BP神经网络驱动的对话文本语用信息聚类提升
101 浏览量
更新于2024-08-26
收藏 265KB PDF 举报
本文主要探讨了如何利用基于BP神经网络的方法来提取语用信息,特别是在自然语言处理领域的最新研究中。作者刘丁和蒋明虎来自清华大学人文与社会科学学院和计算语言学实验室,他们的研究关注的是如何有效地处理对话文本中的高维稀疏数据,因为语用信息在文本分类和聚类任务中具有重要作用。
传统的自然语言处理方法往往侧重于词义、句法等信息,而忽视了语用层面,如说话者意图、情境理解等。然而,语用信息对于理解和分析文本的真实含义至关重要。BP(Back Propagation)神经网络,作为一种强大的机器学习模型,因其能够处理非线性关系和自适应学习能力,在处理复杂的数据结构方面表现出色。
在这篇研究论文中,作者首先提出了一种新颖的策略:使用BP神经网络对对话语料库进行语用信息的抽取。通过训练神经网络,它能够学习到词汇、语法和语义背后潜在的语用模式,从而生成一个包含语用信息的矩阵。这个矩阵相比于传统的词频文档矩阵,能够提供更丰富的文本表示,有助于提高文本聚类的精度和效率。
接下来,文章展示了将聚类算法应用到由BP神经网络生成的语用信息矩阵上,对比发现,这种方法显著提升了文本聚类的结果。高维度和稀疏的语用信息矩阵通过神经网络的有效处理,减少了噪声和冗余,使得文本的内在结构更加清晰,从而提高了聚类的准确性和一致性。
总结来说,这篇文章的核心贡献在于提出了一种结合BP神经网络和语用信息的文本处理方法,有效解决了文本分类和聚类中的难题,提升了文本理解的深度和精确度。这为自然语言处理领域提供了新的视角和工具,尤其是在处理大规模对话数据时,具有重要的理论价值和实际应用潜力。
The Pragmatics Information Extraction
Based on BP Neural Network
Liu Ding, Jiang Minghu
School of Humanities and Social Sciences, Lab. of Computational Linguistics,
Tsinghua University, Beijing , China
liuding10@mails.tsinghua.edu.cn, jiang.mh@tsinghua.edu.cn
Abstract—This article describes a method that uses the BP
neural network to extract the pragmatics information from the
conversational corpus. Then cluster the texts based on the
pragmatics information matrix that generated by the BP neural
network. And, compare with the original term-document matrix,
the pragmatics information matrix improve the clustering results
obviously.
Key words: BP neural network, pragmatics, conversational
corpus, text clustering
I. INTRODUCT ION
In the recent study on nature language processing, the
researcher use lexical information, syntax information and
sematic information, rather than pragmatics information. But
in some research areas, people have to deal with the high
dimensional and sparse matrix, especially in text classification
and text clustering. The high dimensional and sparse matrix
not only contains a great many redundant information, but also
processed by more computer resources. Actually, people do
not need the huge high dimensional and sparse matrix so called
term-document matrix when cluster or classify the texts.
Indeed, there are some special key words which are enough to
identify the feature of the sample in texts, such as the time
words, scene words and role words in conversational texts.
These kinds of information are related to the participator in
conversation, therefore it could be viewed as the pragmatics
information, and this article describes the method that extracts
the pragmatics information.
II. P
RAGMAT ICS INFORMAT ION EXT RACT IONS
The direct method that extracts the time, scene and role
information from conversational texts is the name-entity
recognition technology. But it does not run well because of the
complexity of the oral context in conversational texts. And, the
pragmatics information is often implied by the context, rather
than showed directly by the words. At this time, the
name-entity recognition technology fails. Therefore, we use
the supervised machine learning model -- Back Propagation
Neural Network (BP network) to extract the pragmatics
information from conversational text. The BP network is a
kind of classical learning model, and it is often applied in
pattern recognition. Backpropagation is the generalization of
the Widrow-Hoff learning rule to multiple-layer networks and
nonlinear differentiable transfer functions. Input vectors and
the corresponding target vectors are used to train a network
until it can approximate a function, associate input vectors
with specific output vectors, or classify input vectors in an
appropriate way as defined by user. Standard backpropagation
is a gradient descent algorithm, as is the Widrow-Hoff learning
rule, in which the network weights are moved along the
negative of the gradient of the performance function[12]. The
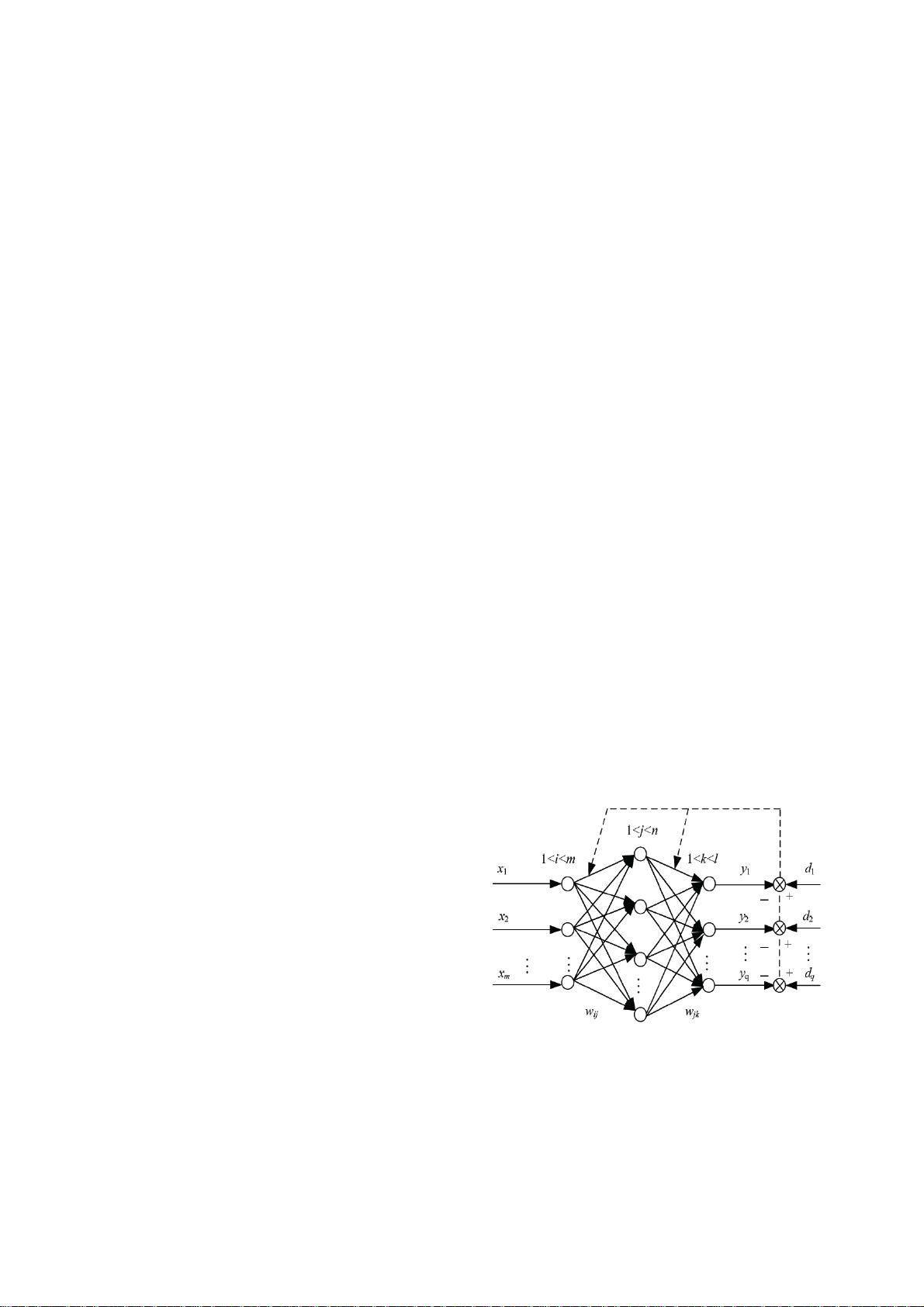
basic structure of BP neural network is shown as follows:
Input
layer
Hidden
layer
Output
layer
Figure 1. BP Neural Network
Multilayer networks often use the log-sigmoid function
(logsig) and the tan-sigmoid function (tansig) as the transfer
function. The diagrams of these two transfer function are
___________________________________
978-1-4673-2197-6/12/$31.00 ©2012 IEEE
1256
下载后可阅读完整内容,剩余3页未读,立即下载
2021-01-22 上传
2023-11-01 上传
2021-09-29 上传
2023-08-14 上传
2016-08-31 上传
2020-06-30 上传
2010-04-01 上传
2022-09-22 上传
2021-09-26 上传

weixin_38610870
- 粉丝: 1
- 资源: 913
 我的内容管理
展开
我的内容管理
展开







最新资源
- BottleJS快速入门:演示JavaScript依赖注入优势
- vConsole插件使用教程:输出与复制日志文件
- Node.js v12.7.0版本发布 - 适合高性能Web服务器与网络应用
- Android中实现图片的双指和双击缩放功能
- Anum Pinki英语至乌尔都语开源词典:23000词汇会话
- 三菱电机SLIMDIP智能功率模块在变频洗衣机的应用分析
- 用JavaScript实现的剪刀石头布游戏指南
- Node.js v12.22.1版发布 - 跨平台JavaScript环境新选择
- Infix修复发布:探索新的中缀处理方式
- 罕见疾病酶替代疗法药物非临床研究指导原则报告
- Node.js v10.20.0 版本发布,性能卓越的服务器端JavaScript
- hap-java-client:Java实现的HAP客户端库解析
- Shreyas Satish的GitHub博客自动化静态站点技术解析
- vtomole个人博客网站建设与维护经验分享
- MEAN.JS全栈解决方案:打造MongoDB、Express、AngularJS和Node.js应用
- 东南大学网络空间安全学院复试代码解析
