利用全局-局部上下文的零样本指代图像分割
需积分: 5 53 浏览量
更新于2024-06-19
收藏 34.03MB PPTX 举报
"这篇PPT讨论了一种名为'Zero-shot RIS with Global-Local Context Features'的方法,旨在解决无样本参照图像分割问题。利用CLIP的预训练跨模态知识,该方法无需额外标注数据即可实现高效分割。"
在计算机视觉领域,参照图像分割(Referencing Image Segmentation, RIS)是一项挑战性的任务,它要求根据描述性语言来定位并分割图像中的特定区域。然而,收集带有精确标注的RIS数据集是极其困难的。为了应对这一挑战,这篇论文提出了一个创新的零样本(Zero-shot)RIS方法,它依赖于 Contrastive Language-Image Pre-training (CLIP) 模型的先验知识。
CLIP模型因其强大的零样本迁移能力而知名,但通常不适用于像目标检测和实例分割这样的密集预测任务。由于RIS任务对目标区域的精确语言描述和对应的分割掩码注释有很高要求,因此直接应用CLIP会面临困难。已有的一些弱监督RIS方法虽试图减轻这个问题,但依然需要大量的图像-文本对注释,并且性能上往往逊色于全监督方法。
论文的主要贡献包括:
1. 首次提出了基于CLIP的零样本RIS框架,无需针对RIS任务进行额外的模型训练。
2. 设计了一个结合全局-局部上下文的视觉编码器,能捕捉到图像中的全局结构和局部细节信息。
3. 提出的全局-局部文本编码器则能编码句子的整体语义以及目标名词短语的局部特征,有助于理解文本描述与图像内容的关系。
4. 实验证明,这种方法在性能上超越了多种基线模型和弱监督RIS方法。
整体框架中,输入图像和表达式首先通过mask proposal技术提取全局-局部的视觉特征和文本特征。接着,通过计算这些特征之间的余弦相似度,选取得分最高的掩码作为分割结果。这种方法的关键在于,在一个共享的嵌入空间中学习图像和文本的表示,使得两者能够有效地相互对应,即便没有直接的匹配训练数据。
这篇论文展示了如何巧妙地利用预训练模型,如CLIP,解决RIS的标注数据难题,为无监督或弱监督的图像理解开辟了新的可能性,尤其是在减少对大量人工标注依赖的情况下,仍能实现高效的图像分割。
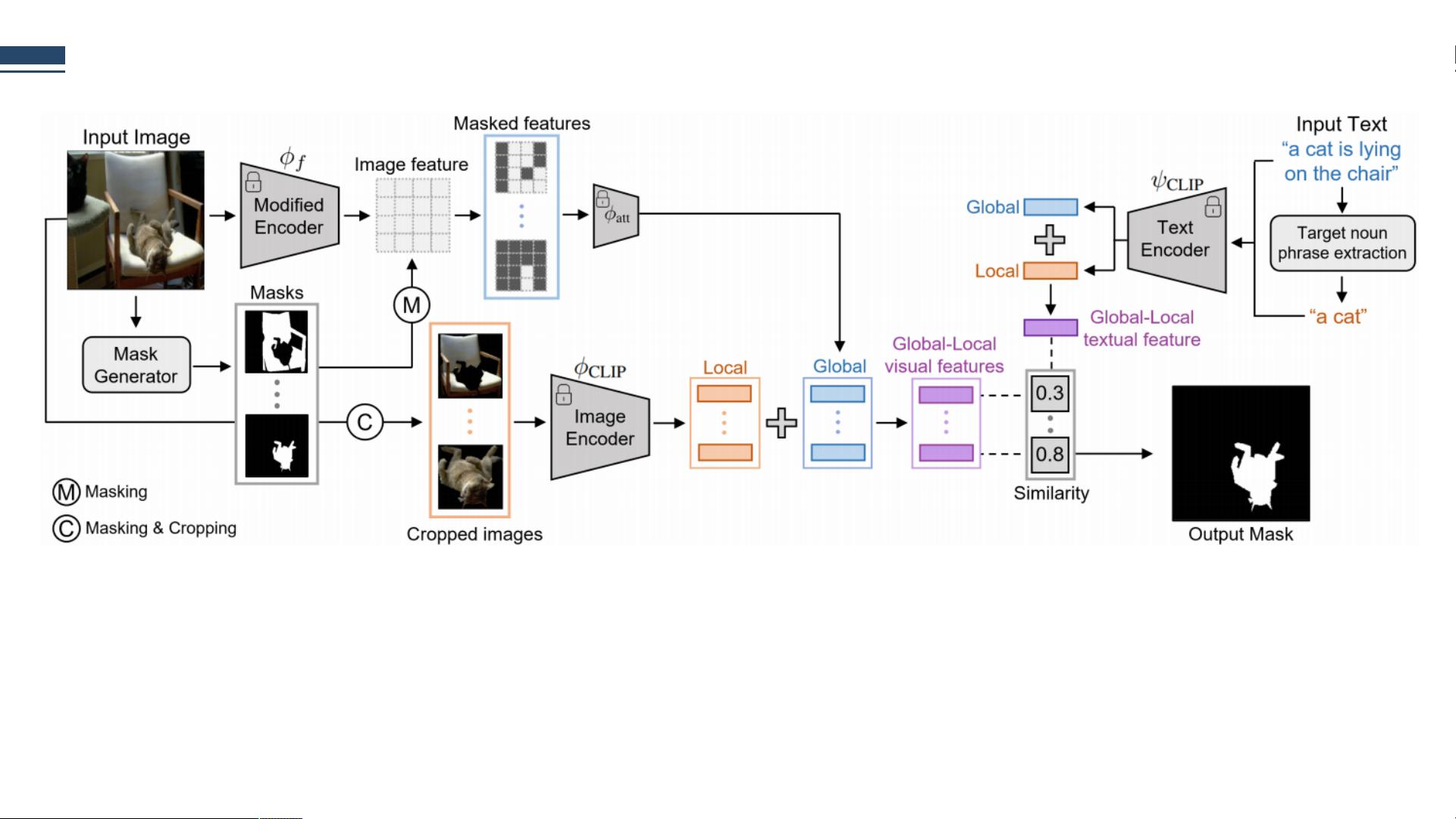
Overall Framework
图:global-local CLIP。给定一幅图像和一个表达式作为输入,我们使用mask proposal提取全局-局部上下文视觉特征,同时提
取全局-局部上下文文本特征。在计算所有全局-局部上下文视觉特征和一个全局-局部上下文文本特征之间的余弦相似度得分
后,我们选择得分最高的掩码。
剩余24页未读,继续阅读
2021-06-27 上传
2024-06-15 上传
2021-05-26 上传
2021-04-29 上传
2021-03-01 上传
2021-04-15 上传
2021-05-29 上传

安冉冉
- 粉丝: 306
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- IPQ4019 QSDK开源代码资源包发布
- 高频组电赛必备:掌握数字频率合成模块要点
- ThinkPHP开发的仿微博系统功能解析
- 掌握Objective-C并发编程:NSOperation与NSOperationQueue精讲
- Navicat160 Premium 安装教程与说明
- SpringBoot+Vue开发的休闲娱乐票务代理平台
- 数据库课程设计:实现与优化方法探讨
- 电赛高频模块攻略:掌握移相网络的关键技术
- PHP简易简历系统教程与源码分享
- Java聊天室程序设计:实现用户互动与服务器监控
- Bootstrap后台管理页面模板(纯前端实现)
- 校园订餐系统项目源码解析:深入Spring框架核心原理
- 探索Spring核心原理的JavaWeb校园管理系统源码
- ios苹果APP从开发到上架的完整流程指南
- 深入理解Spring核心原理与源码解析
- 掌握Python函数与模块使用技巧
