DATAX Linux安装教程:环境配置与开发实战
需积分: 50 88 浏览量
更新于2024-07-21
收藏 1.27MB DOCX 举报
本文档详细介绍了在Linux系统环境下安装和开发DATAX的过程。DATAX是一款由阿里巴巴开源的大规模数据迁移工具,主要用于Hadoop HDFS、MySQL等数据源之间的数据迁移。以下是主要内容的详细解读:
1. **DATAX安装步骤**:
- **源码下载**: DATAX的源代码可以从其官方SVN仓库获取,地址为http://code.taobao.org/svn/datax/trunk。开发者可以直接从这里获取最新版本的代码进行开发。
2. **安装前的环境配置**:
- **Java和Python环境**: DATAX主要使用Java和Python进行开发,因此确保安装机器上已安装Java 1.6及以上版本和Python 2.6或更高版本。可以通过命令行工具如`java -version`和`python --version`来检查。
- **Ant和Makefile支持**: DATAX使用ant+makefile进行编译和打包,所以需要确认系统中已安装ant和g++/gcc。可以通过`ant -version`和`gcc --version`来验证。
3. **Python和GCC的安装**:
- **GCC安装**: 在Linux系统中,推荐通过yum包管理器安装GCC,命令是`yum install gcc`。确保网络连接畅通。
- **Python 2.7.3安装**:
- 由于默认预装的Python版本可能过旧,推荐安装新版本Python 2.7.3。首先,访问Python官方网站下载源代码(http://www.python.org/download/),然后使用`tar-xzf Python-2.7.3.tgz`解压。接着切换到解压后的目录,运行`./configure`进行编译设置,生成Makefile。最后,执行`make`编译并安装,通过`make install`将可执行文件放入系统路径,便于所有用户使用。
总结,本文提供了一套完整的DATAX在Linux系统下的安装指南,包括源代码获取、依赖工具检查和安装,以及针对Python和GCC的特定配置步骤。这对于任何想要在Linux环境中使用DATAX进行大数据迁移的开发者来说,都是非常实用的参考资料。同时,文中还强调了环境兼容性,确保了开发过程的顺利进行。
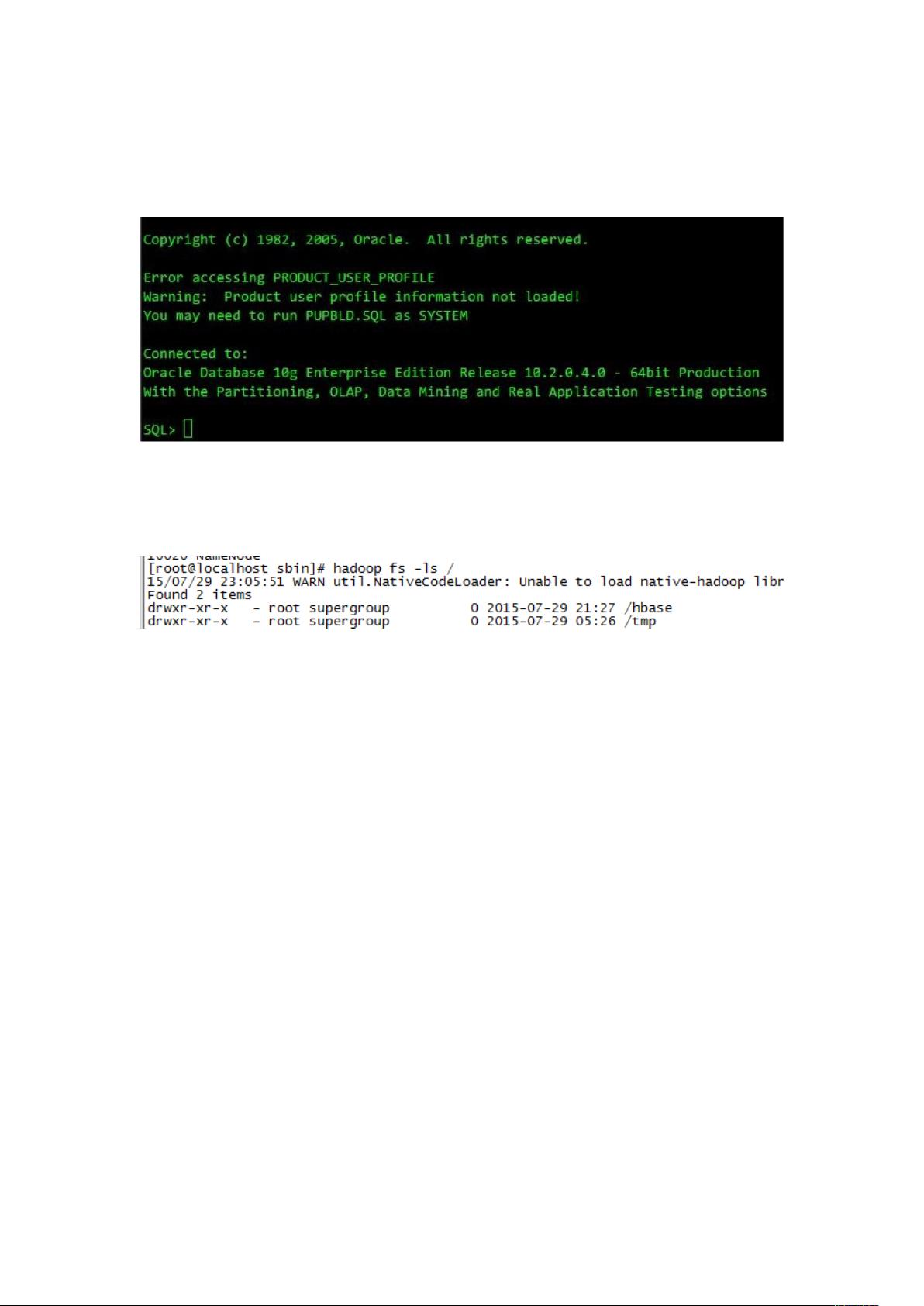
?(0(3 进行测试,如果能给正常启动 ?(0(3,并连接到目的数据库,表示
+,(& 客户端连接 *@。如下图:
() 如果使用的是 A-+.&+ 和 AB&&+,请确保安装 的机器已经安
装好 客户端,并能给正常访问 文件系统,测试命令如下图:
1.3 安装步骤
进入 的 +0$ 目录。 2+3%2+0$
在 + 下运行: +0$73.(CC7:0:4:&1.&0&,D会出现一顿 E.(&E3
问题,如下:

剩余32页未读,继续阅读
2019-07-19 上传
2022-02-17 上传
2019-07-09 上传
2023-05-08 上传
108 浏览量
2022-12-23 上传

qq_30155317
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
