视频超分辨率研究:多内存卷积神经网络方法
下载需积分: 9 | PDF格式 | 7.77MB |
更新于2024-07-10
| 159 浏览量 | 举报
"这篇研究论文提出了一种名为‘多内存卷积神经网络’的方法,用于视频超分辨率(Video Super-Resolution, VSR),旨在通过利用连续低分辨率(LR)帧之间的空间-时间互补信息,更好地重建高分辨率(HR)帧。传统基于卷积神经网络(CNN)的视频超分辨率方法通常采用直接连接和单一内存模块,而这限制了对LR帧之间信息的充分利用。论文中提出的多内存结构有望解决这一问题,增强视频恢复的细节和质量。"
在视频超分辨率领域,目标是将连续的低清晰度视频帧转化为高清晰度的图像序列。传统的视频超分辨率方法,尤其是基于卷积神经网络的,虽然在提升图像质量方面取得了一定成果,但它们通常只依赖单一的记忆单元来处理输入的低分辨率帧。这种方法忽略了连续帧之间丰富的空间和时间关联性。
多内存卷积神经网络(Multi-Memory Convolutional Neural Network, MMCNN)的创新之处在于引入了多个记忆模块,这些模块可以并行处理和整合来自不同时间步的LR帧的信息。这种设计使得网络能够捕获更复杂的时空模式,从而更有效地利用相邻帧间的相关性,提高超分辨率重建的准确性和细节保真度。
MMCNN的核心思想是通过多个内存模块的协作,增强模型对动态场景的理解和预测能力。每个内存模块可能具有不同的学习特性,例如专注于短期或长期的依赖关系,或者是捕捉特定的运动模式。通过这种方式,网络可以学习到更丰富的上下文信息,并在重建HR帧时避免信息丢失或模糊。
此外,论文还可能讨论了训练策略和损失函数的选择,以优化网络的性能。可能包括使用对抗性训练(Adversarial Training)来提高生成图像的逼真度,以及时间一致性损失(Temporal Consistency Loss)来确保超分辨率序列在时间上的连贯性。
这篇论文对视频超分辨率技术进行了重要的改进,提出了一个多内存架构,以增强CNN在处理连续帧时的空间和时间信息利用能力,从而提高视频恢复的质量。这一工作对于理解和改进深度学习在视频处理中的应用具有重要意义,并可能推动未来视频增强技术的发展。
1057-7149 (c) 2018 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2018.2887017, IEEE
Transactions on Image Processing
IEEE TRANSACTIONS ON IMAGE PROCESSING 3
came up with robust video super-resolution with learned tem-
poral dynamics (RVSR-LTD) [16], which creates a temporal
adaptive neural network to adaptively determine the optimal
scale of temporal dependencies. Even though, RVSR-LTD
learns from the structure of ESPCN [28] (a simple three-layer
convolution) to incorporate with the temporal adaptive neural
network, which limits its performance.
Above all, BRCN, VESPCN, VSRnet and RVSR-LTD only
use a simple and direct way of connection, thus resulting in
the shallow depth and simple structure of their underlying
networks. In addition, VESPCN, VSRnet and DRVSR take
pre-amplified images as inputs, so that magnified large im-
ages consume huge GPU memory and computational cost.
Therefore, it is urged to avoid these weaknesses and make
improvements to obtain more realistic image details.
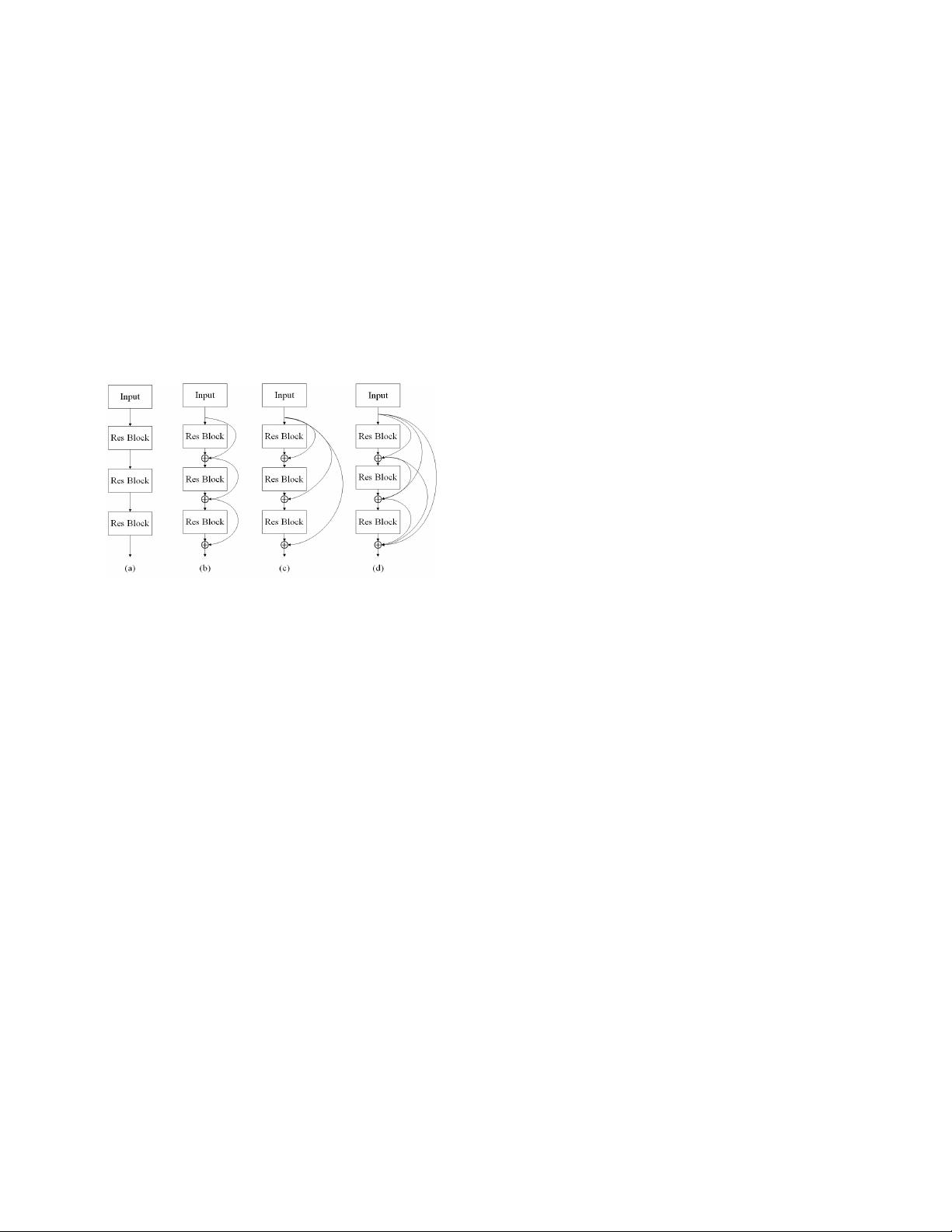
Fig. 1. Different skip connection schemes. (a) No skip connection. (b)
Distinct-source skip connection. (c) Shared-source skip connection. (d) Dense
skip connection.
C. Inter-layer Connection
How to design an effective network structure and improve
the stability of the model has always been a significant part
of neural network research. Recently, with the help of skip
connection [34], [35], the popularity of deep neural networks
has revived again. As shown in Figure 1, different skip con-
nection schemes have been proposed to form the deep neural
networks. Resnet [35] uses bypassing path between layers to
effectively train networks with more than 100 layers. Huang
et al. [36] randomly dropped layers to improve the training
of deep residual networks, which demonstrates the fact that
there exists a great amount of redundancy in deep residual
networks. DenseNet [37] links all layers in the networks and
attempts to fully explore the advantages of skip connections.
Further, these ideas have been tailored to support SISR and
video SR. For instance, instead of learning to reconstruct HR
image directly, VDSR [24] adopts one skip connection to learn
the residual image, and adds it to the bicubic amplified LR
image to obtain the SR image. Tong et al. [38] and Zhang et
al. [30] both adopted dense skip connections in their network
for SISR, and achieved promising results.
III. OUR METHOD
In this section, we present the design methodology for the
proposed MMCNN network, including the whole architecture
and details about individual modules.
A. Architecture
As shown in Figure 2, our model consists of two parts:
optical flow network and image-reconstruction network. Video
SR model aims to estimate one HR frame from a serial
of adjacent LR frames, and we therefore use the optical
flow network to estimate the motion between current frame
and the reference frame above all. Then, we use the optical
flow for motion compensation and transforming the input
LR frames into warped frames. After that, we send these
warped frames to the image-reconstruction network, which
is further composed of 4 modules: feature extraction, multi-
memory detail fusion, feature reconstruction and sub-pixel
magnification. We elaborate these modules in the following
respectively.
B. Motion Estimation and Compensation
Motion estimation and compensation are widely studied
for video processing. Jaderberg et al. proposed a spatial
transformer networks [39], which is a differentiable module
and can be used to spatially transform feature maps. In video
SR, motion estimation and compensation are mainly adopted
to represent the temporal correlations among consecutive LR
frames. Joint motion compensation for SR with neural net-
works has also been studied through recurrent bidirectional
networks [18], [21], [22]. A motion compensation scheme
based on spatial transformers has been designed [21], which
is combined with spatio-temporal models to enable a very
efficient solution for video SR. In general, a motion estimation
module takes two frames as inputs and produces an optical
flow vector field as follows:
F
i→j
= (u
i→j
, v
i→j
) = M E(I
i
, I
j
; θ
ME
), (1)
where F
i→j
denotes the optical flow field generated from input
frame I
i
to I
j
, M E(·) is the operator for calculating optical
flow, and θ
ME
is the parameter for operator M E(·).
We have tested Flownet [40] and its improved versions like
Flownet-SD [41] and Flownet2 [42]. However, these networks
have large number of parameters and heavy computational
cost. Thus, we choose the motion compensation transformer
operator (MCT) [21] as [22] does, which is easier to be trained
and makes it possible for us to train both the optical flow
network and the image-reconstruction network simultaneously.
For motion compensation, it is used for spatial alignment,
whose process can be described as:
J = M C(I, F ; θ
MC
), (2)
where J denotes the warped image, MC(·) is the operator
for motion compensation, I represents the input image, F
stands for the optical flow field, and θ
MC
is the parameter
for operator M C(·).
Based on spatial transformer network [39], Caballero et
al. [21] proposed a multi-scale spatial transformer motion
compensation method, which extracts the optical flow in a
coarse-to-fine manner. Further, Tao et al. [22] proposed a
SPMC layer, which projects the compensated frame from LR
space to HR space. We have tested these two methods and
decide to adopt MC from VESPCN [21], which shows a little
剩余14页未读,继续阅读
相关推荐

191 浏览量

382 浏览量
379 浏览量

319 浏览量




weixin_38685876
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Openaea:Unity下开源fanmad-aea游戏开发
- Eclipse中实用的Maven3插件指南
- 批量查询软件发布:轻松掌握搜索引擎下拉关键词
- 《C#技术内幕》源代码解析与学习指南
- Carmon广义切比雪夫滤波器综合与耦合矩阵分析
- C++在MFC框架下实时采集Kinect深度及彩色图像
- 代码研究员的Markdown阅读笔记解析
- 基于TCP/UDP的数据采集与端口监听系统
- 探索CDirDialog:高效的文件路径选择对话框
- PIC24单片机开发全攻略:原理与编程指南
- 实现文字焦点切换特效与滤镜滚动效果的JavaScript代码
- Flask API入门教程:快速设置与运行
- Matlab实现的说话人识别和确认系统
- 全面操作OpenFlight格式的API安装指南
- 基于C++的书店管理系统课程设计与源码解析
- Apache Tomcat 7.0.42版本压缩包发布
