《模式识别》第四讲:数据聚类的数学定义与应用
版权申诉
105 浏览量
更新于2024-06-22
收藏 2.74MB PDF 举报
在《模式识别》讲义2011版的第四讲——数据聚类部分,我们探讨了数据聚类这一关键的无监督学习方法。数据聚类是机器学习中的一种基本技术,它不同于分类任务,后者通常涉及预先定义好的类别标签。数据聚类的目的是根据样本之间的相似性,将数据集自动划分为若干个类别,使得内部的样本尽可能相似,而不同类别的样本之间差异较大。
聚类过程的核心在于寻找数据内在的结构和组织,而不依赖于预先确定的类别。它通常用于发现数据的潜在群体或模式,例如,农场中的柠檬分级和市场上的水果分类,虽然目的相同,但方法不同,农场用孔板法代表的是线性分类,而商家则是基于相似度将水果聚类。
数据聚类的准确定义指出,给定一组N个样本,将其划分为k个决策区域Si,每个区域内的样本相似度较高,且彼此互不重叠。这个过程要求样本只能属于一个类别,而非多个。这种划分过程遵循“人以类聚,物以群分”的哲学思想,源自古代中国的《周易·系辞传》。
聚类过程中面临的一个关键问题是确定样本相似性的阈值,即何时将两个样本视为同一类别。通常,相似度标准由领域专家或通过算法自适应地确定,比如基于距离度量(如欧氏距离、余弦相似度等)或者基于概率模型(如K-means或层次聚类)。
此外,值得注意的是,数据聚类并非对单个样本的识别,而是对整体样本集的全局操作。这意味着聚类结果往往是一个关于数据分布的整体视角,而不是个体特征的精确预测。通过数据聚类,我们可以发现数据的内在规律和结构,这对于数据分析、市场细分、图像处理、生物信息学等多个领域都具有重要意义。
数据聚类是机器学习和数据分析中的重要工具,它通过对样本相似性的度量,帮助我们在没有预先设定类别的情况下理解数据,并挖掘其中的潜在模式。在实际应用中,选择合适的聚类算法和评估指标对于获取准确的结果至关重要。
《模式识别》讲义 2011 版:第四讲 数据聚类
第 4 页
自动化学院 模式识别与智能系统研究所
高琪 gaoqi@bit.edu.cn
聚类也常常在各种数据处理的任务中,用来大幅度减少样本集中的样本
数量,用典型的样本来代替非典型的样本,以大大降低问题求解的复杂度
数据聚类的具体应用领域非常广泛:在经济领域可用于对客户进行分类,发
现最优价值的客户群;在信息检索领域可用于合并相似检索结果,减少检索返回
量;在生物领域可以用于基因分析和生物的分类;在数据处理领域可以用于对遥
感图像进行分析,或者从数据库中的大量数据中挖掘知识。
思考:
你能找到数据聚类在社会生活中的更多应用实例吗?
4、 数据聚类的过程
对于完整的数据聚类过程,一般包括以下这些步骤:
(1) 选取特征
特征的选取是聚类首先要确定的问题,因为样本集中的样本可能具有维度数
量巨大的不同特征,而选择哪些特征作为聚类特征来使用,会直接影响到聚类的
结果。
具体来说,聚类中特征的选择,要考虑以下的一些因素:
聚类任务的需求
选择特征的首要因素是聚类任务自身的需求,也就是说,哪些特征是任
务本身所关注的。
特征对聚类的有效性
其次是要在特征中选择对聚类最有效的那些特征,要使得采用这些特征
完成聚类后,聚类的结果比较理想。
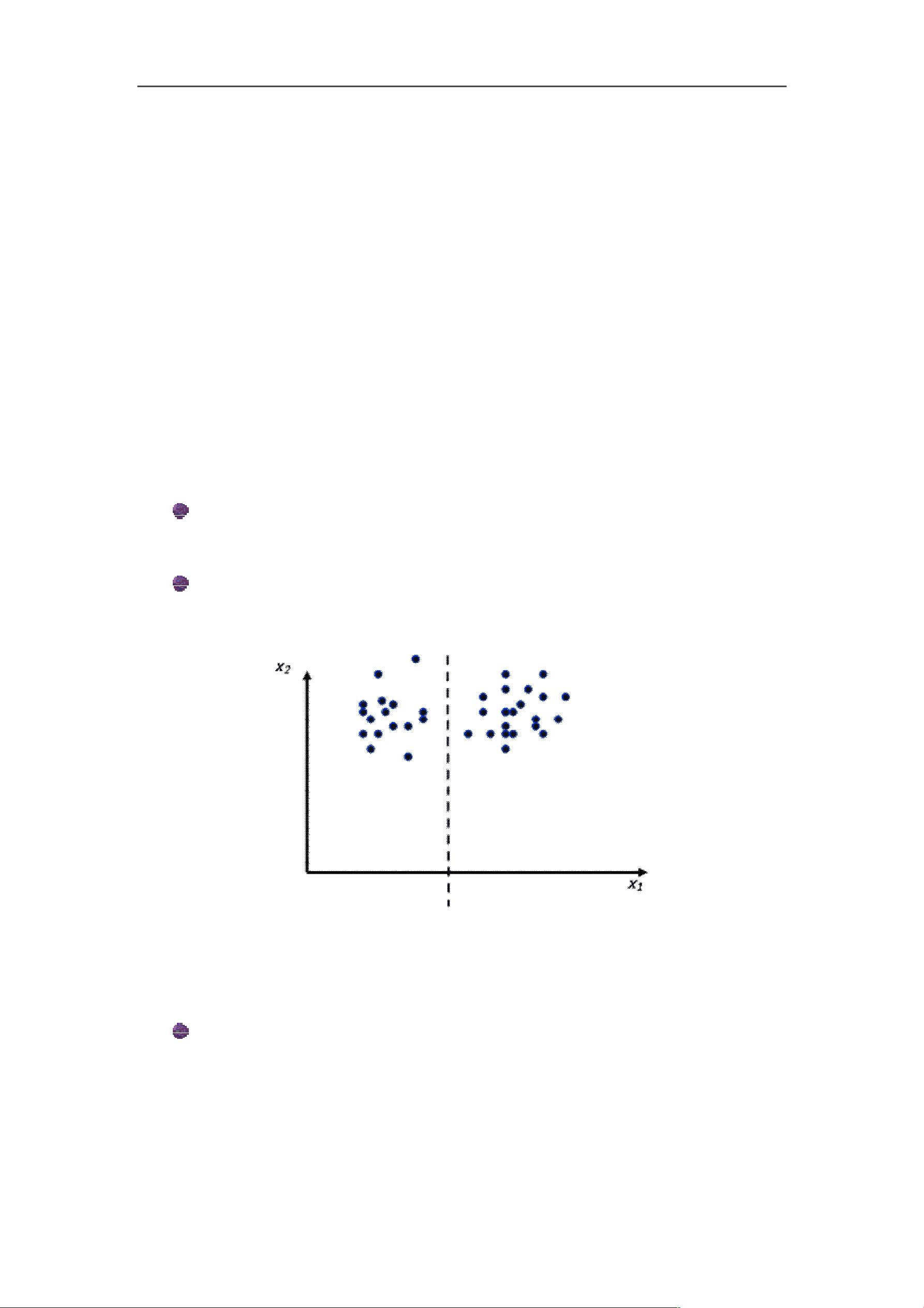
图 4 特征对聚类的有效性
在上例中,显然只选择特征 x
1
就可以完成聚类,而特征 x
2
不仅对聚类
是无用的,甚至是有害的。
维度和算法效率
最后还要考虑特征的数量和计算复杂度。尽量减少维度,提高聚类算法
的效率,是特征选择中必须重视的一个问题。
(2) 确定相似性度量标准
聚类中第二个步骤,是确定相似性的度量标准。
剩余19页未读,继续阅读
2022-11-26 上传
2023-02-20 上传
2023-04-01 上传
2023-03-22 上传
2022-07-09 上传
2022-06-26 上传

hhappy0123456789
- 粉丝: 72
- 资源: 5万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
