K-MEANS与DBSCAN聚类算法详解
需积分: 10 127 浏览量
更新于2024-09-02
收藏 575KB PPTX 举报
"4-聚类算法-converted.pptx 是一份关于聚类算法的介绍,主要涉及了K-MEANS算法和DBSCAN算法的基本概念、工作流程、优势以及参数选择。"
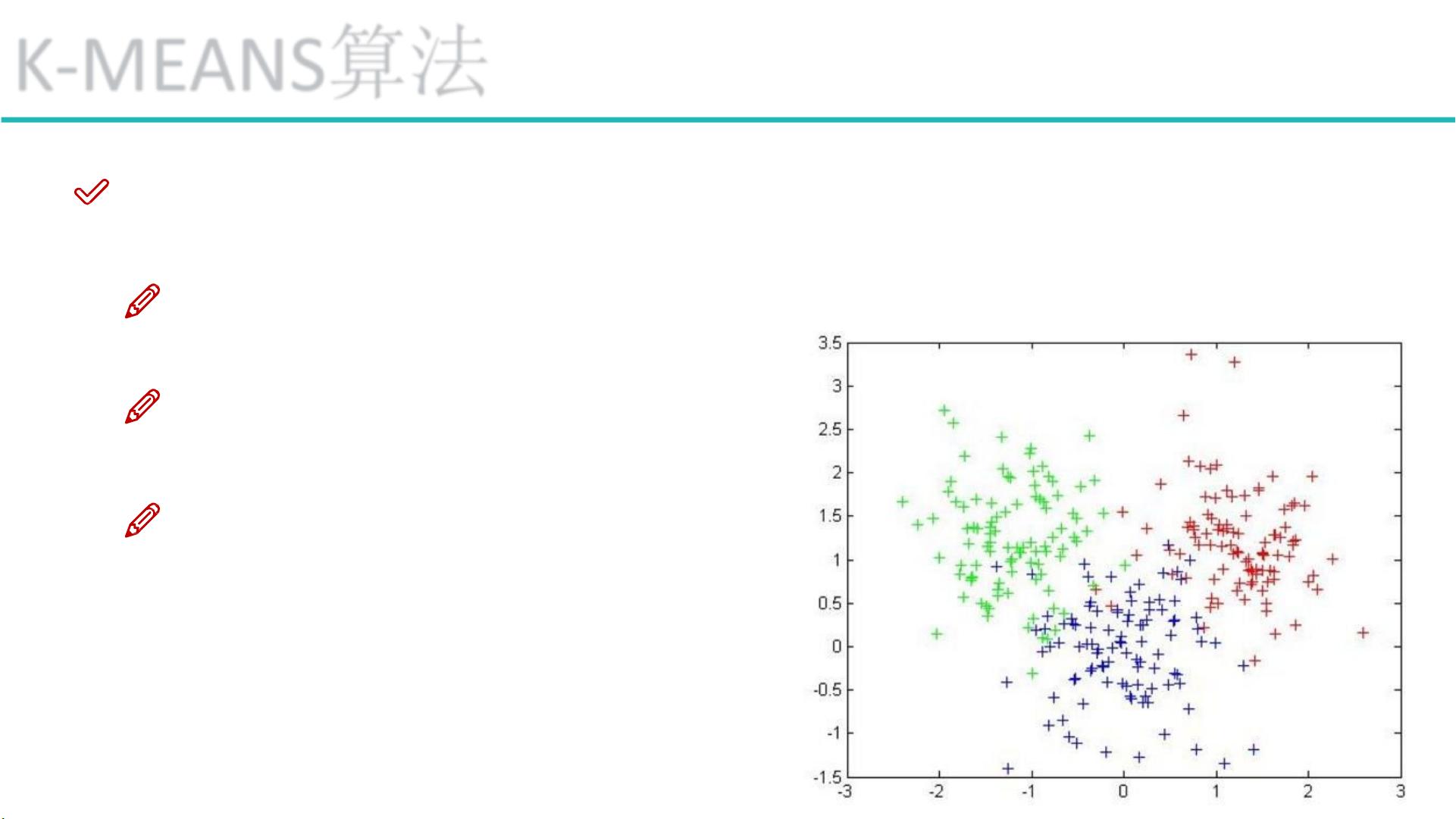
K-MEANS算法是一种广泛应用的无监督聚类方法,主要用于将数据集中的对象根据它们的相似性分成K个不同的簇。在这个过程中,由于没有预先定义的标签,我们需要通过算法自行发现数据的内在结构。K-MEANS的关键在于确定簇的数量K,这通常需要经验和领域知识。算法的核心是质心,即每个簇的中心,它可以通过计算所有簇内点的平均值来获取。距离度量通常选择欧几里得距离,有时也会使用余弦相似度,特别是在处理高维数据时。K-MEANS的目标是最小化簇内的平方误差和,即使得每个点到其所在簇质心的距离最小。算法的工作流程包括初始化质心、分配点到最近的簇、更新质心,这一过程重复直到质心不再显著变化或达到预设的最大迭代次数。K-MEANS的优势在于简单和快速,尤其适用于大规模、常规形状的数据集。然而,它的主要挑战是需要预先设定K值,且对于非凸形状的簇识别效果不佳,计算复杂度与样本数量成线性关系。
DBSCAN(密度基空间聚类)是一种能处理任意形状簇的聚类算法,特别适合发现高密度区域和排除噪声。DBSCAN基于密度的概念,将具有足够邻近点的对象定义为核心对象,而这些点之间的连接定义了簇的边界。核心对象是其ϵ邻域(半径为r的邻域)内至少包含MinPts个点的对象。如果一个点在另一个核心点的r邻域内,它们之间就是直接密度可达,进而通过一系列直接密度可达的点可以形成密度可达的链,将整个簇连接起来。边界点是属于某个簇但不是核心点的点,而噪声点则是不被任何簇包含的点。DBSCAN的优点在于它不需要预先指定簇的数量,可以通过调整两个参数(半径ϵ和MinPts)来适应不同密度的区域。然而,选择合适的参数仍然需要一定的尝试和理解数据的特性。可视化工具可以帮助理解算法的聚类效果,例如通过观察K距离的变化和簇的形态。
K-MEANS和DBSCAN在聚类任务中各有优劣,K-MEANS适合简单、规则的簇结构,而DBSCAN则更善于处理复杂、异形的簇和噪声点。选择哪种算法取决于具体的数据特性和分析需求。
K-MEANS 算
法
聚类概念:
无监督问题:我们手里没有标签了
聚类:相似的东西分到一组
难点:如何评估,如何调参
下载后可阅读完整内容,剩余9页未读,立即下载
298 浏览量
2023-02-20 上传
256 浏览量
105 浏览量
2023-01-05 上传
207 浏览量
323 浏览量

猛男技术控
- 粉丝: 5w+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 传智播客教学:苏坤主讲骑士飞行棋C#开发教程
- Andy Harris著作:HTML5傻瓜书快速参考指南
- document-change-sketchplugin:处理文档变更的SketchJS示例插件
- 数字信号处理(DSP)原理与应用全面教学
- 户外线路跟踪利器:基于Google Map的Android线路记录器
- Swift通过CocoaPods动态生成直方图图表教程
- 软件学院实验:复数计算器的设计与实现
- STM32控制ENC28j60网络模块完整项目资料及程序
- Linux环境编译Java项目含第三方库包教程
- Leaflet.PolylineMeasure: 实现地理路径长度测量的JavaScript插件
- 使用Sketch-Predefined-Pages插件优化设计工作流程
- 淘淘商城前端开发资源包:JS、CSS代码解压即用
- iPhoneAxure组件资源库:免费下载iPhone主题设计
- 2440开发板硬件原理图详细解读
- 探索Swift动画开发:SHSnowflakes雪花飘落效果
- 施耐德编程软件:特维德PLC编辑器
