2020.4.13数据库作业:函数依赖与范式概述
191 浏览量
更新于2024-08-29
收藏 118KB PDF 举报
本资源主要涵盖了数据库第六章的关键知识点,包括函数依赖、规范化和范式理论。以下是详细内容:
1. **函数依赖**:
- 定义:函数依赖是数据库关系模型中的一种概念,表示在一个关系模式R(U)中,属性集X对属性集Y有决定作用,即X的值能够唯一确定Y的值。记作X→Y。函数依赖分为平凡和非平凡两种类型,平凡函数依赖指Y是X的子集,而非平凡则Y不包含在X中。
- 决定因素:如果X→Y,那么X就是决定Y的决定因素。
- 双向依赖:若X→Y且Y→X,则记作X←→Y,表示两个属性集之间互为函数依赖。
- 完全函数依赖与部分函数依赖:Y对X完全函数依赖意味着X决定Y且没有其他更小的集合能单独决定Y;反之,部分函数依赖表示Y仅部分地由X决定。
2. **码和候选码**:
- 候选码:属性或属性组合K如果能够唯一标识关系R中的每一行,则K是候选码。最小的候选码称为主键。
- 超码:如果某个属性组合是候选码但不是最小的,它就被称为超码。
- 主属性与非主属性:主属性是候选码中的属性,非主属性则不参与任何候选码。
3. **范式理论**:
- **第一范式(1NF)**:要求二维表的每个分量都是不可再分的数据项,确保数据的一致性和完整性。
- **第二范式(2NF)**:基于1NF,要求所有非主属性完全函数依赖于候选码,消除部分依赖,确保数据的独立性。
- **第三范式(3NF)**:进一步去除3NF中的传递函数依赖,即不存在非主属性既依赖于候选码的一部分又依赖于另一部分的情况,确保数据的无冗余。
4. **更高阶范式**(未在部分内容中列出,但通常继续讨论的是**BCNF**( Boyce-Codd范式)、**4NF**(第四范式)和**5NF**(第五范式),它们分别对应着更严格的无依赖性和更高的数据独立性要求)。
理解这些概念有助于设计高效、结构化的数据库,确保数据的一致性、完整性和可维护性。在实际应用中,通过遵循这些范式,可以避免数据冗余和更新异常等问题。
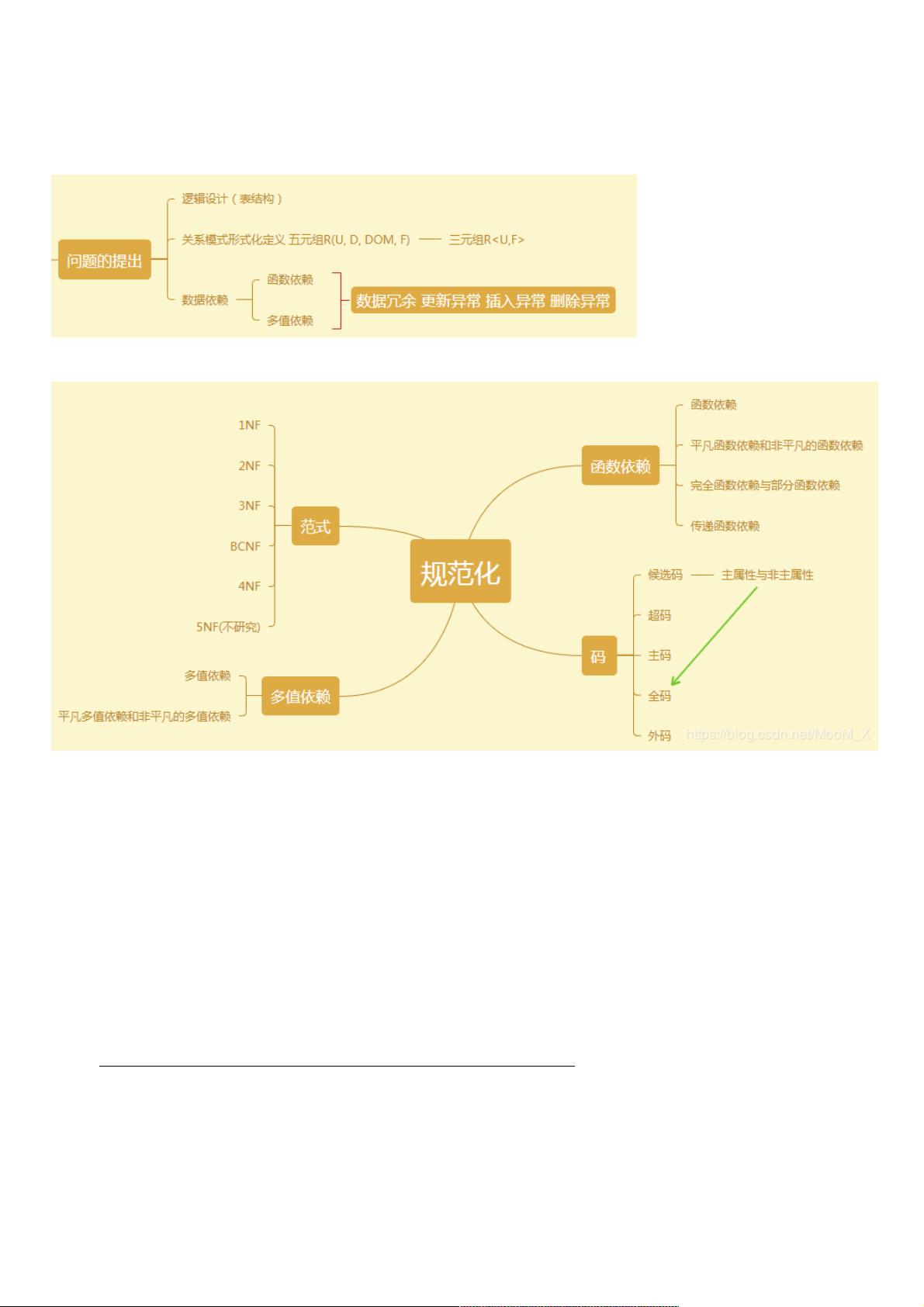
数据库第六章总结数据库第六章总结+课后题(课后题(2020.4.13作业)作业)
两个小节,问题的提出和规范化。
主要是规范化,定义比较多
问题的提出问题的提出
规范化规范化
函数依赖函数依赖
函数依赖:设R(U)是一个属性集U上的关系模式,X和Y是U的子集。若对于R(U)的任意一个可能的关系r,r 中不可能存在:两个元
组在X上的属性值相等,而在Y上的属性值不等, 则称“X函数确定Y”或“Y函数依赖于X”,记作X→Y。
平凡与非平凡:X→Y,但Y⊈X则称X→Y是非平凡的函数依赖。X→Y,但Y⊆X 则称X→Y是平凡的函数依赖。
若X→Y,则X称为这个函数依赖的决定因素
若X→Y,Y→X,则记作X←→Y。
若Y不函数依赖于X,则记作X↛rightarrow↛Y。
完全函数依赖与部分函数依赖:在R(U)中,如果X→Y,并且对于X的任何一个真子集X’, 都有 X’↛rightarrow↛Y, 则称Y对X完全函
数依赖,记作X → Y。若X→Y,但Y不完全函数依赖于X,则称Y对X部分函数依赖,记作X → Y。
传递函数依赖:在R(U)中,如果X→Y(Y⊈X),Y↛rightarrow↛X,Y→Z,Z⊈Y, 则称Z对X传递函数依赖(transitive functional
dependency)。记为:X → Z。
注: 如果Y→X, 即X←→Y,则Z直接依赖于X,而不是传递函数依赖。
码码
设K为R中的属性或属性组合。若K → U,则K称为R的一个候选码候选码(Candidate Key)。
如果U部分函数依赖于K,即K → U,则K称为超码超码 。
候选码是最小的超码,即K的任意真子集都不是候选码。
若关系模式R有多个候选码,则选定其中的一个做为主码主码(Primary key)。
主属性与非主属性:包含在任何一个候选码中的属性 ,称为主属性。不包含在任何码中的属性称为非主属性
整个属性组是码,称为全码全码(All-key)
关系模式R中属性或属性组X并非R的码,但X是另一个关系模式的码,则称X是R的 外部码外部码(Foreign key)也称外码外码。
范式范式(重点)
下载后可阅读完整内容,剩余3页未读,立即下载
1143 浏览量
2021-12-30 上传
154 浏览量
2023-05-18 上传
521 浏览量
点击了解资源详情
点击了解资源详情

weixin_38586279
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于MATLAB的二维码识别技术与应用示例
- 构建Angular TodoMVC应用:LoopBack后端与MongoLab数据库集成
- FFRouter: 适用于iOS的高性能URL路由及Rewrite库
- Postman 7.19.1版发布:强大Web API与HTTP请求调试工具
- 深入分析提取的10000条访问日志数据
- 欧美风格商业网站模板设计与资源合集
- 前后端分离课程网站项目设计实践
- HBuilder跨平台HTML IDE工具发布
- Spartan2E XC2S300E FPGA核心板Alitium原理图和PCB文件
- ColourNTP:Chrome新标签页扩展程序解析
- Vue项目开发流程指南:从安装到测试
- Jokowi工作台:Java开发者的实践指南
- 适用于Win2012R2系统的阵列卡B110I2012驱动下载
- MeatTracker: 智能追踪与管理你的肉食习惯
- Delphi 数字魔方矩阵解压缩教程
- 安卓JNI开发流程及学习要点
