Python实现ID3决策树分类:从数据预处理到代码详解
本文将详细介绍如何在Python 3.4环境中使用ID3算法实现决策树分类。首先,文章提到了作者对原始数据集进行了调整,将其转换为英文以便于与matplotlib进行图形绘制。原始数据集包含年龄(age)、收入(input)、学生(student)和学习水平(level)四个特征,以及对应的类别标签。
决策树的构建流程从数据预处理开始,如load_data()函数中所示,它加载并定义了数据集和特征列表。该函数返回一个二维数组,其中包含了特征数据及其相应的特征名称。通过计算数据集中每个类别的纯度或不确定性,即熵(Entropy),来评估数据的分割质量。cal_entropy()函数就是用于计算熵的关键部分,输入数据集和类别列,输出整个数据集的熵值。
接下来,文章的核心是ID3算法的实现。ID3算法的核心思想是选择具有最大信息增益(Gain)的属性作为划分依据。信息增益衡量的是某个属性对决定最终类别有多大的帮助。通过递归地应用这个过程,直到达到某个停止条件(例如,所有样本属于同一类别,或者没有可用的属性可以继续划分),就形成了决策树。在Python代码中,这部分包括了选择最佳属性、创建子节点、并记录信息增益的过程。
具体实现时,首先导入所需的库,如numpy用于数值计算,pandas用于数据处理,math用于数学运算,operator则可能用于比较操作。然后,定义一个build_tree()函数,它接受数据集和当前考虑的属性列表作为参数。在该函数内部,会调用递归的divide_set()函数来实现属性划分,直到满足停止条件。
在divide_set()函数中,首先计算剩余属性的信息增益,然后根据信息增益选择最佳属性。接着,针对每个属性值,创建一个新的子集,并递归地对子集进行同样的操作,直到子集中的所有样本属于同一类别或者没有更多属性可选。这个过程通过一系列if-else语句和递归调用来完成。
最后,整个决策树的构建过程将生成一个树形结构,其中每个节点代表一个属性,分支表示属性的不同取值,叶子节点则代表最终的类别预测。通过这个决策树,我们可以对新的输入数据进行分类,只需沿着树的路径进行判断即可。
总结起来,这篇文章详细介绍了如何在Python中利用ID3算法实现决策树的分类方法,包括数据预处理、熵的计算、信息增益的选择以及决策树的递归构建过程。通过这个实例,读者可以更好地理解决策树分类的基本原理和其实现步骤。
python实现决策树分类实现决策树分类
上一篇博客主要介绍了决策树的原理,这篇主要介绍他的实现,代码环境python 3.4,实现的是ID3算法,首先为了后面
matplotlib的绘图方便,我把原来的中文数据集变成了英文。
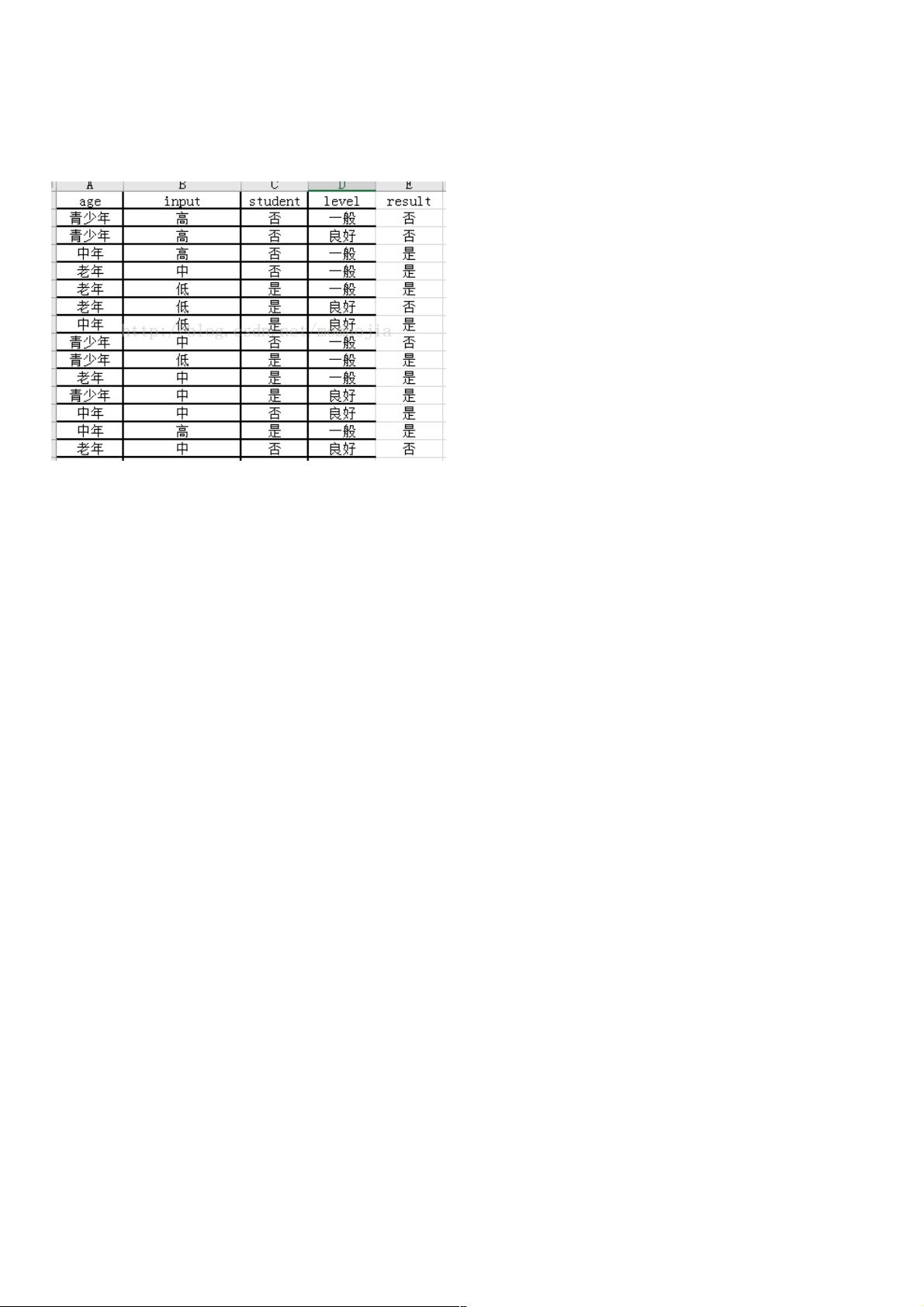
原始数据集:
变化后的数据集在程序代码中体现,这就不截图了
构建决策树的代码如下:
#coding :utf-8
'''
2017.6.25 author :Erin
function: "decesion tree" ID3
'''
import numpy as np
import pandas as pd
from math import log
import operator
def load_data():
#data=np.array(data)
data=[['teenager' ,'high', 'no' ,'same', 'no'],
['teenager', 'high', 'no', 'good', 'no'],
['middle_aged' ,'high', 'no', 'same', 'yes'],
['old_aged', 'middle', 'no' ,'same', 'yes'],
['old_aged', 'low', 'yes', 'same' ,'yes'],
['old_aged', 'low', 'yes', 'good', 'no'],
['middle_aged', 'low' ,'yes' ,'good', 'yes'],
['teenager' ,'middle' ,'no', 'same', 'no'],
['teenager', 'low' ,'yes' ,'same', 'yes'],
['old_aged' ,'middle', 'yes', 'same', 'yes'],
['teenager' ,'middle', 'yes', 'good', 'yes'],
['middle_aged' ,'middle', 'no', 'good', 'yes'],
['middle_aged', 'high', 'yes', 'same', 'yes'],
['old_aged', 'middle', 'no' ,'good' ,'no']] features=['age','input','student','level'] return data,features
def cal_entropy(dataSet):
'''
输入data ,表示带最后标签列的数据集
计算给定数据集总的信息熵
{'是': 9, '否': 5}
0.9402859586706309
'''
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
label = featVec[-1] if label not in labelCounts.keys():
labelCounts[label] = 0
下载后可阅读完整内容,剩余4页未读,立即下载
153 浏览量
2021-01-21 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-11-01 上传

weixin_38716519
- 粉丝: 13
- 资源: 910
 我的内容管理
展开
我的内容管理
展开







最新资源
- 稳定瓶:使瓶子或容器可以单手打开
- 重现经典的ibatis示例项目jpetstore,采用最新的springMVC+mybatis+mysql.zip
- coreos_on_ec2:一组 bash 脚本,用于在 EC2 上轻松启动 CoreOS 集群
- UseGDI绘图 vc++
- computer-database:我在Excilys实习期间进行的培训项目
- 73958319:关于我
- generic-serial-orchestrator
- 这是mysql的学习笔记.zip
- HPC-project:openMP,MPI和CUDA中生命游戏的并行化
- RealReactors:我的世界关于React堆的mod
- PetFlow
- even-odd-game
- jquery.fcs:使用 ENTER 键移动焦点、向前、向后和分组任何元素的 jQuery 插件
- Unal-Class-Chalenge
- 重新学习MySQL,不浮躁.zip
- winshop:一个受Microsoft Windows 10启发的小型轻量级Web桌面应用程序
