Pytorch实现的WaveNet-Vocoder详细教程
版权申诉
128 浏览量
更新于2024-08-08
收藏 110KB DOCX 举报
"该资源是一个使用Pytorch框架实现的WaveNet-Vocoder项目,适用于音频处理,特别是语音合成领域。项目提供了详细的安装指南和示例,包括在不同环境下的配置,如本地环境和SLURM集群环境。"
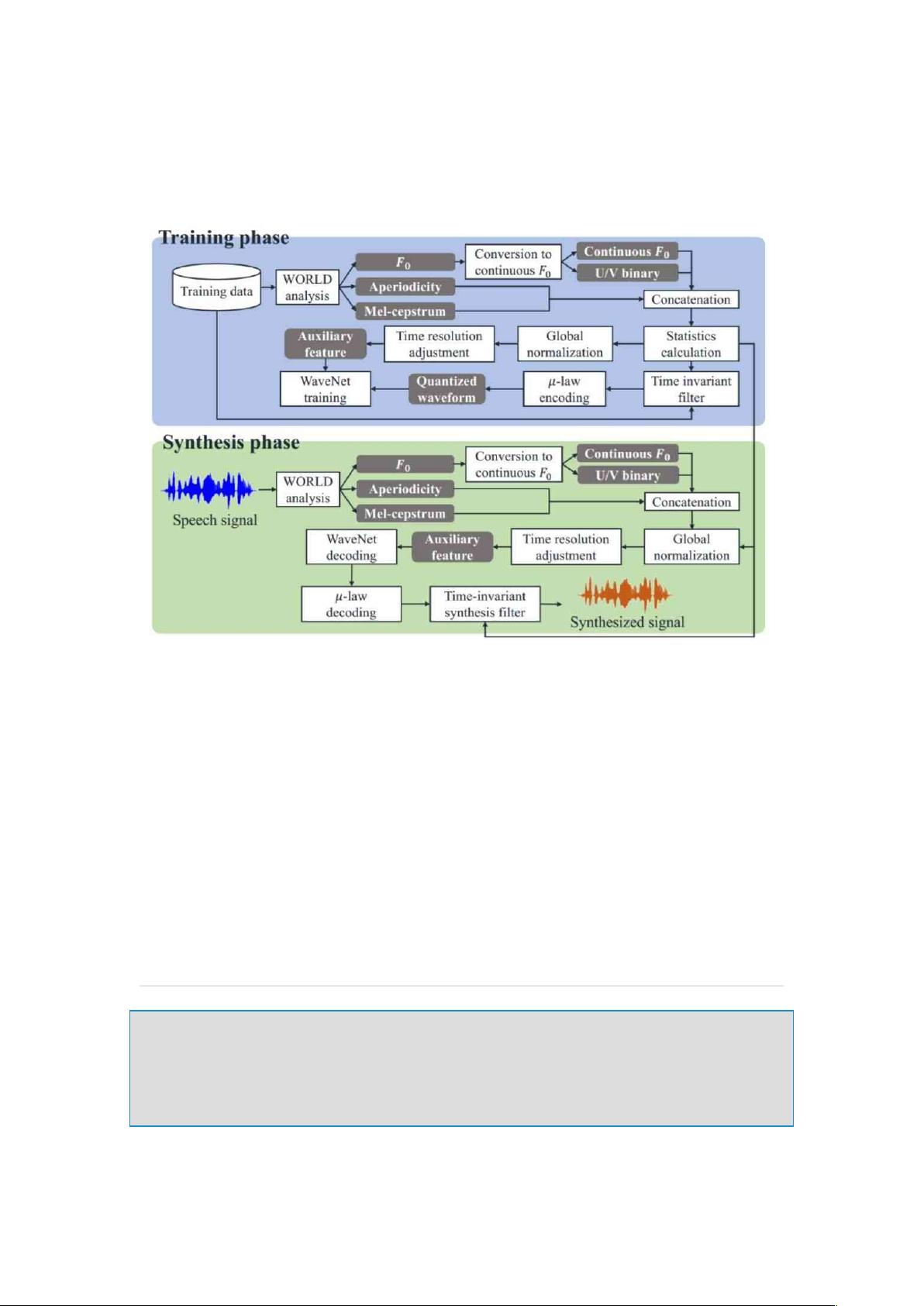
WaveNet-Vocoder是一种先进的音频信号合成模型,最初由DeepMind开发,主要用于高质量的语音合成。它利用卷积神经网络(CNN)的深度学习架构,通过捕捉音频信号中的长时间依赖关系来生成逼真的音频样本。在Pytorch中实现WaveNet-Vocoder,允许开发者利用这个强大的工具进行自定义和实验。
项目安装要求如下:
1. **CUDA 8.0**: 这是NVIDIA的并行计算平台,用于在GPU上加速深度学习计算。确保你的系统支持CUDA 8.0版本,以便利用GPU的计算能力。
2. **Python 3.6**: 项目需要Python 3.6作为基础环境,这是Python的一个稳定版本,广泛用于数据科学和机器学习项目。
3. **virtualenv**: 一个Python虚拟环境管理工具,用于隔离项目依赖,避免不同项目间的库冲突。
为了安装和运行此项目,你需要执行以下步骤:
1. 使用`git clone`命令克隆项目仓库到本地。
2. 进入项目目录下的`tools`子目录。
3. 使用`make -j`命令编译必要的工具。
项目提供了一些示例,基于Kaldi的风格食谱(recipe),这是一款开源的语音识别工具包。示例包括:
- SD模型:可能指的是单声道(Single-Dimensional)模型,用于基础的语音合成。
- SI-CLOSE模型:可能代表单声道闭合(Single-Input Close)模型,可能是指在特定条件下训练的模型。
- SI-OPEN模型:可能是单声道开放(Single-Input Open)模型,可能用于更广泛的输入或更自由的条件。
在运行示例时,根据你的服务器环境,可以使用本地的`run.pl`命令或者SLURM(一种集群作业调度系统)的`slurm.pl`命令。对于SLURM,需要编辑配置文件`conf/slurm.conf`和`cmd.sh`以适应你的服务器分区和资源需求。
在`cmd.sh`文件中,你需要指定训练命令(`train_cmd`)和CUDA命令(`cuda_cmd`),例如,在本地环境下使用单个GPU,而在SLURM集群中,你需要配置SLURM的相关参数以适配GPU资源。
这个项目为开发者提供了一个灵活的Pytorch实现的WaveNet-Vocoder框架,可以在多种环境中运行,进行语音合成的研究和开发。对于那些对音频处理、尤其是语音合成技术感兴趣的Python开发者来说,这是一个非常有价值的资源。
本库是用 实现的 。
安装需求:
推荐使用内存大于 的 。
安装:
!"## $%#&$!#
#!
%&'
下载后可阅读完整内容,剩余5页未读,立即下载
459 浏览量
845 浏览量
2024-07-11 上传
220 浏览量
180 浏览量
152 浏览量
189 浏览量
225 浏览量
2025-01-07 上传

码农.one
- 粉丝: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android平台DoKV:小巧强大Key-Value管理框架介绍
- Java图书管理系统源码与MySQL的无缝结合
- C语言实现JSON与结构体间的互转功能
- 快速标签插件:将构建信息轻松嵌入Java应用
- kimsoft-jscalendar:多语言、兼容主流浏览器的日历控件
- RxJava实现Android多线程下载与断点续传工具
- 直观示例展示JQuery UI插件强大功能
- Visual Studio代码PPA在Ubuntu中的安装指南
- 电子通信毕业设计必备:元器件与芯片资料大全
- LCD1602显示模块编程入门教程
- MySQL5.5安装教程与界面展示软件下载
- React Redux SweetAlert集成指南:增强交互与API简化
- .NET 2.0实现JSON数据生成与解析教程
- 上海交通大学计算机体系结构精品课件
- VC++开发的屏幕键盘工具与源码解析
- Android高效多线程图片下载与缓存解决方案
