MapReduce数据去重实战教程
需积分: 9 173 浏览量
更新于2024-07-17
1
收藏 1.23MB PDF 举报
"MapReduce初级案例,通过数据去重的实例,帮助初学者理解并行化思想在处理大数据集中的应用。"
在MapReduce框架中,数据去重是一个基础且重要的任务,尤其对于处理大规模数据集时,能有效地减少冗余信息,提高数据处理效率。在这个案例中,我们将学习如何使用Hadoop的MapReduce来实现数据去重。
1. 实例描述
案例的目标是对两个数据文件(file1 和 file2)中的重复行进行去除,只保留唯一的行。例如,文件中包含日期和字母的组合,如"2012-3-1a"。输入文件可能包含重复的日期字母组合,而输出文件则要求去除重复项。
2. 设计思路
要实现数据去重,关键在于如何合理地分配和处理数据。在MapReduce模型中,数据处理分为两个主要阶段:map阶段和reduce阶段。
- **Map阶段**: 在这个阶段,输入文件被分割成多个块,并在不同的节点上并行处理。对于数据去重,map函数需要将每一行数据(如"2012-3-1a")作为key,而value可以是任意值,通常设置为一个固定字符串,如""或"1"。这样做的目的是确保所有相同数据的记录都会被映射到同一个reduce任务。
- **Shuffle和Sort阶段**: 这一阶段将map阶段的输出按key进行排序和分区,使得相同key的数据被聚集在一起,准备进入reduce阶段。
- **Reduce阶段**: reduce函数接收所有具有相同key的value列表,对于数据去重问题,我们只需要输出key(即不重复的行),value列表可以忽略。因此,reduce函数只需要将key复制到输出,value保持为空即可。
3. 实现细节
- Map函数: 读取每一行数据,将其作为key,输出<key, value>对,例如<“2012-3-1a”, “”>。
- Reduce函数: 接收所有相同key的value列表,例如<“2012-3-1a”, [“”, “”, …]>,仅输出key,即<“2012-3-1a”, “”>。
4. 执行与结果
执行上述MapReduce程序后,将得到一个不含重复行的输出文件,如描述中的样例输出所示。这个简单的数据去重案例展示了MapReduce如何通过分布式计算处理大量数据并实现特定的业务逻辑。
通过这个初级案例,初学者可以更好地理解MapReduce的工作原理,以及如何利用它解决实际问题,比如数据清洗、去重等。进一步学习和实践MapReduce,可以掌握更复杂的操作,如JOIN、聚合等,从而在大数据分析和处理领域打下坚实的基础。

学虚拟化云计算技术 就来三通 it 学院 www.santongit.com
29. public static class Reduce extends
30. Reducer<IntWritable,IntWritable,IntWritable,IntWritable>{
31. private static IntWritable linenum = new IntWritable(1);
32. //实现 reduce 函数
33. public void reduce(IntWritable key,Iterable<IntWritable> values,Context
context)
34. throws IOException,InterruptedException{
35. for(IntWritable val:values){
36. context.write(linenum, key);
37. linenum = new IntWritable(linenum.get()+1);
38. }
39. }
40. }
41. public static void main(String[] args) throws Exception{
42. Configuration conf = new Configuration();
43. //这句话很关键
44. conf.set("mapred.job.tracker", "192.168.1.2:9001");
45. String[] ioArgs=new String[]{"sort_in","sort_out"};
46. String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingAr
gs();
47. if (otherArgs.length != 2) {
48. System.err.println("Usage: Data Sort <in> <out>");
49. System.exit(2);
50. }
51. Job job = new Job(conf, "Data Sort");
52. job.setJarByClass(Sort.class);
53. //设置 Map 和 Reduce 处理类
54. job.setMapperClass(Map.class);
55. job.setReducerClass(Reduce.class);
56. //设置输出类型
57. job.setOutputKeyClass(IntWritable.class);
58. job.setOutputValueClass(IntWritable.class);
59. //设置输入和输出目录
60. FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
61. FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
62. System.exit(job.waitForCompletion(true) ? 0 : 1);
63. }
64. }
2.4 代码结果
1)准备测试数据
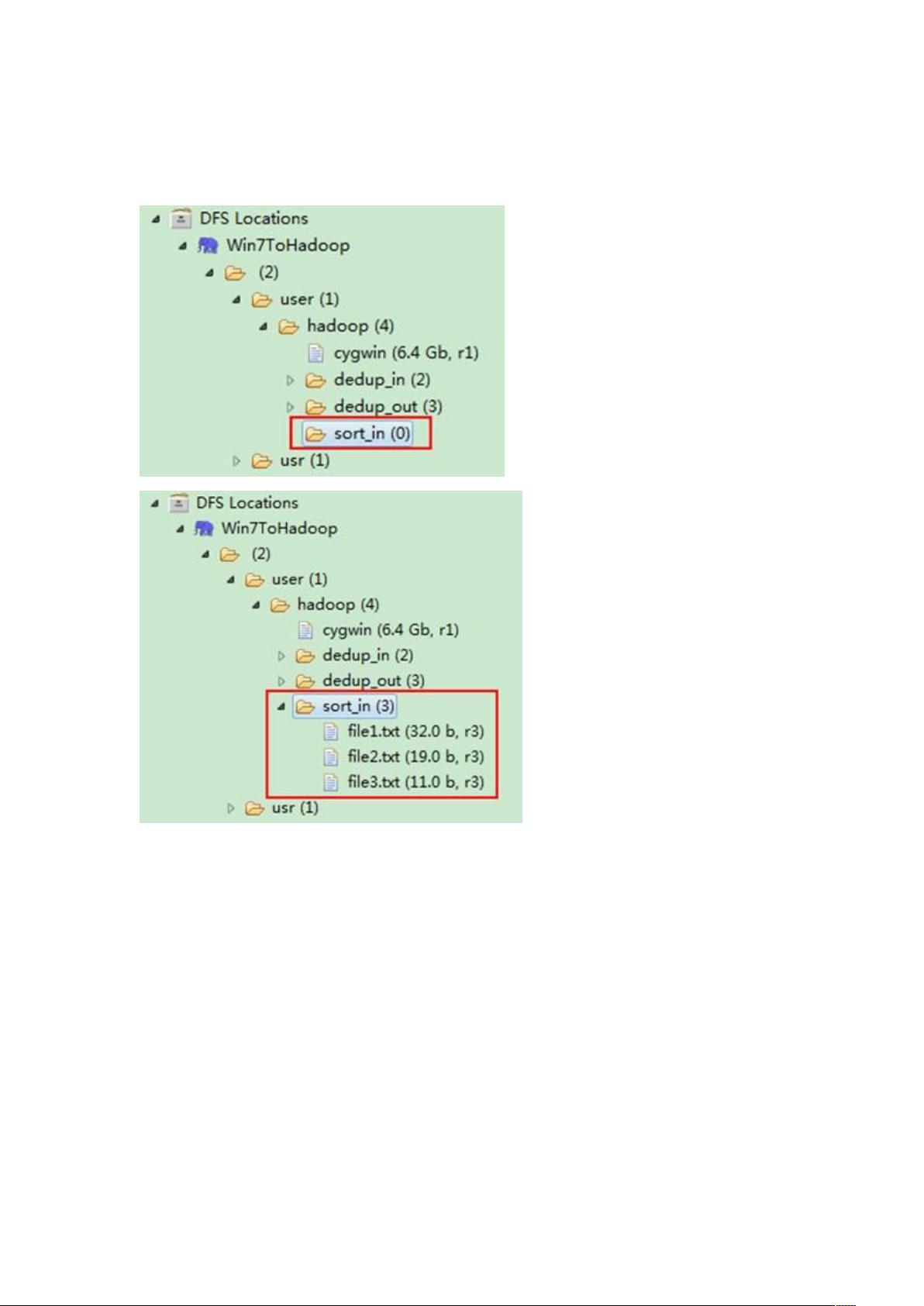
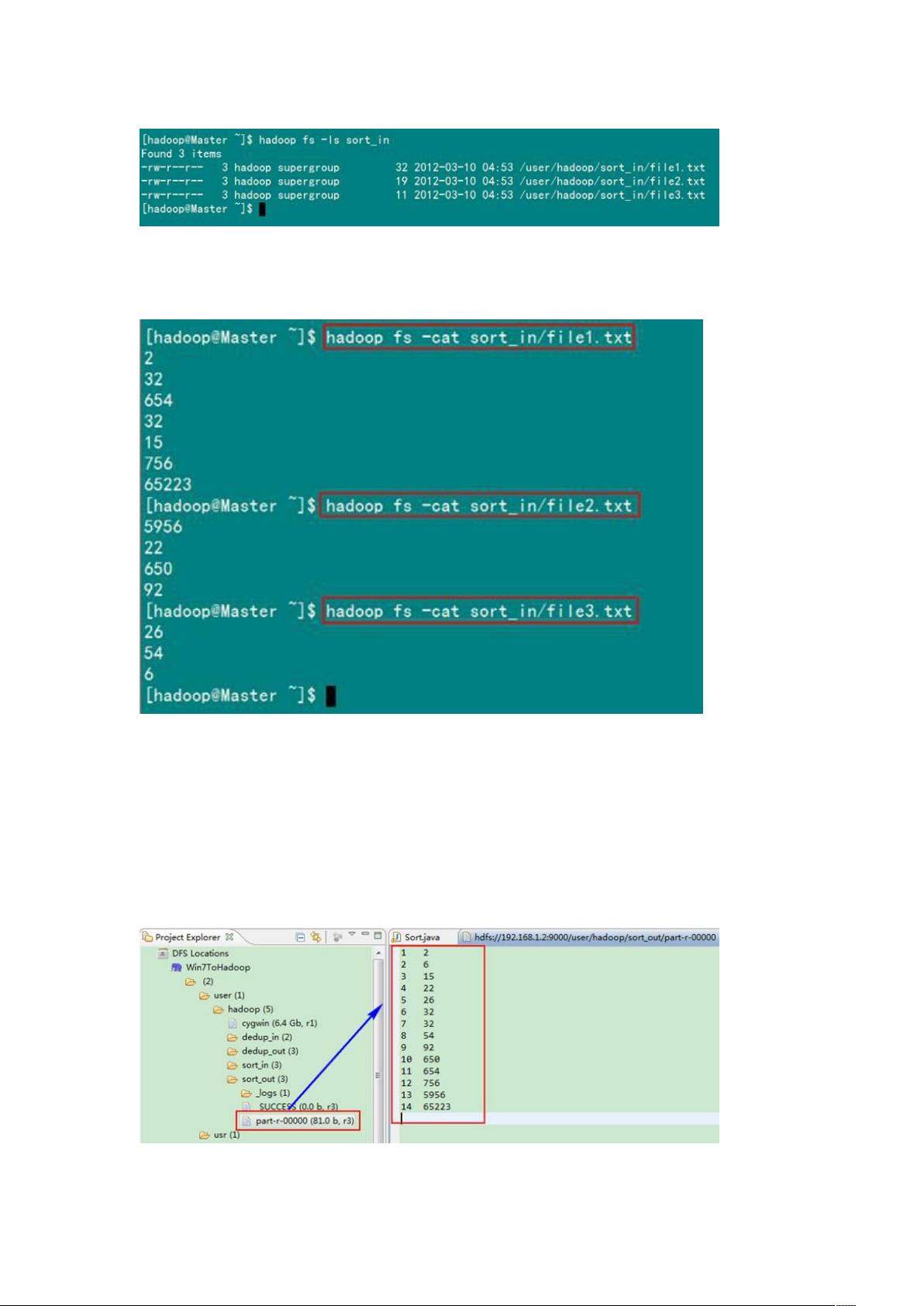
剩余57页未读,继续阅读
2019-03-07 上传
2015-10-26 上传
2022-03-20 上传
2023-05-22 上传
2024-12-14 上传
2022-05-24 上传
点击了解资源详情
点击了解资源详情

promick
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- matlab教程关于命令方面
- SQL2005语句详解
- ASP.net中md5加密码的方法
- 内存调试技巧:C 语言最大难点揭秘
- 随着计算机的发展和普及,计算机系统数量与日俱增,为了保证计算机系统安全可靠工作,网络监控系统的应用也日渐广泛。本文主要介绍机房网络监控系统的现状和发展。
- ORACLE财务讲解.pdf
- 计算机外文翻译基于J2EE
- 所有的网络协议关系(ip,udp,tcp)
- 高质量C、C++编程指南
- 动态抓取网页内容,蜘蛛程序
- 会话初始协议(SIP)第三方呼叫控制的研究
- 网络工程师必懂的十五大专业术语
- 高质量C_C编程指南
- 浅谈E1线路维护技术与应用.doc
- java试题及答案下载
- Delphi 7 程序设计与开发技术大全
