维灾难与机器学习:过拟合与解决方案
版权申诉
16 浏览量
更新于2024-06-27
收藏 1.91MB PPTX 举报
"该资源是关于机器学习中维灾难问题的PPT介绍,涉及了维灾难的概念、影响以及解决策略,特别提到了DBSCAN算法在高维数据中的应用。"
在机器学习领域,维灾难(Curse of Dimensionality)是一个重要的概念,由Richard E. Bellman首次提出。它描述了在高维空间中,一些原本在低维空间里有效的统计和计算方法可能会失效。例如,随着维度p的增加,即使采样点数N不变,两点之间的平均距离也会趋向于1,导致空间中的点变得稀疏,密度信息难以捕捉。这意味着在高维空间中保持相同的密度,需要更多的采样点,采样需求呈指数级增长。
维灾难的一个显著影响是在距离度量上的问题。在低维空间中,距离函数能有效地描述点与点之间的关系,但在高维空间中,如超球体的体积相对于超立方体的体积急剧缩小,使得距离函数失去其区分能力,特别是在基于距离的算法如最近邻分类器中,高维空间的距离计算可能无法准确反映数据的相似性。
此外,维灾难还与过拟合紧密相关。随着特征维度的增加,模型的复杂性也随之增加,容易导致过拟合,即模型过于适应训练数据,而对未见过的数据泛化能力下降。特征维数过高不仅会增加模型训练的难度,还会加大测试、存储的负担。同时,高维数据的可视化分析也变得极其困难。
为了解决维灾难,有多种特征选择和降维技术可供采用。过滤式(Filter)特征选择通过计算特征的相关性和重要性进行筛选;包裹式(Wrapper)特征选择通过评估不同特征子集对模型性能的影响来选择最优特征组合;嵌入式(Embedding)特征选择则是在学习过程中同时进行特征选择。此外,主成分分析(PCA)和线性判别分析(LDA)等经典降维方法可以将高维数据映射到低维空间,保留主要信息,减少冗余特征。特征提取(Feature Extraction)如词袋模型、TF-IDF等也能用于文本数据的降维处理。
理解和应对维灾难是机器学习中不可或缺的一部分,通过合理的特征选择和降维策略,可以在保持模型性能的同时,有效避免维灾难带来的问题。
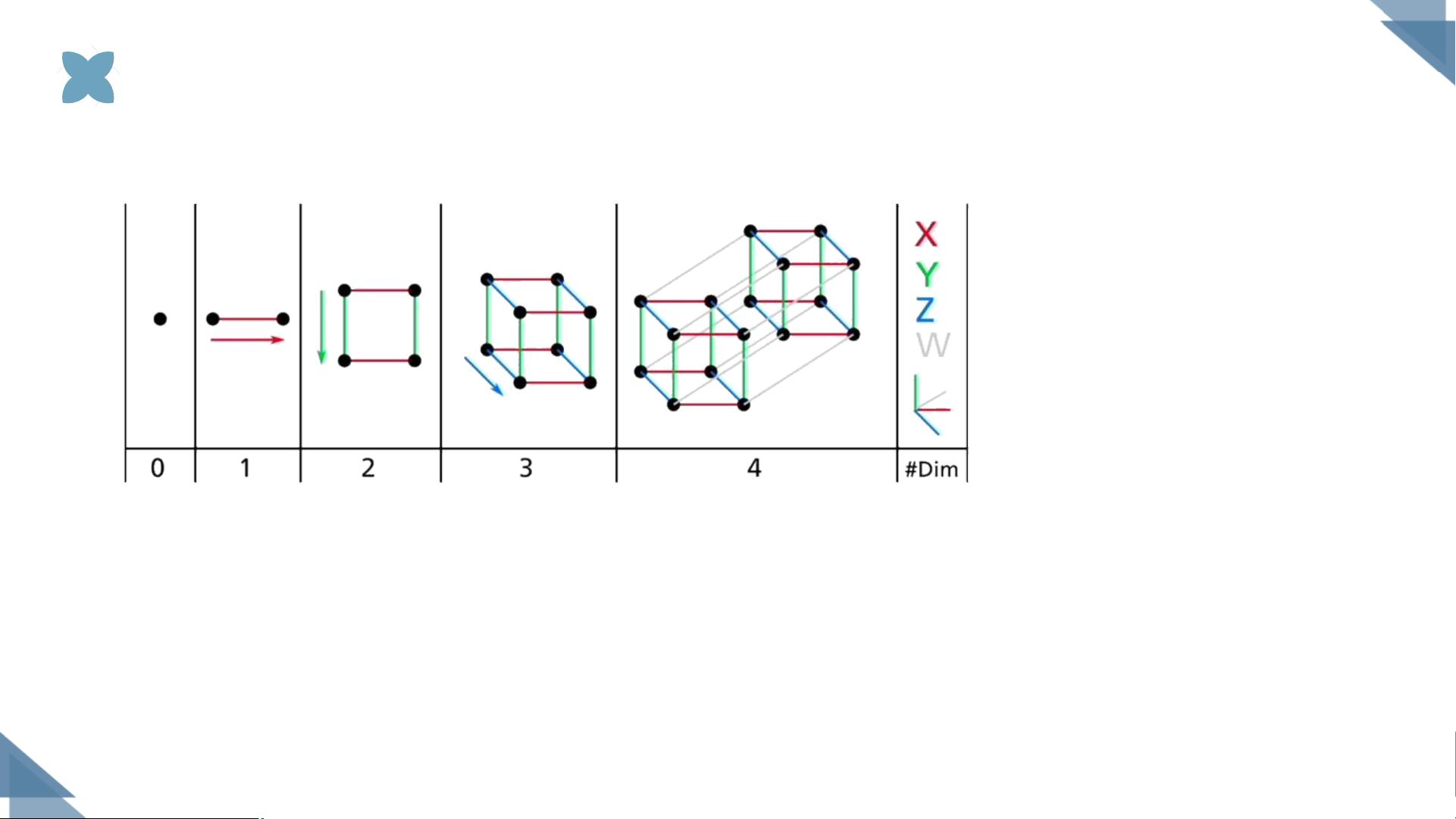
维灾难
p
=1,
N
=100,两点之间的距离为1/
N
=0.01。
p
为维度,
N
为采样点数。
剩余14页未读,继续阅读
2021-10-05 上传
101 浏览量
103 浏览量
120 浏览量
1066 浏览量
652 浏览量
232 浏览量
780 浏览量
149 浏览量

知识世界
- 粉丝: 375
 我的内容管理
展开
我的内容管理
展开







最新资源
- Tailwind CSS多列实用插件:无需配置的快速多列布局解决方案
- C#与SQL打造高效学生成绩管理解决方案
- WPF中绘制非动态箭头线的代码实现
- asmCrashReport:为MinGW 32和macOS构建实现堆栈跟踪捕获
- 掌握Google发布商代码(GPT):实用代码示例解析
- 实现Zsh语法高亮功能,媲美Fishshell体验
- HDDREG最终版:DOS启动修复硬盘坏道利器
- 提升Android WebView性能:集成TBS X5内核应对H5活动界面问题
- VB银行代扣代发系统源码及毕设资源包
- Svelte 3结合POI和Prettier打造高效Web开发起动器
- Windows 7下VS2008试用版升级至正式版的补丁程序
- 51单片机交通灯系统完整设计资料
- 兼容各大浏览器的jquery弹出登录窗口插件
- 探索CCD总线:CCDBusTransceiver开发板不依赖CDP68HC68S1芯片
- Linux下的VimdiffGit合并工具改进版
- 详解SHA1数字签名算法的实现过程
