DBSCAN算法详解:基于密度的聚类方法
版权申诉
121 浏览量
更新于2024-06-27
收藏 4.02MB PPTX 举报
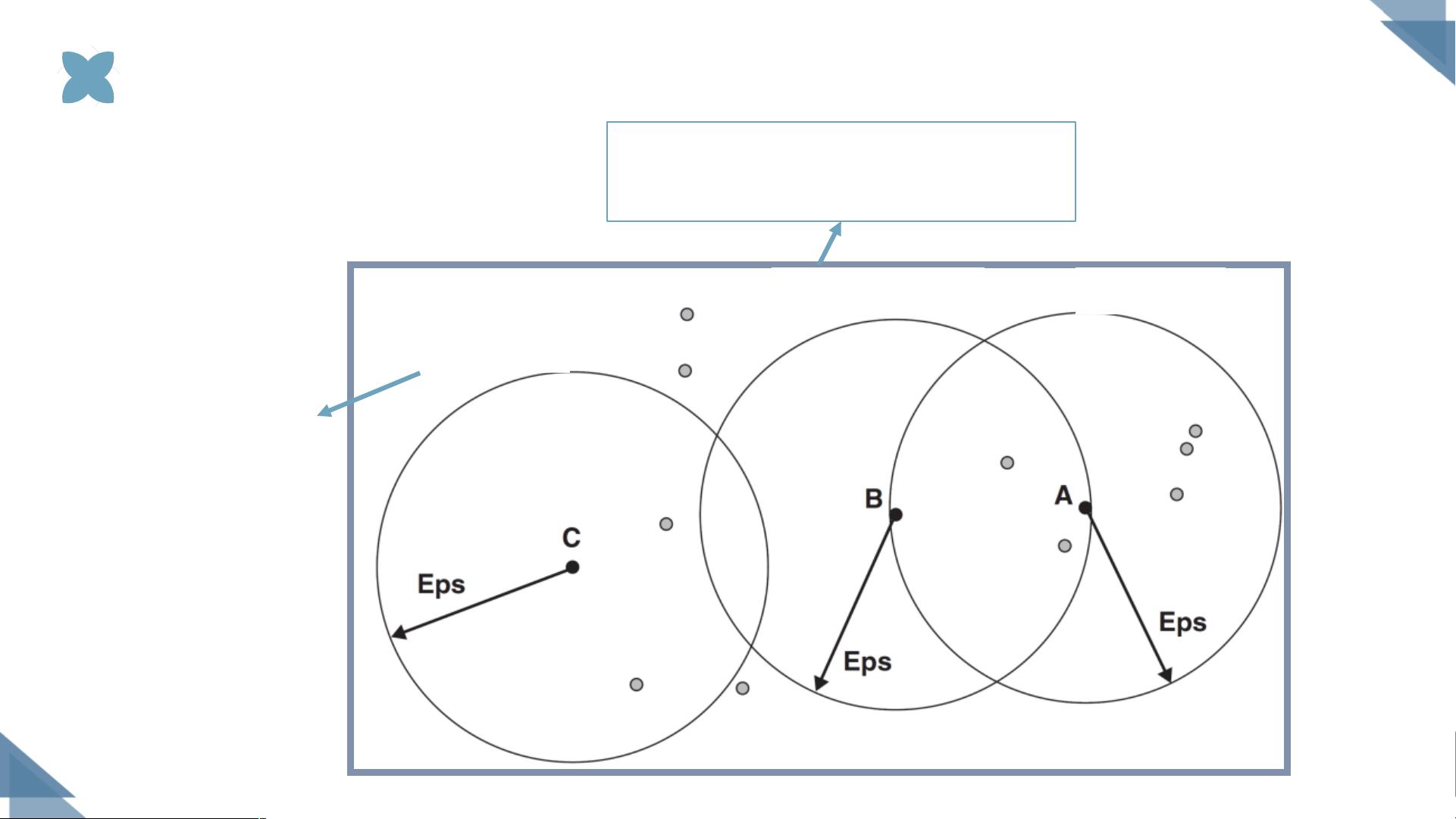
"DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,适用于处理未知结构的数据集,因为它不需要预先设定聚类的数量。DBSCAN通过识别数据点在空间分布中的稠密区域来划分簇,将点分为核心点、边界点和噪声点。核心点是其Eps邻域内至少包含MinPts个点的点,而边界点位于某个核心点的邻域内但本身不是核心点。噪声点既非核心点也非边界点。DBSCAN的主要优点包括对异常值的容忍度高和能够处理各种形状和大小的簇。
DBSCAN算法的工作流程如下:
1. 首先选择一个点,计算其Eps邻域内包含的点数(MinPts)。如果满足条件,该点被标记为核心点,并开始构建一个新的簇。
2. 将该核心点的密度可达点(即可以通过其他核心点到达的点)加入到簇中,这包括其他核心点及其Eps邻域内的点。
3. 继续选择未分配的点,重复上述步骤,直至所有点都已被分配到簇或标记为噪声点。
DBSCAN的参数Eps和MinPts至关重要。Eps定义了邻域半径,而MinPts指定了邻域内必须存在的最少点数。这两个参数的选择直接影响聚类结果的质量,需要根据具体数据集的特性进行调整。通常,较小的Eps值会导致更多小的簇,而较大的Eps值可能会合并小的簇。同样,较高的MinPts值可能导致更少但更大的簇。
DBSCAN与其他基于密度的聚类方法如OPTICS(Ordering Points To Identify the Clustering Structure)、DENCLUE(Density-based Clustering)和CLIQUE(Clustering In Quest)相比,DBSCAN在实际应用中更为常见,因为它既简单又高效,且能够处理不规则形状的簇。
DBSCAN算法是一种强大的无监督学习工具,尤其在处理包含噪声和不规则结构的数据时表现出色。然而,正确选择Eps和MinPts参数是成功应用DBSCAN的关键,这通常需要对数据集有一定程度的理解和试验。"
DBSCAN算法
MinPts = 7
核心点
噪声点
边界点
不是核心点,但它落在某个
核心点的邻域内
既非核心点也
非边界点
剩余16页未读,继续阅读
2023-01-14 上传
2023-01-14 上传
2023-01-14 上传
2023-01-14 上传
2023-01-14 上传
2023-01-14 上传

知识世界
- 粉丝: 375
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
