小米科技:HBase在业务中的深度应用与优化实践
需积分: 22 60 浏览量
更新于2024-07-19
收藏 2.34MB PDF 举报
HBase在小米公司的应用实践深入解析
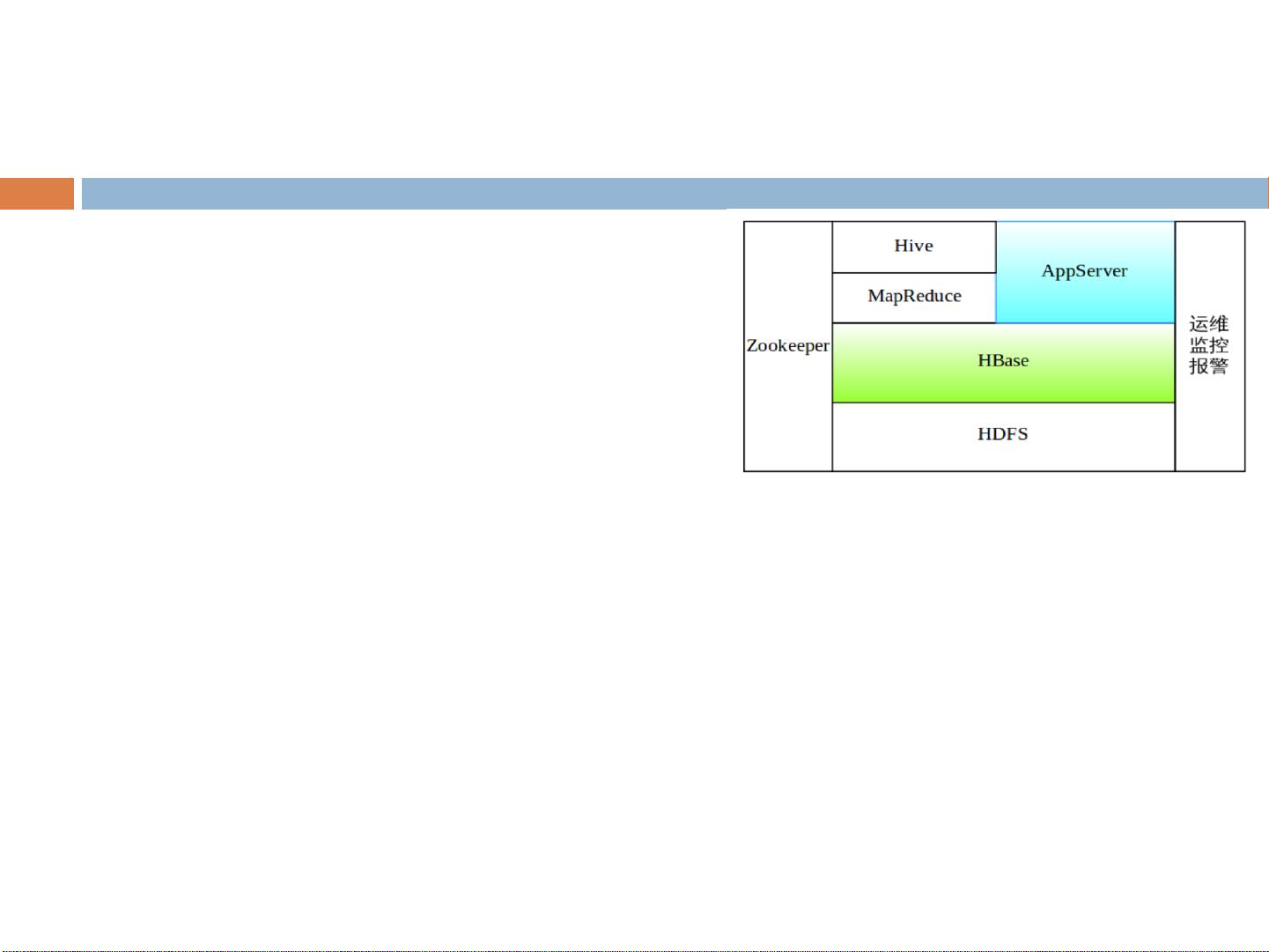
小米科技的基础平台开发组分享了他们如何将HBase这一分布式列式存储系统应用到公司业务中的经验。HBase作为Apache Hadoop生态系统的一部分,以其强大的水平扩展能力、高可用性和灵活的数据模型,成为了小米众多关键业务的核心支撑。
首先,HBase的基本原理包括数据模型,如Column(列)、Rowkey(行键)和Table(表),以及其独特的架构设计,如Region(区域)和RegionServer。HBase的每个Region由一组Rowkey范围组成,由RegionServer进行管理,数据通过Rowkey的有序分片确保高效查询。每个写操作涉及多个WriteHandler(写处理器),如HLog(历史日志),用于记录待持久化的数据变更。
在小米的实际应用中,HBase被广泛应用于多个业务场景,如米聊的消息存储、小米云服务(MiCloud)中的短信和通话记录、以及小米推送服务。选择HBase的主要原因是其能应对大数据量的挑战,提供7x24小时的高可用服务,支持灵活的Schema变化,并且利用多版本特性跟踪米聊消息的状态。此外,小米还特别关注写性能优化,尤其是在高并发的推送消息场景下,以实现高吞吐量。
小米团队在使用HBase的过程中,针对写吞吐量问题进行了重要的改进。他们从旧的HLog写模型中的WriteHandler机制入手,如LocalAppendBuffer和WriteHandler的不同阶段,发现存在抢锁和恶性竞争的问题。为了解决这些问题,他们引入了新的写模型,将WriteHandler分为多个txid_0、txid_1等,这显著提高了写操作的效率和系统的稳定性。
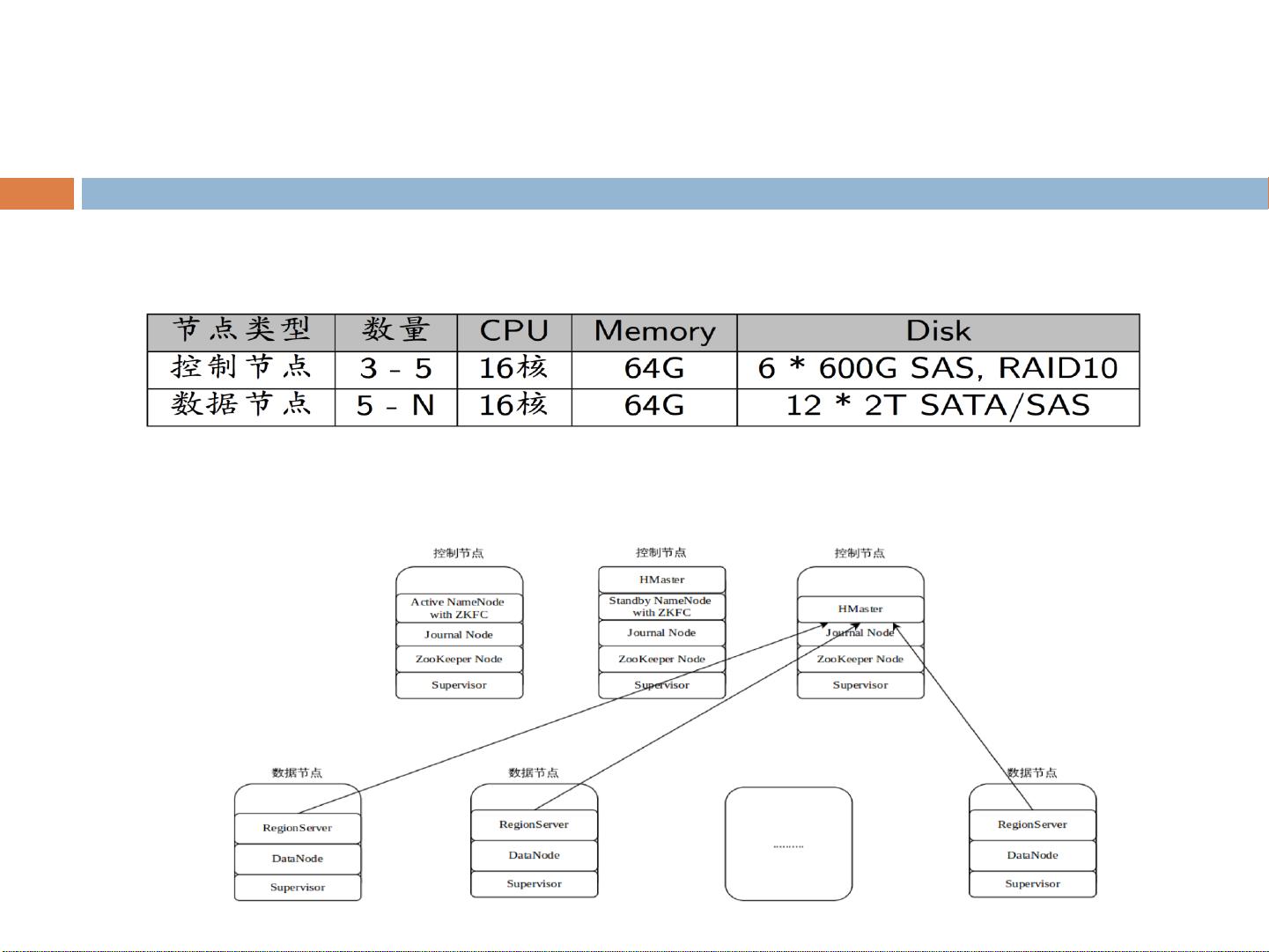
小米还构建了自己的Minos集群部署和监控系统,基于开源项目,提供了全面的运维工具,包括启动、停止、滚动更新等功能,并能实时监控和展示集群状态,确保HBase服务的稳定运行。
小米通过深入理解和优化HBase的架构和机制,将其成功融入到公司的核心业务中,实现了高性能、高可用的数据存储和处理。这份实践总结对于理解HBase在大型互联网企业的实际应用具有很高的参考价值。
HBase在小米业务的应用
服务十多个不同业务
米聊消息全存储
小米云服务(MiCloud)
短信、通话记录
小米推送服务
选用HBase的原因
水平扩展能力:MiCloud大数据场景
高可用性:7 * 24 小时服务
灵活的Schema:业务不断发展也会有修改Schema需求
多版本特性:追踪米聊消息状态
写性能优化:小米Push推送消息时高吞吐量写
强一致性
剩余39页未读,继续阅读
2019-11-09 上传
130 浏览量
2019-08-28 上传
2023-09-09 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-11-03 上传

futengft
- 粉丝: 2
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- McGraw.Hill.Modern.Processor.Design.Fundamentals.of.Superscalar.Processors.Jul.2004.pdf
- Nonlinear Fiber Optics
- 用单片机制mp3(电子书,音乐播放,动画)
- MTK 程序编译方法
- 李开复给大学生的信7
- 李开复给大学生的信5
- 李开复给大学生的信4
- SUN XVM VIRTUALBOX
- 校园网毕业设计几种方案
- 数据库设计60个技巧.pdf
- Windows Message
- C++语言程序设计(清华大学出版—郑莉)习题答案
- c语言二级考试题2007年9月
- Apress.SQL.Server.2008.Transact.SQL.Recipes.Jul.2008.pdf
- sql server\Apress.Pro.T-SQL.2008.Programmers.Guide.Aug.2008.pdf
- 深入浅出JBoss+Seam.pdf
