"深入理解Flume配置及部署种类"
需积分: 8 193 浏览量
更新于2024-01-18
收藏 1.5MB PPTX 举报
Flume是一个分布式、可扩展且可靠的日志收集系统,用于在大规模数据处理和分析场景中收集、聚合和传输海量的日志数据。本文主要总结了Flume的配置深入内容,包括Flume部署种类、Flume流的配置结构和各个组件的功能及使用方式。
首先介绍了Flume的部署种类,包括多代理流程、流合并和多路复用流。多代理流程是指通过多个Flume代理将日志数据从源头传输到目的地,可以实现数据的分发和负载均衡;流合并是指将多个Flume流合并到一个代理中进行处理,可以实现数据的聚合和过滤;多路复用流是指通过一个代理将多个源头的日志数据同时传输到不同的接收器,可以实现数据的复用和分发。
接下来详细介绍了Flume流的配置结构,包括源(Source)、接收器(Sink)、通道(Channel)和拦截器(Interceptor)。源是指从数据来源处收集日志数据的组件,可以是文件、网络端口或者其他输入源;接收器是指将收集到的日志数据输出到目的地的组件,可以是文件系统、数据库或者其他输出目标;通道是源和接收器之间的缓冲区,用于存储和传递日志数据,可以是内存、文件系统或者其他存储介质;拦截器是对日志数据进行预处理和转换的组件,可以通过编写自定义的拦截器来实现日志的过滤、格式化等操作。
在Flume流的配置中,通过定义单一代理流来说明配置的方式。单一代理流是指通过一个通道将源头和接收器链接起来,实现数据的流动。在配置文件中需要列出源、接收器和通道的名称,然后通过指向源、接收器和通道的方式进行连接。一个源可以指定多个通道,但只能指定一个接收器。示例中展示了一个名为weblog-agent的代理配置,从avro-AppSrv-source获取数据,并通过内存通道mem-channel-1发送给hdfs-Cluster1-sink。通过这种方式,可以将日志数据从外部通过avro客户端发送到内存通道,并最终存储到HDFS中。
最后,通过一个案例说明了如何使用Flume进行配置深入。案例中的代理流程是从avro-AppSrv-source接收数据,经过拦截器处理后,通过内存通道mem-channel-1传输到hdfs-Cluster1-sink进行存储。这个配置可以根据实际需求进行调整和扩展,比如增加拦截器进行特定的数据处理,或者增加多个通道进行数据分发。
综上所述,Flume是一种功能强大的日志收集系统,通过灵活的配置方式可以实现从不同来源的日志数据收集、聚合和传输。通过深入了解Flume的配置结构和各个组件的功能,可以根据不同的需求进行灵活的配置和定制,满足大规模数据处理和分析的需求。

Flume 流配置-配置多代理流程
• 配置多代理流程
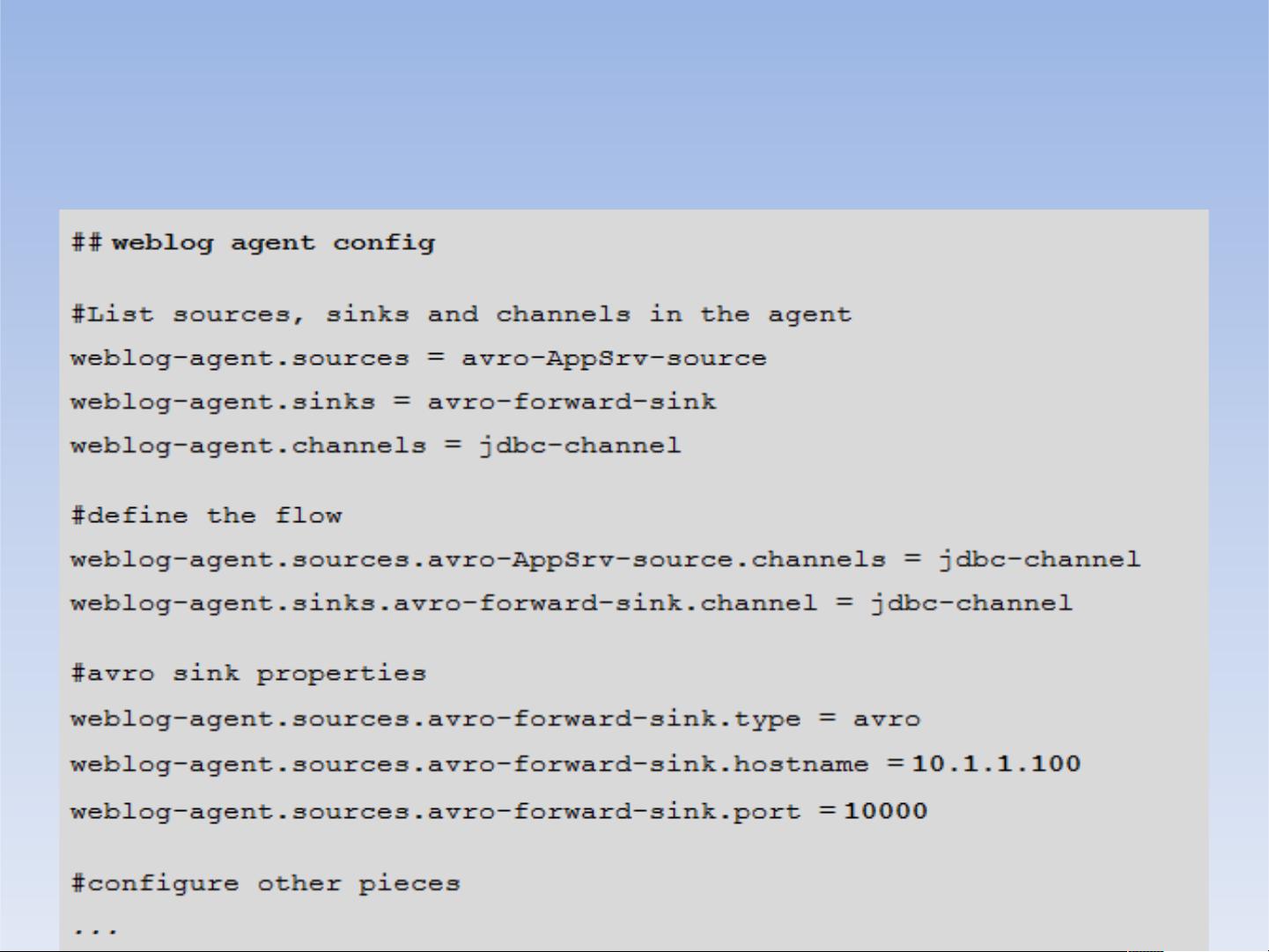
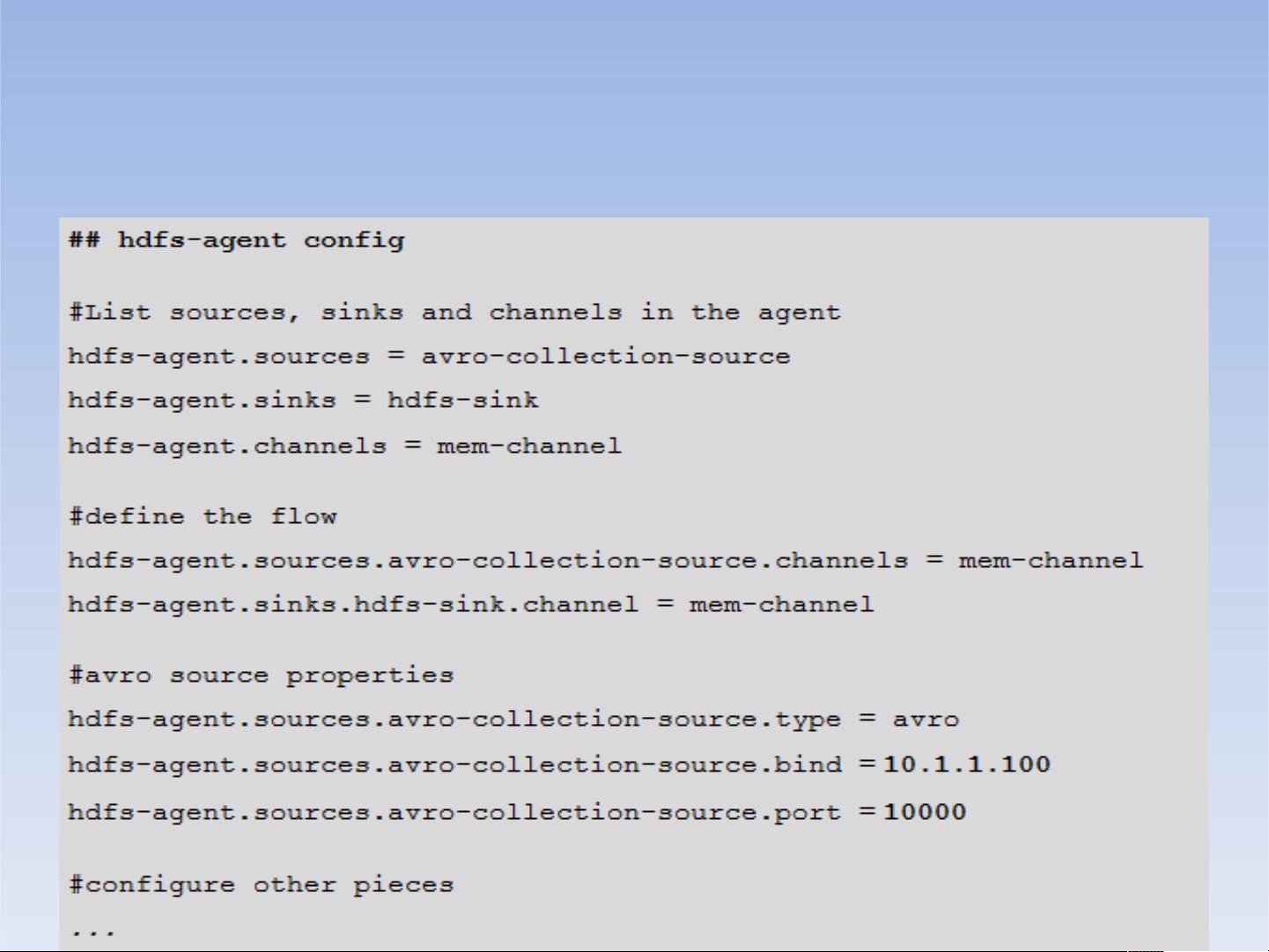
设置一个多层的流,你需要有一个指向下一跳avro源
的第一跳的avro 接收器。这将导致第一Flume代理转发事
件到下一个Flume代理。例如,如果您定期发送的文件,
每个事件(1文件)AVRO客户端使用本地Flume 代理,
那么这个当地的代理可以转发到另一个有存储的代理。
配置如下:

剩余87页未读,继续阅读
2023-06-13 上传
2023-06-10 上传
2023-06-10 上传
2023-06-10 上传
2023-06-03 上传
2023-06-10 上传

百态老人
- 粉丝: 5106
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- IPQ4019 QSDK开源代码资源包发布
- 高频组电赛必备:掌握数字频率合成模块要点
- ThinkPHP开发的仿微博系统功能解析
- 掌握Objective-C并发编程:NSOperation与NSOperationQueue精讲
- Navicat160 Premium 安装教程与说明
- SpringBoot+Vue开发的休闲娱乐票务代理平台
- 数据库课程设计:实现与优化方法探讨
- 电赛高频模块攻略:掌握移相网络的关键技术
- PHP简易简历系统教程与源码分享
- Java聊天室程序设计:实现用户互动与服务器监控
- Bootstrap后台管理页面模板(纯前端实现)
- 校园订餐系统项目源码解析:深入Spring框架核心原理
- 探索Spring核心原理的JavaWeb校园管理系统源码
- ios苹果APP从开发到上架的完整流程指南
- 深入理解Spring核心原理与源码解析
- 掌握Python函数与模块使用技巧
