京东云实践:Presto在大数据分析中的关键应用与架构优化
需积分: 10 132 浏览量
更新于2024-07-15
收藏 1.72MB PDF 举报
《Presto在京东云的应用实践》一文深入探讨了京东云如何将Presto这一高性能的分布式SQL查询引擎融入其业务环境中。Presto由Facebook于2012年启动,于2013年开源,京东自那时起不断贡献并开发了自己的Presto-JD版本,最终将其成功应用于京东云。
文章首先介绍了Presto的基本概念,它是一种基于标准SQL语法的查询引擎,支持处理GB到PB级的大数据量,具备良好的可扩展性和跨数据源查询能力,特别适合交互式的数据分析场景。京东在引入Presto时,对其进行了定制化改造,包括优化测试环境,如设置了13个节点,每节点内存20GB,核心处理器32个,采用Spark-1.4.1和Hadoop2.5.0-cdh5.3.0等技术栈。
在京东内部,Presto的使用经历了从初期的测试到广泛应用的过程,例如,通过Tpcdsbenchmark测试用例来验证其性能,这些用例涉及24个表,数据量达100GB,并且将所有数据转换为ORC格式,以提升查询效率。
在京东云的应用阶段,文章重点讨论了数据源的丰富和优化,包括添加了Oracle和SQLServer等新的数据库连接器,以及在关系型数据库中的条件推送优化,如MySQL的分库分表策略,只需要配置简单的规则就能支持多种字段类型和常见的SQL操作。此外,京东云还强化了安全访问机制,对Presto集群实施了身份验证和权限控制,用户需提供用户名和密码,而访问HDFS和HiveMetastore则通过Kerberos验证,确保数据安全。
为了更好地管理和扩展Presto集群,文章提到采用了YARN上的OnYarn框架,利用Slider进行资源申请,并对NodeManager和AppMaster/Coordinator容器的监控与容错处理进行了讨论,如当NodeManager宕机或容器问题时,系统能够自动处理故障,保持服务的稳定运行。
这篇文章详细展示了京东云如何将Presto融入其云计算平台,从技术选型、环境配置、功能优化到安全性管理,都提供了实用的实践经验,对于其他企业在大规模数据处理和分析场景下应用Presto具有很高的参考价值。
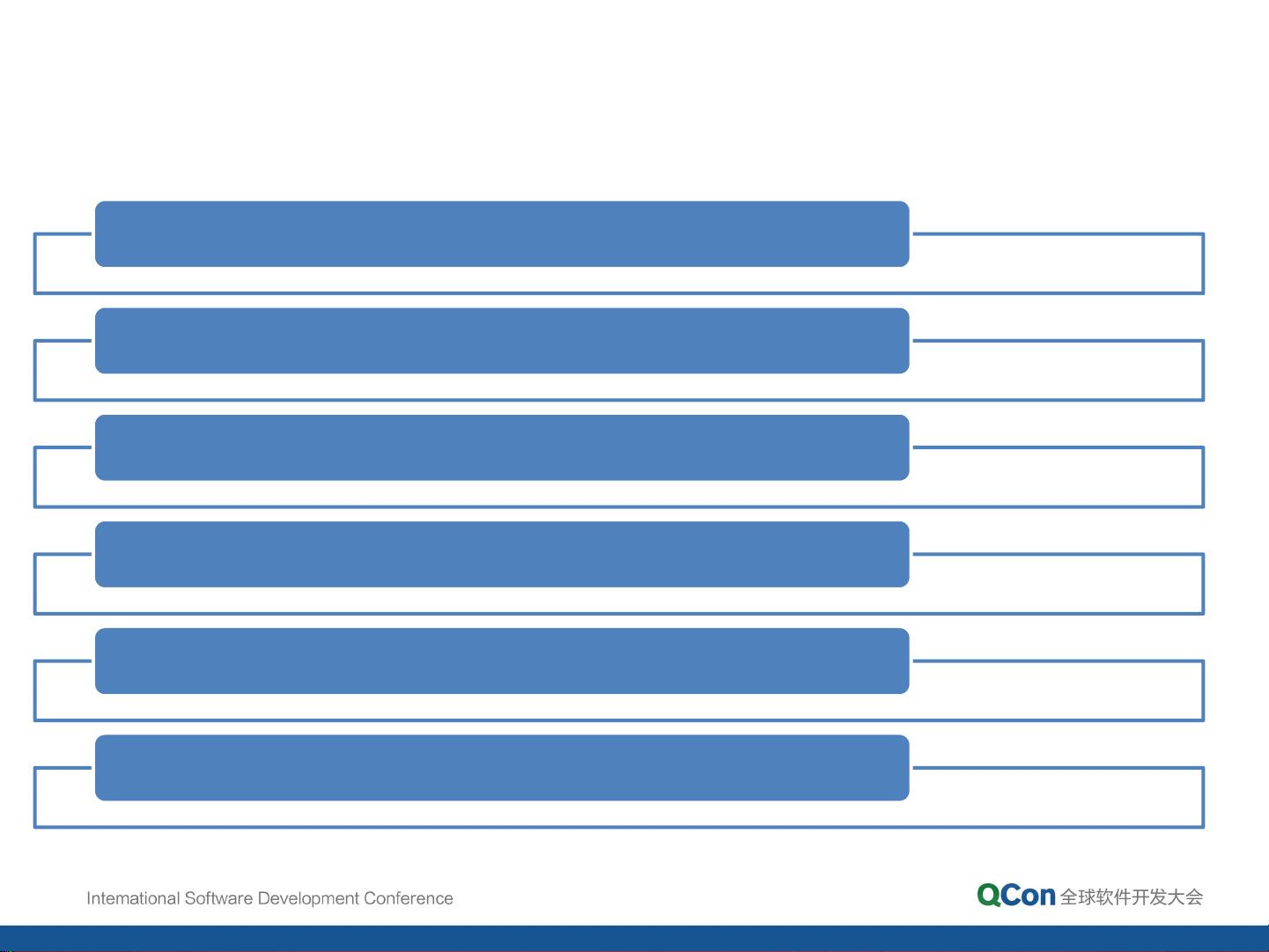
Presto特性
分布式查询引擎
标准SQL语法
支持GBs to PBs的数据量
可扩展性
支持跨数据源查询
交互式的数据分析
剩余17页未读,继续阅读
2021-10-12 上传
2021-03-29 上传
2021-04-08 上传
2021-08-19 上传
2019-06-15 上传

htmljsp
- 粉丝: 41
- 资源: 28
 我的内容管理
展开
我的内容管理
展开







最新资源
- FTK-Imager-Triage-Notes:这是有关如何使用FTK Imager提取Windows计算机的取证声音图像的分步指南
- node-chunked-response:一个普通的节点应用程序通过HTTP发出分块数据
- TFTLCD液晶显示器的驱动原理.zip
- 灵感12
- 精品-- 个人简历模板.zip
- CmderPackage:执行 Cmder、Cygwin 和其他几个包的下载和初始设置的脚本
- PersonalProject-Java:wordcount-Java提交仓库
- mhserv:一个简单的C HTTP服务器
- rust-u2f:用Rust编写的U2F安全令牌模拟器
- WindowsFormsApp1.7z
- studentsystem:学生信息管理系统
- kuechenstation-开源
- c04-ch5-exercices-premyskw:c04-ch5-exercices-premyskw由GitHub Classroom创建
- web-bootstrapWebsite:sitio con引导程序
- msp430简易教程.zip
- opendomo-vision:对 Opendomo OS 2.0 的相机支持
