深入理解Hadoop YARN:监控与资源管理
39 浏览量
更新于2024-06-14
收藏 3.39MB PDF 举报
"Apache Hadoop YARN 是一种资源管理器,负责集群的统一管理和调度,为上层应用如 MapReduce 提供计算资源。YARN Web UI 提供了监控和管理应用的功能,包括 V1 和 V2 版本的界面,展示应用程序的状态、日志和集群配置。此外,JobHistoryServer 服务专门存储已完成 MapReduce 应用的历史信息,但不包含其他类型应用的历史。启用 JobHistoryServer 需配合日志聚合功能,以便于集中查看和管理日志。"
YARN,全称为 Yet Another Resource Negotiator,是 Hadoop 体系中的关键组件,它解决了早期 Hadoop 版本中 MapReduce 模型资源管理的局限性。YARN 不仅仅是一个调度器,更是一个全面的资源管理系统,能够有效地分配和管理集群的内存、CPU 等资源,提高了集群的利用率和整体性能。通过 YARN,开发者可以编写各种计算框架,而无需关心底层的资源调度,这极大地促进了 Hadoop 生态系统的多样化和扩展性。
YARN 的核心组成部分包括ResourceManager(RM)、NodeManager(NM)和 ApplicationMaster(AM)。ResourceManager 是全局的资源仲裁者,负责整个集群的资源分配和监控。NodeManager 是每个节点上的代理,管理该节点上的容器(Container),并向 RM 报告资源使用情况。ApplicationMaster 是每个应用的独有进程,负责与 RM 协商资源,以及监控和恢复应用的任务。
Web UI 服务是 YARN 的一个重要特性,提供了直观的界面来监控和管理 YARN 集群。V1 Web UI 提供了对应用程序、队列、节点等的详细信息,用户可以查看集群状态、应用日志和配置信息。V2 Web UI 在此基础上进行了改进,提供了更多可视化和交互功能,便于管理员进行故障排查和性能优化。
JobHistoryServer 是 YARN 中的一个重要服务,用于存储和检索已完成 MapReduce 任务的历史记录。当 JobHistoryServer 启动并配合日志聚合功能时,所有 Container 的运行日志会被集中存储,便于后期分析和审计。然而,需要注意的是,JobHistoryServer 只处理 MapReduce 应用的历史数据,Spark、Flink 等其他计算框架的应用历史需要通过各自的服务或工具来管理。
总结来说,Hadoop YARN 的监控和资源管理能力为大数据处理提供了强大的支撑,其 Web UI 和 JobHistoryServer 服务为管理和分析应用提供了便捷工具。通过理解和充分利用这些功能,可以更好地优化集群资源使用,提升大数据处理的效率和可靠性。
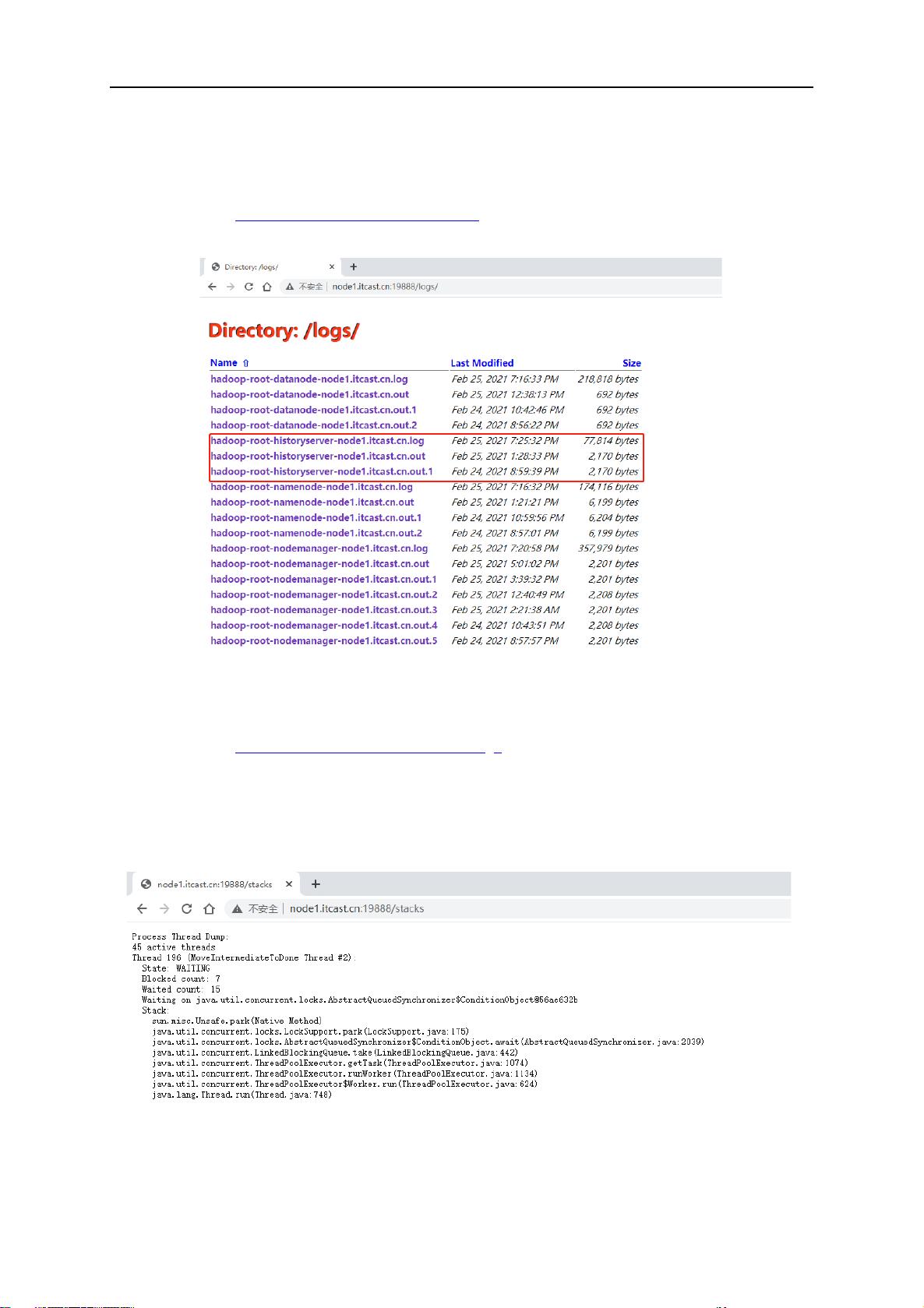
1.2.5.5 JHS 本地日志
浏览器输入 http://node1.itcast.cn:19888/logs/ 地址或点击页面左侧Tools栏目中的红线框
local logs链接会打开JHS服务的所在节点的log文件列表页面。
1.2.5.6 JHS 堆栈信息
浏览日输入 http://node1.itcast.cn:19888/stacks 地址或点击页面左侧Tools栏目中的红线框
Server stacks链接会打开JHS服务的堆栈转储信息。stacks功能会统计JHS服务的后台线程数、每个
线程的运行状态和详情。这些线程有MoveIntermediateToDone线程、JHS的10020 RPC线程、
JHS的10033 Admin接口线程、HDFS的StatisticsDataReferenceCleaner线程、JHS服务度量系统的
计时器线程、DN的Socket输入流缓存线程和JvmPauseMonitor线程等。
’

剩余73页未读,继续阅读
2023-05-19 上传
2021-06-02 上传
2024-04-10 上传
2022-11-21 上传
2019-04-03 上传
2013-11-17 上传
2018-05-10 上传
2018-06-09 上传

shandongwill
- 粉丝: 5951
- 资源: 676
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
