K8S集群问题排查与解决关键技巧
需积分: 5 193 浏览量
更新于2024-08-03
收藏 278KB DOCX 举报
Kubernetes (K8S) 集群问题排查和解决是确保其高效运行的关键。首先,理解K8S的基本架构至关重要,包括master节点(控制节点,负责集群管理和资源调度)和worker节点(计算节点,运行Pod的实例),以及Pod(最小的可调度单位,包含一个或多个容器)、Service(提供对外服务的抽象)等组件的协作。每个组件的正常运行依赖于它们的职责划分和交互。
在排查问题时,监控和日志是核心手段。通过监控系统(如Prometheus和Grafana),可以实时跟踪CPU、内存、网络流量等指标,识别是否存在性能瓶颈或资源耗尽的问题。同时,查看Pod和节点的日志,如通过kubectl logs命令,可以帮助定位代码错误、配置问题或者资源分配不当等问题。
网络通信是另一个关键领域,常见的问题有Pod间通信故障、Service内部和服务间通信障碍,甚至跨集群通信。网络抓包工具如Wireshark能帮助分析数据包,查找可能的网络瓶颈或异常。DNS问题也不容忽视,检查Coredns或其他DNS服务的运行状态,确保服务名称解析无误。
针对具体问题,当遇到Pod启动异常或节点无法启动Pod的情况,应考虑资源过剩、内存/CPU超限、网络问题(如Calico网络插件异常)、存储问题(如共享存储连接失败)以及代码或配置错误。通过细致的检查,比如调整资源配额、修复代码错误、修正配置清单,以及优化网络策略,可以有效解决问题。
集群状态的审视是基础步骤,使用kubectl get nodes检查节点状态,确保etcd、kubelet和kube-proxy等关键组件正常。事件日志(kubectl get events)是追踪故障线索的重要来源,能揭示故障原因和解决方向。
最后,关注Pod状态,通过kubectl get pods --all-namespaces来获取Pod的整体健康状况,通过kubectldescribe pod深入探究具体问题。网络连通性的验证,包括服务状态检查和服务详情查看,以及存储配置的审视,都是排查问题时不可忽略的环节。
K8S集群问题排查涉及到多方面的技术细节,只有深入理解架构、善用监控和日志、分析网络通信、DNS配置,以及细致排查各种可能的问题源,才能确保K8S集群的稳定和高效运行。
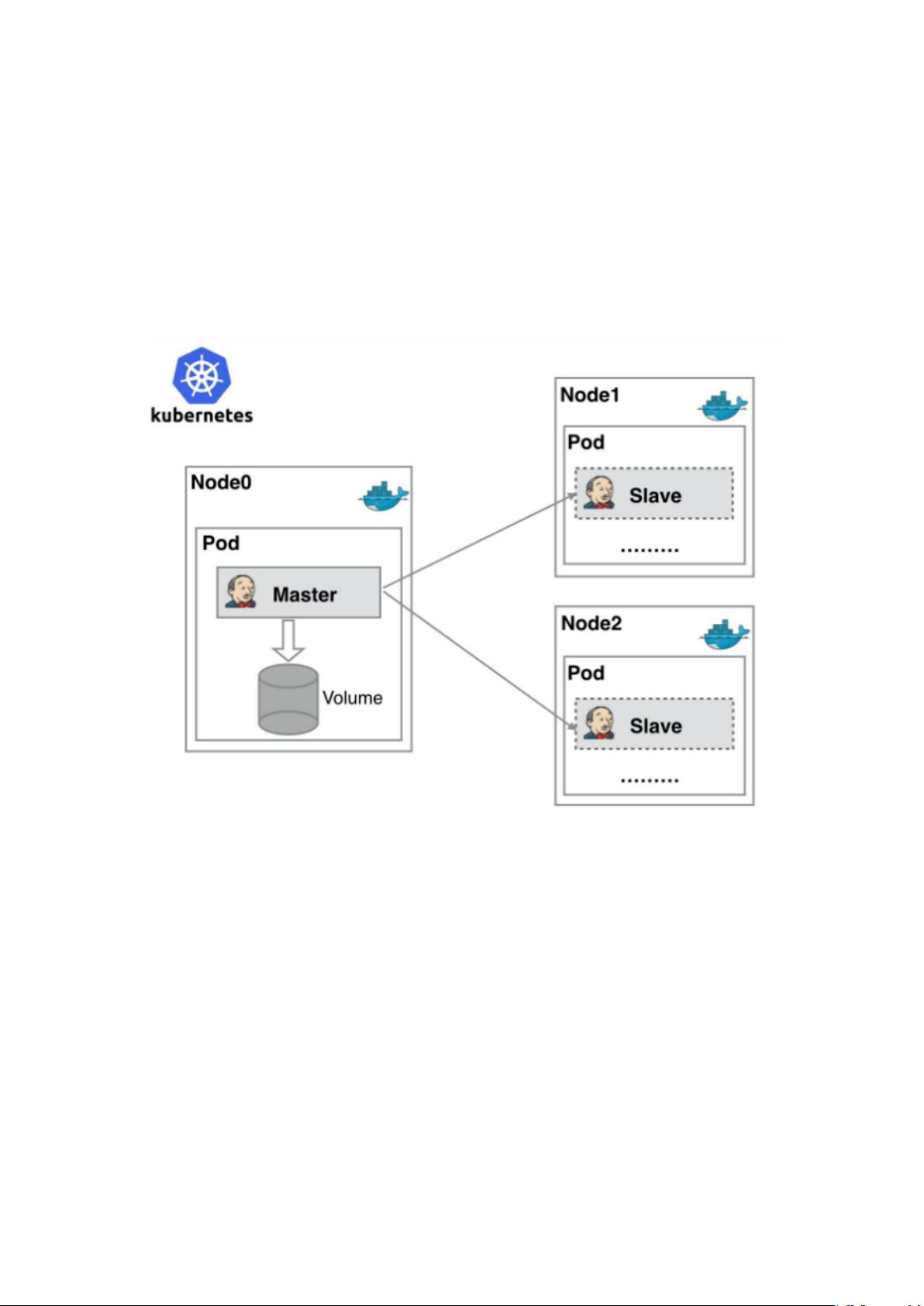
K8s 出现问题,排查秘诀!
一、 POD 启动异常、部分节点无法启动 pod:
容器里管理应用:
pod 是 k8S 中最小调度单元,POD 里面的容器共享 pod 的空间、资源、网络、存储
等。
pod 管理一个容器。
pod 管理多个容器。
pod 出现异常的原因:
资源过剩:大量 POD 在同一个物理节点,出现资源占用太多导致物理节点宕机。
内存和 CPU 超标:pod 中的应用出现内存泄露,导致 pod 内存迅速增多,pod kill
下载后可阅读完整内容,剩余5页未读,立即下载
2022-06-19 上传
2020-09-22 上传
2023-07-14 上传
2023-05-22 上传
2023-05-09 上传
2023-05-30 上传
2023-05-15 上传
2023-04-19 上传

奔向理想的星辰大海
- 粉丝: 8791
- 资源: 147
 我的内容管理
展开
我的内容管理
展开







最新资源
- not-so-simple
- hostFolder
- hackernews-clone:Hackernews使用React,GraphQL,Prisma和Postgres进行克隆
- fastapi-celery-example
- 虚幻4自由视角镜头 Camera.7z
- usersList
- Social-iNet:具有boostrap 4和javascript的简单SPA
- Java垃圾收集必备手册.rar
- CareerPath:个人研究的此回购角色有关开发职业或其他任何问题的提示
- TotalControl:一款带手控的安卓游戏
- JavaAssessments
- Proyecto-Hotel:Proyecto#1(酒店)
- collection_exercises
- 【WordPress插件】2022年最新版完整功能demo+插件14 Mar.zip
- sequelize-search-builder:极简库,用于解析搜索请求以序列化查询
- Actions:作证行动
