Apache Flink深度解析:从基础到实战
需积分: 0 193 浏览量
更新于2024-06-25
1
收藏 17.3MB PDF 举报
"Flink从入门到精通"
Apache Flink是一个强大的框架和分布式处理引擎,专门设计用于处理无界和有界数据流的有状态计算。它起源于2008年的柏林理工大学研究项目Stratosphere,并在2014年进入Apache孵化器,同年12月成为Apache软件基金会的顶级项目。随着时间的发展,Flink经历了多次重要版本更新,其中2015年的0.9版本是一个里程碑。2019年,阿里巴巴收购了Flink相关产品的公司,并在同年8月将其内部优化版Blink开源,整合进Flink 1.9.0版本。
Flink在各种行业中都有广泛应用,包括电商行业的实时报表、广告投放、实时推荐;物流配送中的订单状态跟踪和信息推送;物联网领域的实时数据采集和实时报警;以及金融行业的实时结算和风险检测等。教育、政务、旅游、保险、医疗、社交和服务等行业也广泛受益于Flink的实时处理能力。
数据处理框架经历了从传统的事务处理和分析处理到有状态的流处理的演变。在流处理领域,最初出现了Lambda架构,它使用两套系统,即批处理层和流处理层,以平衡实时性和准确性。批处理层确保数据准确,而流处理层则提供实时结果,但可能不够精确。随后,Kappa架构提出,主张仅使用流处理层,强调事件驱动的实时计算,简化了系统架构。
流处理的应用场景非常广泛,包括事件驱动的应用程序,这类应用程序能够响应来自一个或多个事件流的事件,进行计算、状态更新或外部操作。此外,流处理还涵盖了批处理和流式分析,前者通过对有限数据集进行批量处理,后者则允许对单个或小批量数据即时分析,两者都可用于数据洞察的提取。
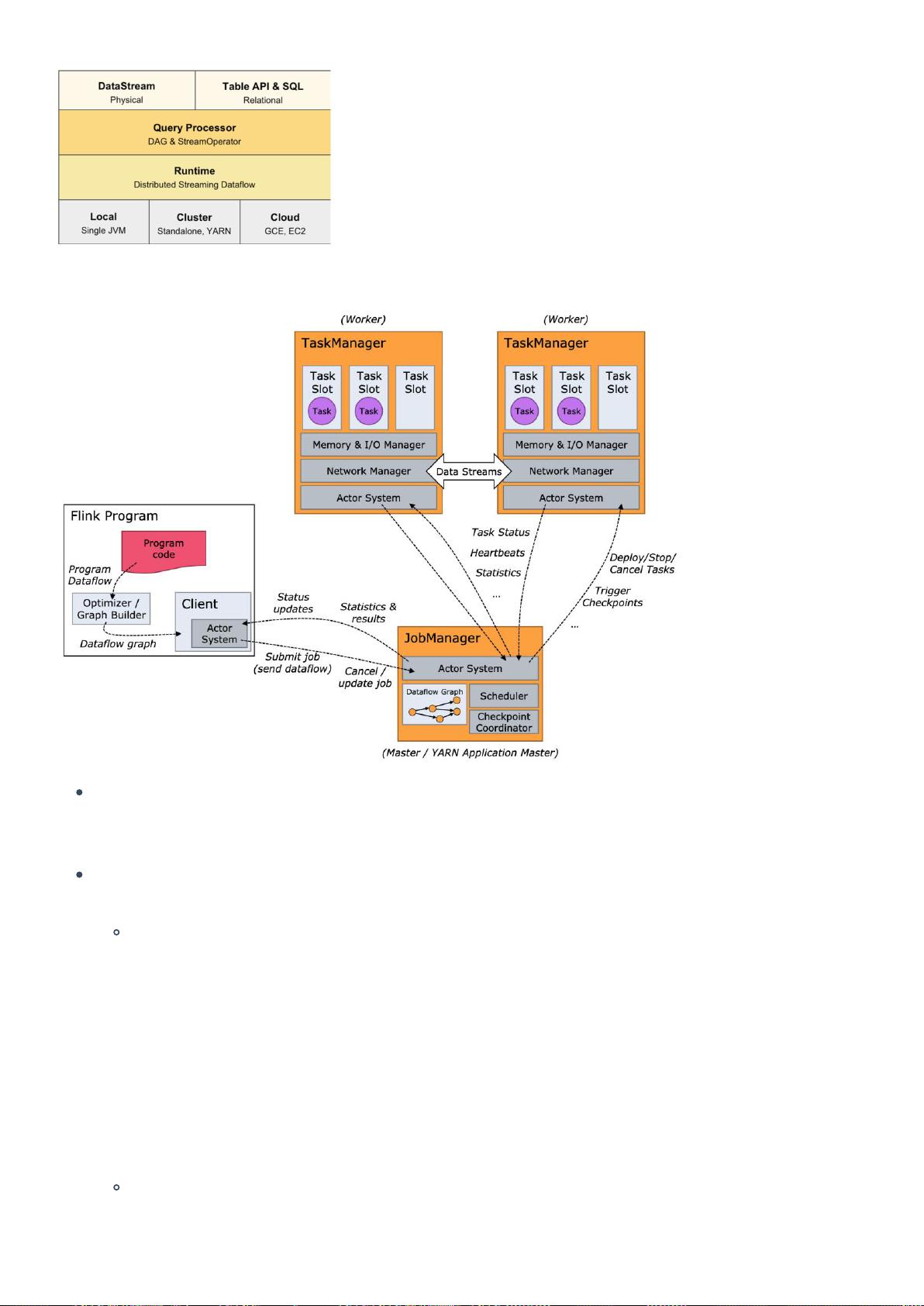
Flink的关键特性在于其高效的状态管理、事件时间处理和容错机制,使得它在实时数据处理领域独树一帜。它的API支持Java和Scala,同时也提供了SQL接口,方便开发者进行流处理和批处理作业的编写。Flink的并行执行模型和低延迟特性使其能够在大数据实时分析中表现出色,为业务决策提供实时、准确的数据支持。
可看到端⼝已打开,占⽤进程号为4047。使⽤ kill 命令关闭。
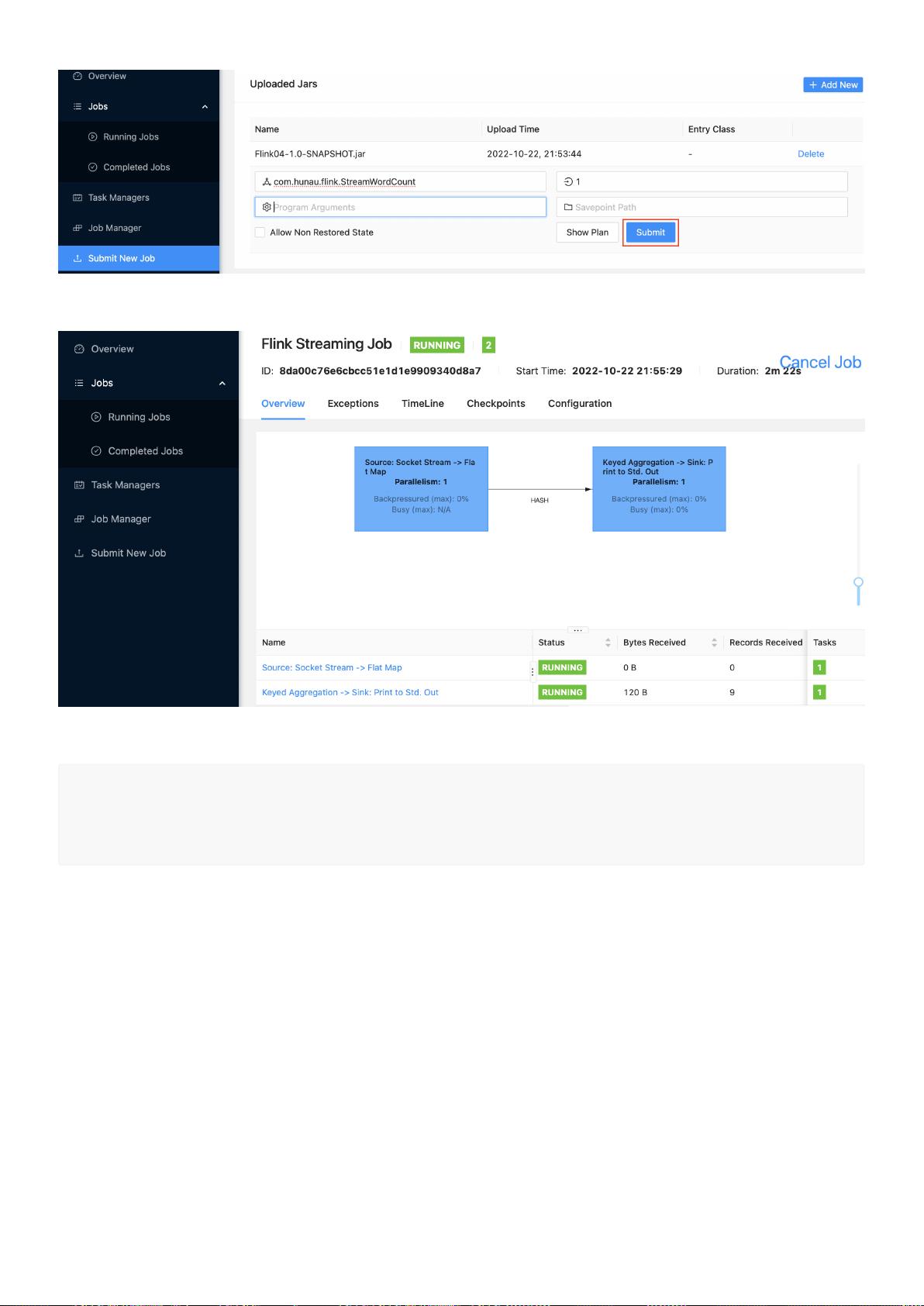
3.5 流处理扩展
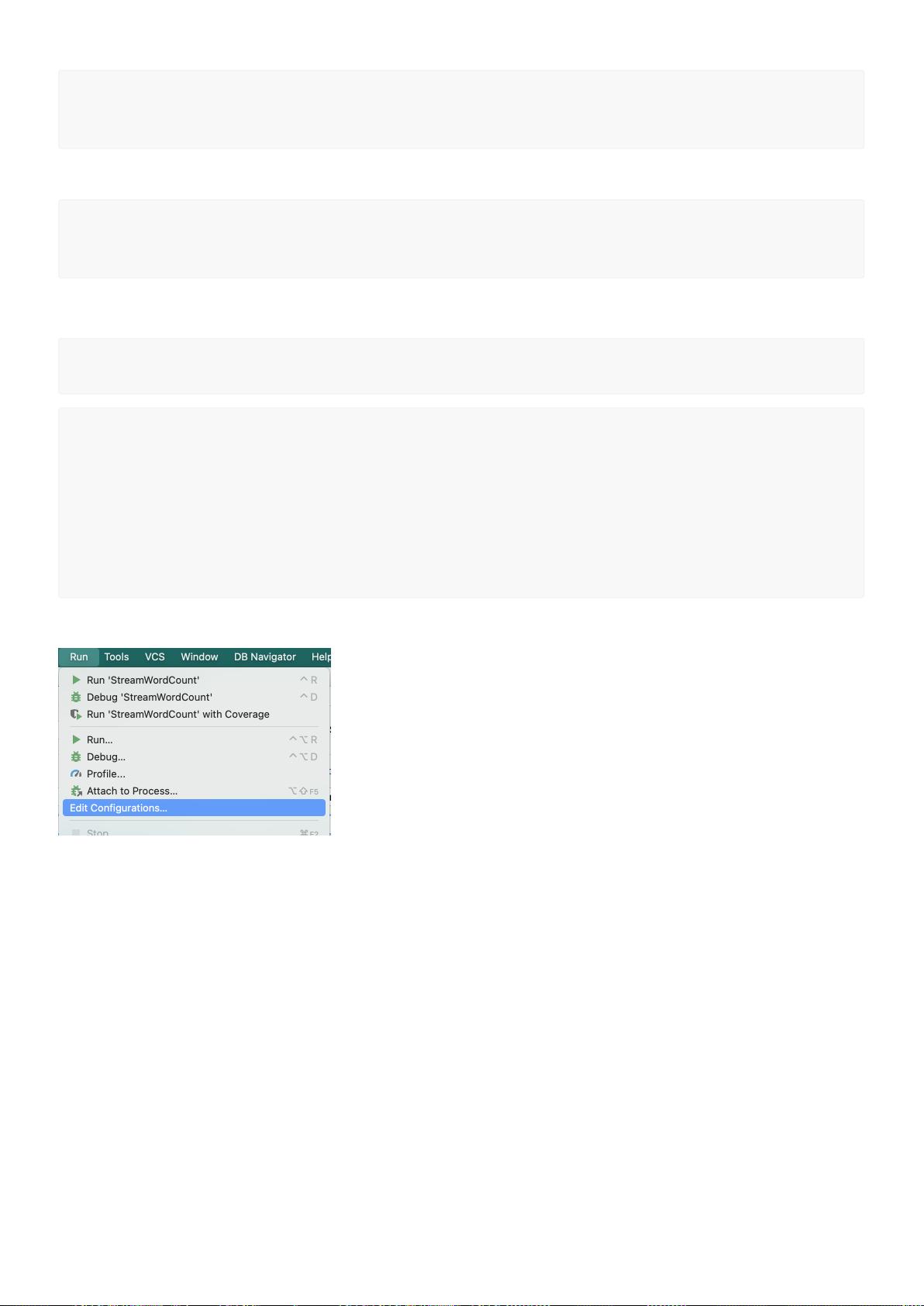
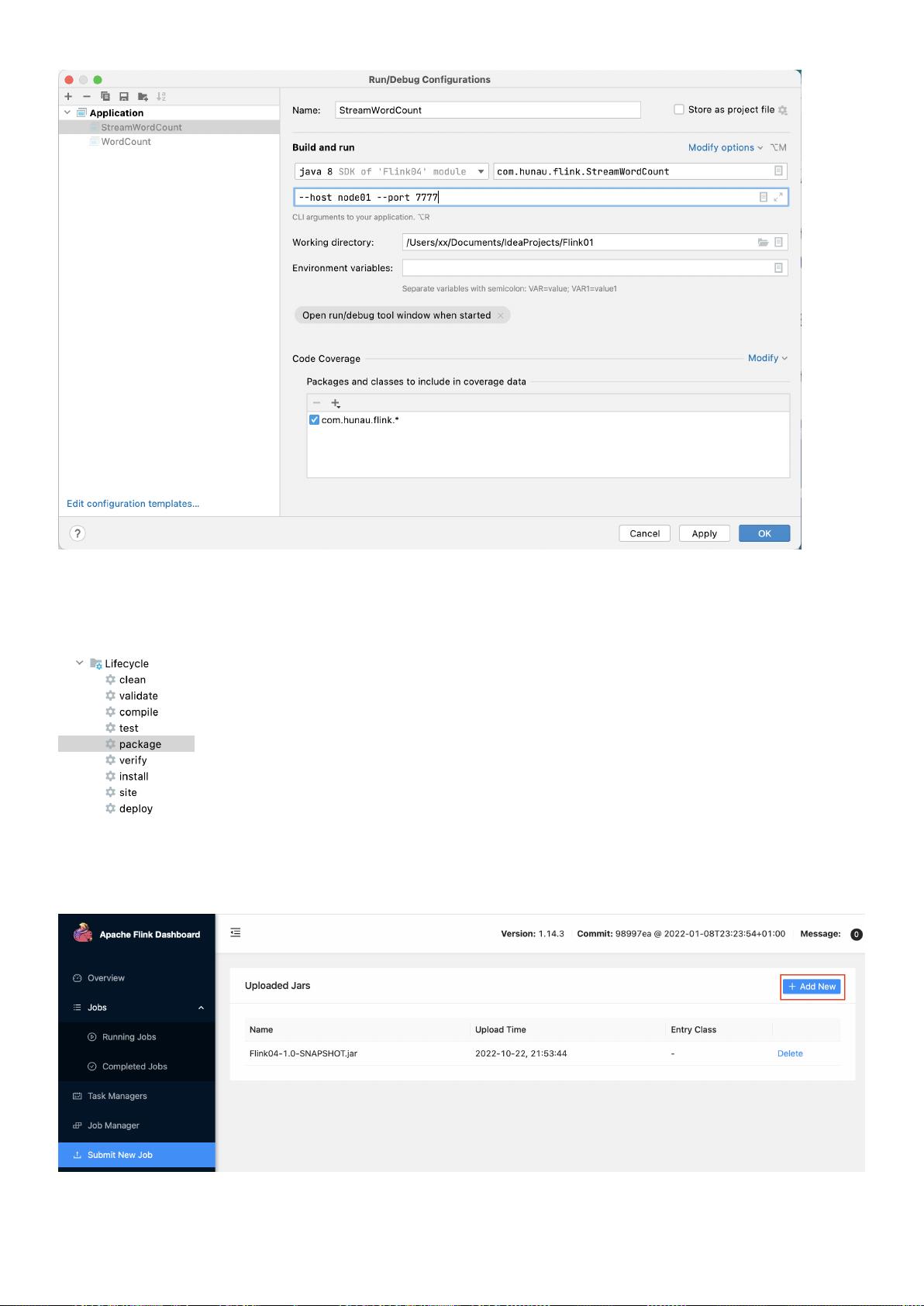
点击 "Run——> Edit Configurations...",设置参数:--port node01 --port 7777
[root@node01 ~]# netstat -anp | grep 7777
tcp ! ! ! !0 ! ! !0 0.0.0.0:7777 ! ! ! ! ! !0.0.0.0:* ! ! ! ! ! ! ! LISTEN ! ! !4047/nc
tcp6 ! ! ! 0 ! ! !0 :::7777 ! ! ! ! ! ! ! ! :::* ! ! ! ! ! ! ! ! ! LISTEN ! ! !4047/nc
[root@node01 ~]# kill -9 4047
[root@node01 ~]# netstat -anp | grep 7777
[1]+ 已杀死 ! ! ! ! ! ! ! nc -lk 7777
// 并⾏度
env.setParallelism(8);
// 从外部命令中提取参数,作为socket的主机名和端⼝号
import org.apache.flink.api.java.utils.ParameterTool;
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
int port = parameterTool.getInt("port");
DataStreamSource<String> dataStreamSource = env.socketTextStream(host, port);

剩余214页未读,继续阅读
390 浏览量
215 浏览量
1099 浏览量
2025-02-07 上传
220 浏览量
1051 浏览量

Xuzixuan的博客
- 粉丝: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- Unicode编码详解与应用
- Rational ClearQuest 使用手册:缺陷追踪与管理指南
- IPTV关键技术与标准探索:编码、DRM、CDN与更多
- Jboss EJB3.0 实战教程:从入门到精通
- Windows API实现USB设备插拔检测
- Windows API 完整指南:函数详解与应用
- Spring开发指南(0.8版):开源文档详解与实战教程
- VisualC++入门教程:基于实例的学习
- 使用Struts2+Hibernate3+Spring2开发J2EE实战教程
- Windows XP Service Pack 3详解:更新与部署指南
- 提升英文网站流量的20种策略
- Oracle9i数据库管理基础入门
- 解决AJAX中文乱码问题
- ERP项目实施规划:目标、进度、资源配置的系统安排
- VC++串口通信实现与Windows API应用
- Head First EJB:轻松学习企业JavaBean
