Intellij IDEA中软件开发与功能扩展指南
需积分: 0 79 浏览量
更新于2024-08-04
收藏 2.07MB DOCX 举报
"软件开发打包文档1描述了如何在Intellij IDEA中导入项目并进行大数据相关的软件开发,特别是关于功能扩展和数据源设置的详细步骤。文档特别提到了日志格式解析功能的自定义和程序运行时的数据源配置。"
在软件开发过程中,尤其是在大数据领域,正确地设置开发环境和理解代码扩展机制至关重要。本文档提供的指南适用于那些使用Intellij IDEA作为集成开发环境(IDE)的开发者,特别是在处理基于大数据平台如FusionInsight的项目时。以下是文档中的关键知识点:
1. **开发环境准备**:
- 使用Intellij IDEA导入项目:通过File->ImportProject…选择项目目录中的pom.xml文件,可以方便地导入项目并开始开发。
- 语言选择:项目支持Java和Scala语言,开发者可以根据个人偏好选择合适的语言进行功能开发和扩展。
2. **功能扩展**:
- 日志格式解析:默认支持分隔符和JSON格式,若需解析其他格式,需要在解析类中进行扩展。这可能涉及在现有模块中添加新类或创建新模块。
- 服务配置:自定义类需要继承`TopicValueProcess`,并实现`convertToColumns`方法,该方法将数据解析为与表结构匹配的数组。
- 注册服务:在`META-INF/services/com.service.data.spark.streaming.process.TopicValueProcess`文件中添加自定义类的名称,以便系统识别和使用。
3. **程序运行**:
- 数据源设置:在程序运行前,必须配置数据源信息,包括配置信息所在的数据库(db.properties文件的`db.config.*`)以及Spark Streaming处理后数据落地的数据库信息(如`db.mysql.*`, `db.oracle.*`, `db.other.*`)。
- 数据源加密:数据库的用户名和密码需要使用TestEncrypt工具进行加密处理,确保数据安全。
4. **数据源配置**:
- 多数据源支持:文档指出可以根据实际需求配置多个数据源,允许Spark Streaming程序处理的数据流向不同的数据库系统。
以上就是软件开发打包文档1的主要内容,它为开发者提供了一个清晰的流程,从导入项目到实现特定功能,再到运行程序和配置数据源,每个步骤都提供了详细的指导。对于大数据软件工程的实践者来说,这些知识是进行有效开发的关键。
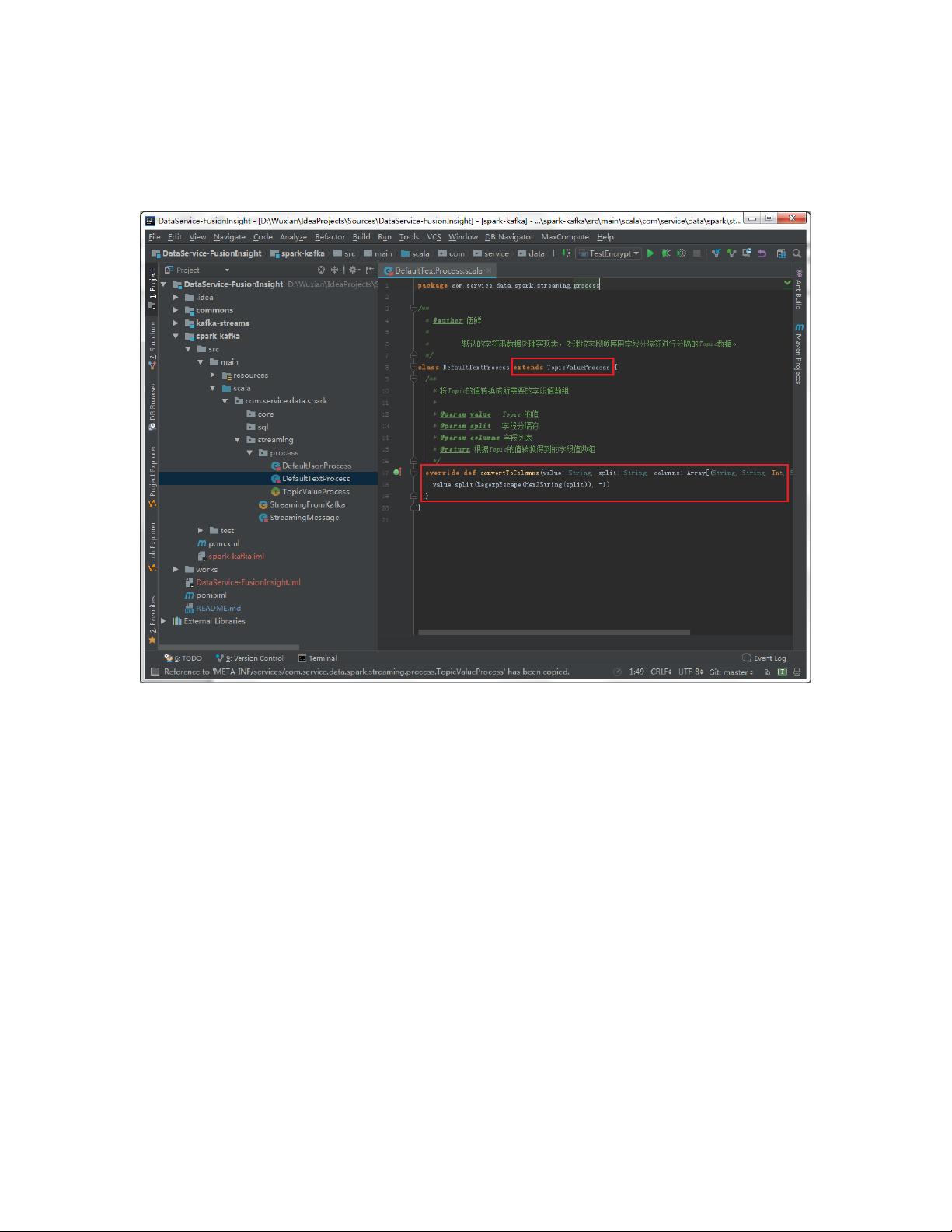
自定义的类需要继承 TopicValueProcess,并实现 convertToColumns 方法,该方法仅实现一
个功能:从给定的一行数据中解析出与表结构字段顺序匹配的字段值组成一个数组结构返
回。
自定义类编写完成后,需要在指定文件中添加实现类的名称。
剩余12页未读,继续阅读
2022-03-20 上传
2021-03-18 上传
2008-12-14 上传
2011-10-18 上传
2022-03-20 上传
2022-03-20 上传
2022-03-20 上传
2023-05-11 上传
2010-01-25 上传

王元祺
- 粉丝: 520
- 资源: 303
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++ Qt影院票务系统源码发布,代码稳定,高分毕业设计首选
- 纯CSS3实现逼真火焰手提灯动画效果
- Java编程基础课后练习答案解析
- typescript-atomizer: Atom 插件实现 TypeScript 语言与工具支持
- 51单片机项目源码分享:课程设计与毕设实践
- Qt画图程序实战:多文档与单文档示例解析
- 全屏H5圆圈缩放矩阵动画背景特效实现
- C#实现的手机触摸板服务端应用
- 数据结构与算法学习资源压缩包介绍
- stream-notifier: 简化Node.js流错误与成功通知方案
- 网页表格选择导出Excel的jQuery实例教程
- Prj19购物车系统项目压缩包解析
- 数据结构与算法学习实践指南
- Qt5实现A*寻路算法:结合C++和GUI
- terser-brunch:现代JavaScript文件压缩工具
- 掌握Power BI导出明细数据的操作指南
