自动写诗实验:TensorFlow LSTM与GRU模型应用
需积分: 27 18 浏览量
更新于2024-07-15
收藏 2.18MB PPTX 举报
"自动写诗ppt汇报.pptx"
这篇PPT主要介绍了如何利用深度学习技术,特别是TensorFlow 2.0框架,进行自动写诗的实验。自动写诗是自然语言处理(NLP)领域的一个经典应用,它涉及到文本生成任务,通过训练神经网络模型学习诗歌的数据集,最终能够自动生成新的诗句。实验的核心是使用循环神经网络(RNN),如长短期记忆网络(LSTM)或门控循环单元(GRU)。
实验流程主要包括以下步骤:
1. 数据预处理:首先,需要收集诗歌数据集,对数据进行清洗和预处理,以便于模型理解和学习。这可能包括分词、去除停用词、词干化等操作。
2. 模型构建:使用TensorFlow 2.0构建RNN模型,可以选择LSTM或GRU作为基础单元。这些网络结构能够捕获文本序列中的上下文依赖,适合处理语言任务。
3. 训练与优化:将预处理后的数据输入模型进行训练,通过反向传播算法调整模型参数,以最小化损失函数(Loss)并提高准确率(Accuracy)。训练次数、学习率、批次大小等因素都会影响模型的性能。
4. 模型保存与应用:当模型达到预期性能后,将其保存以便后续使用。输入一句自定义的起始语句,模型可以生成接续的诗句。
在实验过程中,作者遇到了一些常见问题:
1. CUDA库不匹配:作者的电脑安装的是TensorFlow GPU 2.0.0版本,但系统中却检测到2.1.0版本,导致无法正常运行。解决方法是检查和修复CUDA和TensorFlow版本的兼容性,确保所有相关库的版本一致。
2. 数据格式错误与内存溢出:在尝试将数据集转化为适合LSTM输入的格式时,由于数据处理不当,导致数据爆炸和系统卡死。解决方案是参照其他人的代码,特别是基于PyTorch的数据加载方式,调整数据预处理和模型输入的代码。
安装TensorFlow和CUDA的过程中,作者还分享了使用清华镜像源加速pip安装的经验,以及遇到环境变量配置失效的问题。解决环境问题通常需要检查系统路径设置,确保CUDA和相关库的路径被正确添加到PATH变量中。
这个PPT详细记录了一个使用TensorFlow 2.0进行自动写诗实验的完整过程,包括问题的发现与解决,对于理解深度学习在NLP中的应用,特别是文本生成任务,具有很好的参考价值。
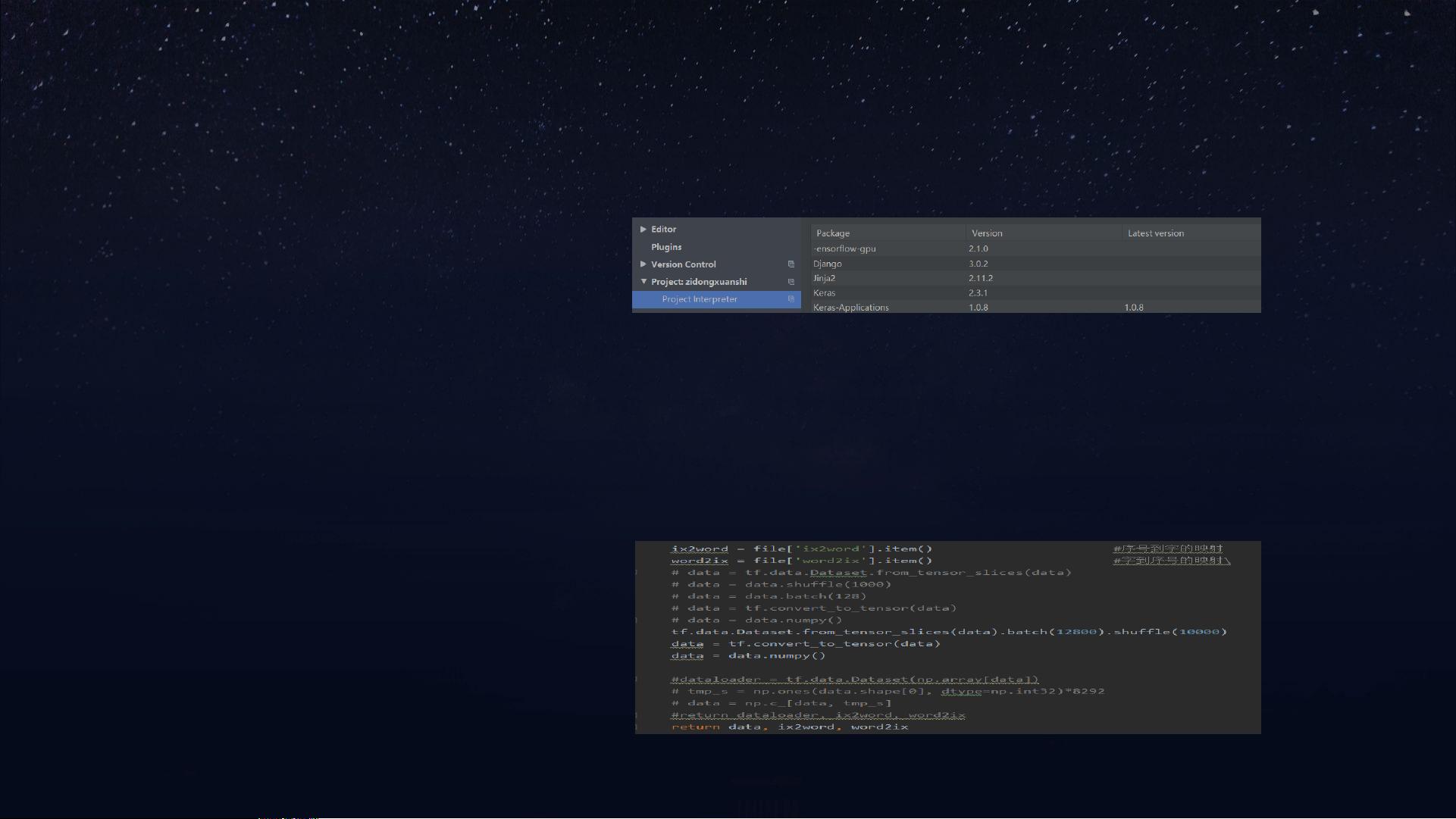
tensorow2.0 学习犯的错和总结
问题:
使用电脑跑数据发现又出现了上次一
样的问题,说找不到安装的 的库,
仔细查看了电脑安装路径发现其实是存
在的,这个时候怀疑 自己升级
了 的版本导致 对不上,
查看过程中发现果然有个奇怪的
版本是 ;但是我电脑适
配的应该是 版本;
所以搞了一下午的卸载重装
的版本,依旧没有解决。
因为按照老师给的数据集,我读取出
来,先是发现读取的 输入模型出现
格式错误,随后尝试在按照 的
用 写 在把
作为 !" 的输入,就出现了
数据爆炸的问题;重复多次出现了电脑
卡机不动的情况;
剩余14页未读,继续阅读

ZhangLH66
- 粉丝: 63
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android应用源码利用poi将内容填到word模板-IT计算机-毕业设计.zip
- mdi-es:材料设计图标导出为ES模块
- LocationSearch
- 行业文档-设计装置-一种利用浸胶纸作为过渡联接体的胶合板.zip
- ImageProcessingApp:使用流行的MVC架构的图像处理应用程序
- hideandseek:Hide & Seek 是一款开源的多人在线街机游戏,对抗两支捉迷藏者团队,玩法有趣快节奏。 项目已从 https 移出
- angular-first-app
- 数据库课程设计-家庭理财管理.zip
- MochaBabelCoverage:一个 Mocha 运行器,支持对包含 JSX 的文件运行 Mocha,并支持覆盖率报告
- 脑机接口BCI-eeglab安装包
- grantwforsythe.github.io
- 性能测试工具LoadRunner书籍(14本)目录知识点(思维导图加图).rar
- ArgRouter:为js函数添加重载功能
- 2D形状
- android应用源码合肥工业大学客户端源码-IT计算机-毕业设计.zip
- PdfFormFillerUTF-8:带有命令行或 WWW 界面的简单 PDF Form Filler 实用程序。-开源
