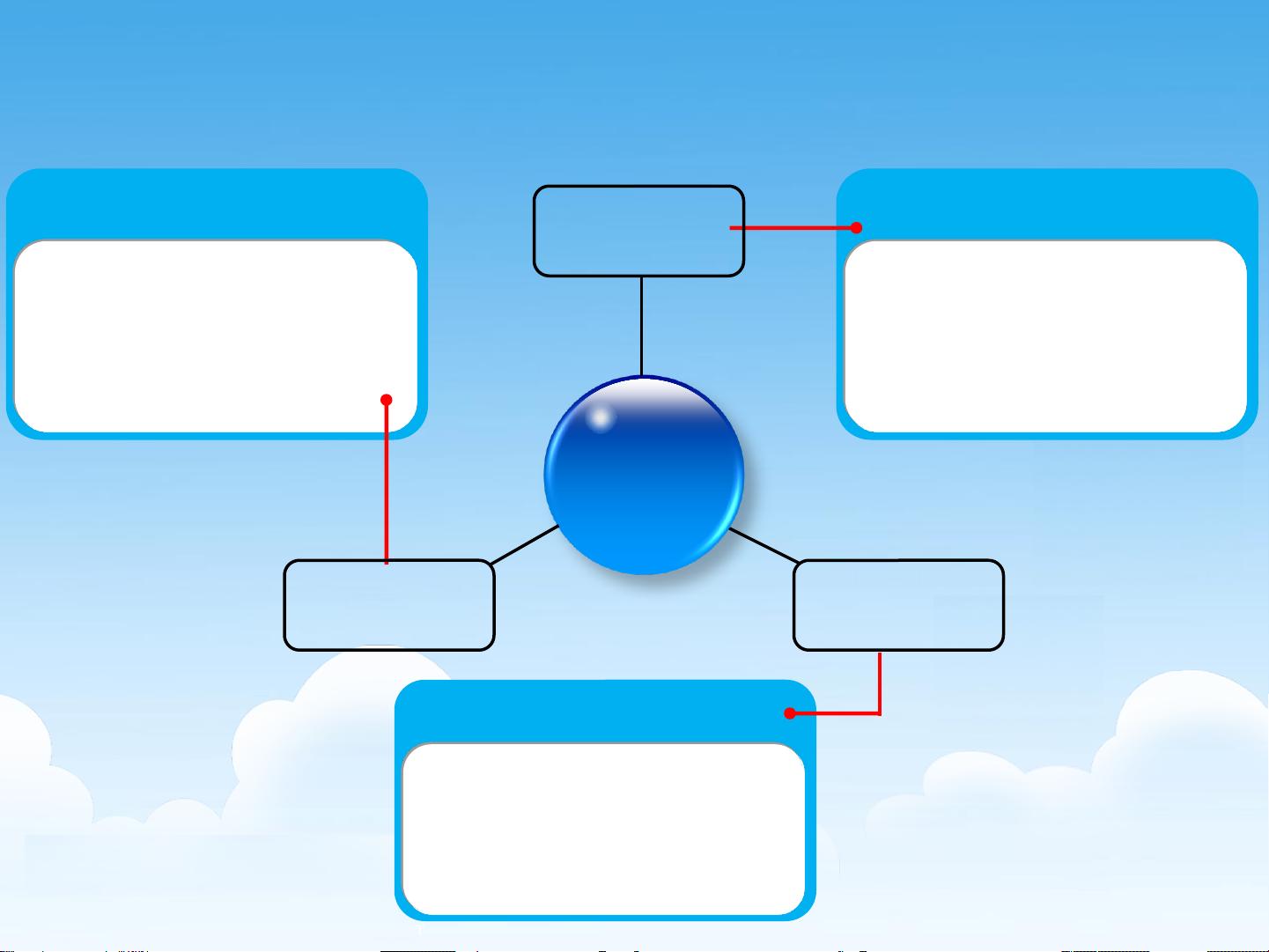
Big Data Attributes
Volume
•Terabytes and Petabytes
•Walmart transactions:
2.5 petabytes /hour
• Facebook:
25 terabyte/day
Velocity
•400 million tweets/day
•1 million transactions /hour
Variety
•Unstructured
•Videos/Audios/images
•Logs
•Click trails
•tweets
Big Data
Volume
VelocityVariety
Krishnan, Krish.
Data Warehousing in the Age of Big Data
. Newnes, 2013.
剩余33页未读,继续阅读
2021-02-18 上传
2022-08-04 上传
2014-03-28 上传
点击了解资源详情
点击了解资源详情









