Flink与ClickHouse:构建实时数据处理平台深度解析
版权申诉
"《基于Flink ClickHouse构建实时数据平台》是一份关于大数据领域的重要文档,主要关注如何利用Flink(流处理框架)与ClickHouse(高性能列式数据库系统)结合,构建实时数据处理平台。文档首先分析了业务场景和当前状况,探讨了在大数据环境中,特别是Flink与传统数据仓库系统如Hive的关系,以及Flink与ClickHouse之间的集成策略。
章节01涵盖了业务场景和现状分析,这部分可能涉及如何通过实时数据处理解决企业中的挑战,如高效的数据提取、实时分析和决策支持。作者分享了在实际项目中遇到的问题和最佳实践,强调了ClickHouse在实时分析中的优势,如低延迟、高吞吐量和列式存储架构。
章节02深入到技术实现层面,详细描述了从Flink到Hive的连接过程,包括使用Hourlevel架构设计、数据库(如Kafka用于消息队列,HDFS作为分布式文件系统)、Flink作为中间处理层,以及如何通过`altertableaddpartitionlocation`在Hive中管理数据。此外,还讨论了Flink的StreamingFileSink API,这是Flink将数据写入ClickHouse的关键接口。
文档后续的部分可能探讨了如何配置和优化Flink与ClickHouse的集成,包括数据源、流处理任务调度、以及如何利用ClickHouse的实时查询能力来提升业务效率。此外,还可能包含了一个示例,展示了完整的Flink-to-ClickHouse的数据流处理流程,包括数据的收集、处理、存储和最终的分析展示。
整体而言,这份文档提供了一套完整的实践指南,适合那些希望在大数据场景下使用Flink和ClickHouse进行实时数据分析的开发者和工程师参考。它强调了在安全性和性能优化方面的重要性,确保了在处理海量实时数据时,系统的稳定性和效率。"
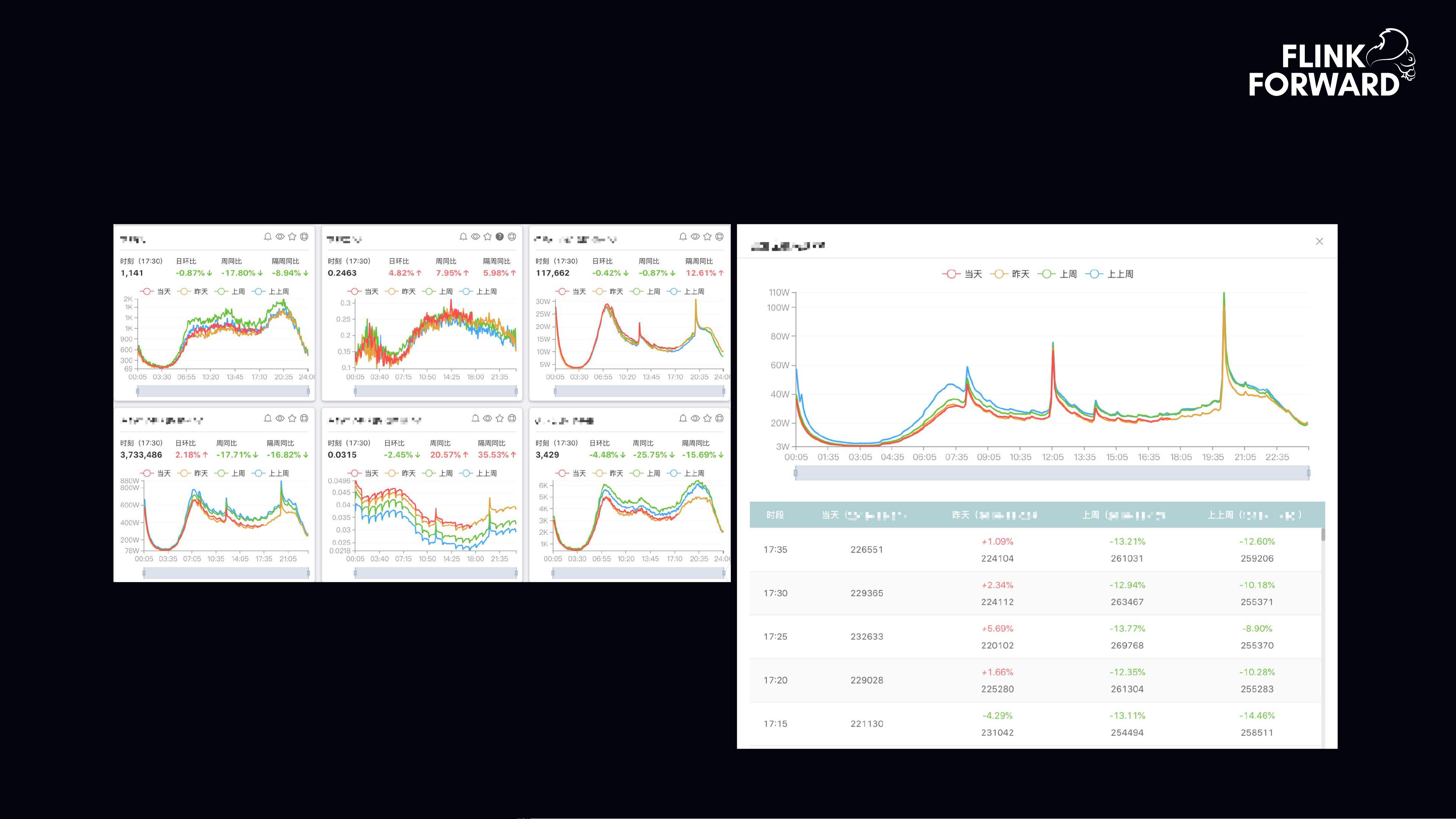
ClickHouse技术分享及实践资料合集
Business scenario and current situation Analysis
剩余27页未读,继续阅读
291 浏览量
235 浏览量
488 浏览量
143 浏览量
227 浏览量
105 浏览量
120 浏览量
187 浏览量
114 浏览量

Build前沿
- 粉丝: 1202
- 资源: 2419
 我的内容管理
展开
我的内容管理
展开







