CUDA编程指南2.2.1:NVIDIA并行计算架构解析
"NVIDIA CUDA Programming Guide 2.2.1.pdf"
CUDA是NVIDIA推出的一种并行计算架构,用于将GPU(图形处理器)转变为通用的并行计算平台。这份编程指南介绍了如何利用CUDA进行高性能计算,适用于版本2.2.1。
1. **引言**
- **从图形处理到通用并行计算**: 在传统的计算机系统中,GPU主要用于图形渲染,但CUDA扩展了其功能,使之能执行复杂的数学和科学计算任务。
- **CUDA架构**: CUDA提供了一个通用的并行计算环境,允许开发者利用GPU的大量计算核心进行数据并行处理。
2. **CUDA编程模型**
- **内核(Kernels)**: 内核是CUDA程序的核心,它是在GPU上执行的函数,可以并行处理大量数据。
- **线程层次(Thread Hierarchy)**: 线程层次包括线程块和线程网格,线程块内的线程可以协作,并且整个计算可以由多个线程网格并行执行。
- **内存层次(Memory Hierarchy)**: 包括全局内存、共享内存、纹理内存和页锁定的主机内存,它们各自有不同的访问速度和用途。
- **主机与设备**: CUDA程序可以在主机(CPU)和设备(GPU)之间交互,通过复制数据和调度任务来实现计算的加速。
- **计算能力(Compute Capability)**: 定义了GPU支持的特性级别,如并发执行能力、纹理单元数量等。
3. **编程接口**
- **NVCC编译器**: CUDA程序需要通过NVCC编译器进行编译,它能够理解C++语法以及CUDA特定的扩展。
- **__noinline__**: 这个关键字告诉编译器不要内联指定的函数,这在某些情况下可以优化代码。
- **#pragma unroll**: 这个预处理指令用于控制循环展开,以提高效率或减少编译器不确定性。
- **C for CUDA**:CUDA编程语言基于C/C++,并添加了对GPU编程的支持。
- **设备内存**: GPU的全局内存用于存储所有线程的数据,可跨线程块访问。
- **共享内存**: 位于线程块内的线程可以高速访问的内存,用于线程间的协作。
- **多设备支持**: CUDA允许在多个GPU上并行运行计算任务,以实现更高的并行度。
- **纹理内存**: 优化了浮点数据的读取,特别适合于连续的、不频繁修改的数据访问。
- **纹理引用声明**: 定义纹理对象及其属性,如过滤模式和坐标空间。
- **运行时纹理引用属性**: 动态设置纹理对象的属性,如地址模式和过滤选项。
- **纹理绑定**: 将数据缓冲区绑定到纹理对象,以利用纹理内存的特性。
- **页锁定的主机内存**: 可以直接被GPU访问的主机内存,提高了数据传输速度。
- **可移植内存**: 页锁定的主机内存可以在不同设备间共享,无需再次复制。
- **写结合内存**: 优化了向GPU写入数据的性能。
- **映射内存**: 通过映射操作,使得GPU和CPU可以直接访问同一段内存,简化了数据交换。
- **异步并发执行**: CUDA支持在多个流(Stream)中并发执行任务,这些任务可以重叠计算和数据传输,提高了效率。
这份文档详细阐述了CUDA编程的关键概念、模型和接口,是开发CUDA应用程序的基础教程。通过学习和理解这些内容,开发者可以有效地利用GPU的强大计算能力,解决高性能计算问题。

Chapter 2. Programming Model
8 CUDA Programming Guide Version 2.2.1
}
Each of the threads that execute VecAdd() performs one pair-wise addition.
2.2 Thread Hierarchy
For convenience, threadIdx is a 3-component vector, so that threads can be
identified using a one-dimensional, two-dimensional, or three-dimensional thread
index, forming a one-dimensional, two-dimensional, or three-dimensional thread
block. This provides a natural way to invoke computation across the elements in a
domain such as a vector, matrix, or field. As an example, the following code adds
two matrices A and B of size NxN and stores the result into matrix C:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
// Kernel invocation
dim3 dimBlock(N, N);
MatAdd<<<1, dimBlock>>>(A, B, C);
}
The index of a thread and its thread ID relate to each other in a straightforward
way: For a one-dimensional block, they are the same; for a two-dimensional block
of size (D
x
, D
y
), the thread ID of a thread of index (x, y) is (x + y D
x
); for a three-
dimensional block of size (D
x
, D
y
, D
z
), the thread ID of a thread of index (x, y, z) is
(x + y D
x
+ z D
x
D
y
).
Threads within a block can cooperate among themselves by sharing data through
some shared memory and synchronizing their execution to coordinate memory
accesses. More precisely, one can specify synchronization points in the kernel by
calling the
__syncthreads() intrinsic function; __syncthreads() acts as a
barrier at which all threads in the block must wait before any is allowed to proceed.
Section 3.2.2 gives an example of using shared memory.
For effi
cient cooperation, the shared memory is expected to be a low-latency
memory near each processor core, much like an L1 cache,
__syncthreads() is
expected to be lightweight, and all threads of a block are expected to reside on the
same processor core. The number of threads per block is therefore restricted by the
limited memory resources of a processor core. On current GPUs, a thread block
may contain up to 512 threads.
However, a kernel can be executed by multiple equally-shaped thread blocks, so that
the total number of threads is equal to the number of threads per block times the
number of blocks. These multiple blocks are organized into a one-dimensional or
two-dimensional grid of thread blocks as illustrated by Figure 2-1. The dimension of
the grid is specified by
the first parameter of the
<<<…>>> syntax. Each block
within the grid can be identified by a one-dimensional or two-dimensional index


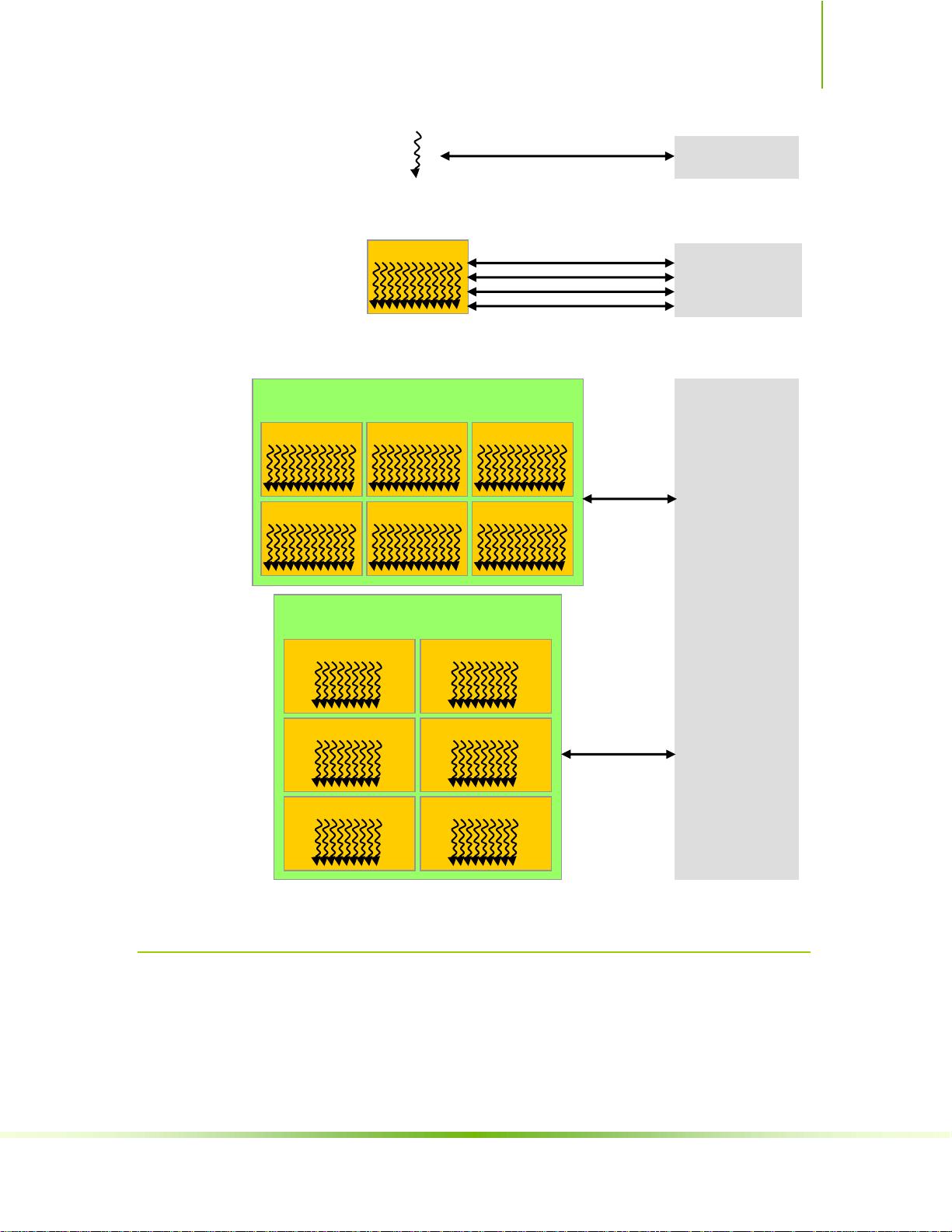

剩余138页未读,继续阅读
2022-09-14 上传
2022-09-21 上传
2024-11-26 上传
2024-11-26 上传
2024-11-26 上传
2024-11-26 上传
2024-11-26 上传

downloadasd
- 粉丝: 1
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
