Python与Selenium:模拟浏览器操作,轻松应对反爬策略
版权申诉
86 浏览量
更新于2024-09-14
1
收藏 248KB PDF 举报
在Python中,Selenium是一个强大的工具,用于模拟浏览器自动化操作,特别适用于处理那些采用复杂动态加载或实施了反爬虫策略的网站数据抓取。Selenium作为Web应用程序测试的基础框架,它的核心理念是提供与真实用户行为一致的浏览器环境,支持多种浏览器(如IE、Firefox、Chrome等)和操作系统。
在进行网站数据采集时,遇到的挑战可能包括JavaScript加密、Ajax请求以及反调试技术。这时,利用Selenium可以编写Python脚本来模拟用户的交互动作,例如点击按钮、填写表单,从而获取隐藏或动态加载的数据。例如,可以通过find_element_by_xpath或find_elements_by_xpath方法定位页面上的特定元素,进而实现元素的查找、赋值和事件触发。
Python编程中的关键知识点在这一过程中得以体现,比如:
1. **元素定位**:Selenium提供了多种定位元素的方式,包括ID、Name、ClassName、CssSelector、PartialLinkText、LinkText、XPath和TagName等,这有助于根据不同的网页结构灵活选择定位策略。
2. **数据操作**:定位到元素后,可以读取元素的值(get_attribute)、设置属性(send_keys)或触发事件(click),执行模拟用户的实际操作。
3. **并发控制**:为了提高效率和避免阻塞用户界面,使用Python的线程(threading)机制进行后台任务处理。通过创建继承自threading.Thread的类,重写run方法来定义新线程,并通过线程锁(threading.Lock)确保线程间的同步。
4. **队列(Queue)应用**:将Selenium执行过程中的信息存储在Queue中,便于管理和异步处理。这样可以确保主线程不被阻塞,同时保持代码的可扩展性。
5. **跨平台支持**:由于Selenium支持多种浏览器和操作系统,因此可以适应不同的开发环境和应用场景。
学习和使用Python与Selenium进行浏览器模拟操作,不仅能够提升爬虫的适应性和灵活性,还能锻炼开发者对HTML、JavaScript、CSS以及并发编程的理解和实践能力。然而,要注意尊重网站的robots.txt协议和使用规则,确保合法和合规的数据抓取。
Python使用使用Selenium模拟浏览器自动操作功能模拟浏览器自动操作功能
概述概述
在进行网站爬取数据的时候,会发现很多网站都进行了反爬虫的处理,如JS加密,Ajax加密,反Debug等方法,通过请求获取数据和页面展示的内容完全
不同,这时候就用到Selenium技术,来模拟浏览器的操作,然后获取数据。本文以一个简单的小例子,简述Python搭配Tkinter和Selenium进行浏览器的模
拟操作,仅供学习分享使用,如有不足之处,还请指正。
什么是什么是Selenium?
Selenium是一个用于Web应用程序测试的工具,Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10,
11),Mozilla Firefox,Safari,Google Chrome,Opera等。Selenium支持多种操作系统,如Windows、Linux、IOS等,如果需要支持Android,则需要
特殊的selenium,本文主要以IE11浏览器为例。
安装安装Selenium
通过pip install selenium 进行安装即可,如果速度慢,则可以使用国内的镜像进行安装。
涉及知识点涉及知识点
程序虽小,除了需要掌握的Html ,JavaScript,CSS等基础知识外,本例涉及的Python相关知识点还是蛮多的,具体如下:
Selenium相关:
Selenium进行元素定位,主要有ID,Name,ClassName,Css Selector,Partial LinkText,LinkText,XPath,TagName等8种方式。
Selenium获取单一元素(如:find_element_by_xpath)和获取元素数组(如:find_elements_by_xpath)两种方式。
Selenium元素定位后,可以给元素进行赋值和取值,或者进行相应的事件操作(如:click)。
线程(Thread)相关:
为了防止前台页面卡主,本文用到了线程进行后台操作,如果要定义一个新的线程,只需要定义一个类并继承threading.Thread,然后重写run方法即可。
在使用线程的过程中,为了保证线程的同步,本例用到了线程锁,如:threading.Lock()。
队列(queue)相关:
本例将Selenium执行的过程信息,保存到对列中,并通过线程输出到页面显示。queue默认先进先出方式。
对列通过put进行压栈,通过get进行出栈。通过qsize()用于获取当前对列元素个数。
日志(logging.Logger)相关:
为了保存Selenium执行过程中的日志,本例用到了日志模块,为Pyhton自带的模块,不需要额外安装。
Python的日志共六种级别,分别是:NOTSET,DEBUG,INFO,WARN,ERROR,FATAL,CRITICAL。
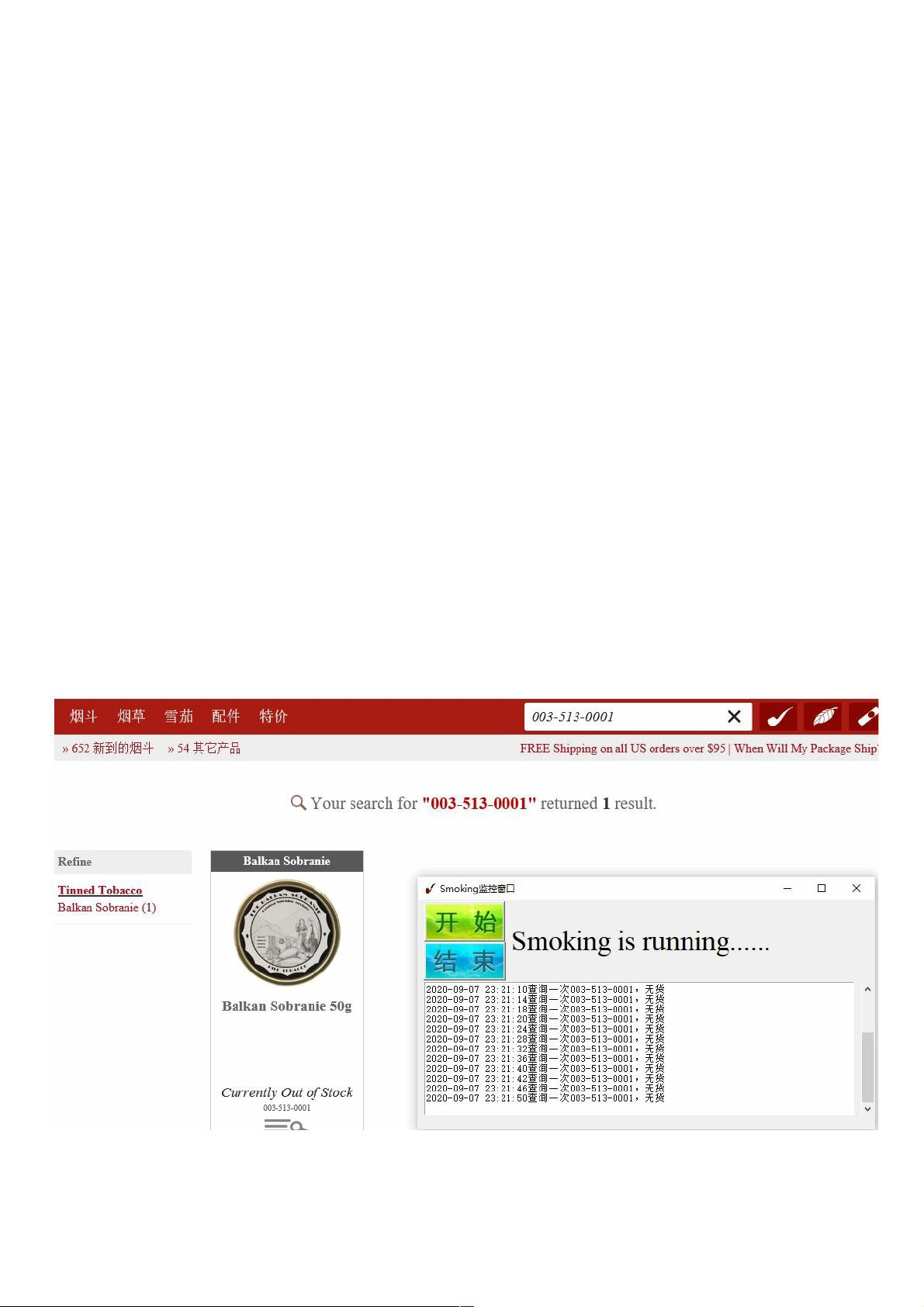
示例效果图
本例主要针对某一配置好的商品ID进行轮询,监控是否有货,有货则加入购物车,无货则继续轮询,如下图所示:
核心代码核心代码
本例最核心的代码,就是利用Selenium进行网站的模拟操作,如下所示:
class Smoking:
"""定义Smoking类"""
# 浏览器驱动
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-09-20 上传
点击了解资源详情
2024-11-05 上传

weixin_38670297
- 粉丝: 7
- 资源: 927
 我的内容管理
展开
我的内容管理
展开







