Spark调度机制深度解析
需积分: 9 33 浏览量
更新于2024-07-17
收藏 551KB PDF 举报
"Apache Spark 的调度原理深度解析"
在 Apache Spark 中,调度系统是其核心组件之一,它负责高效地分配任务到集群的各个工作节点上。这份资料深入剖析了 Spark 的调度机制,帮助读者更好地理解和优化 Spark 应用的性能。
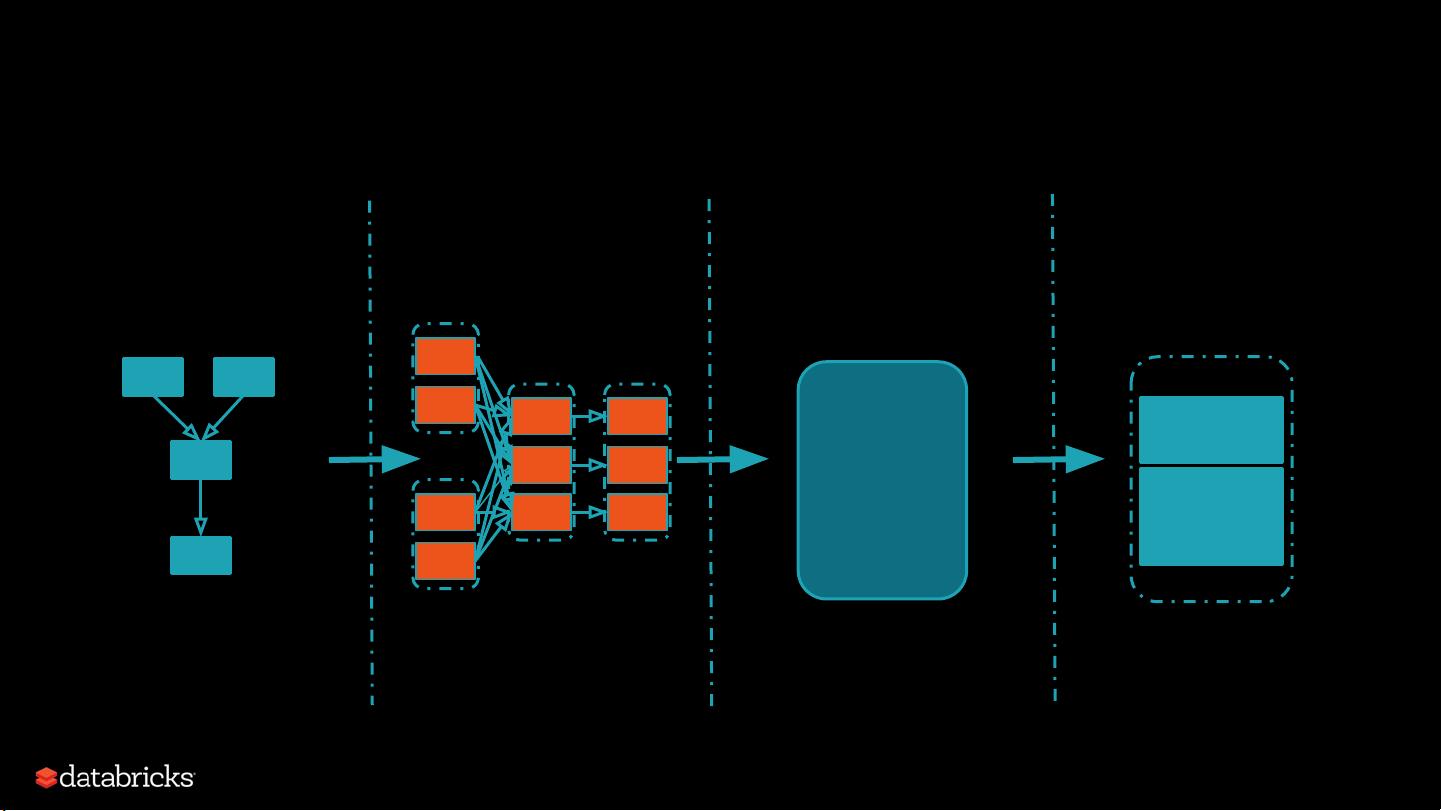
首先,Spark 的主要入口点是 `SparkContext`,它是所有 Spark 作业的起点。在初始化时,`SparkContext` 创建了 `SchedulerBackend`、`TaskScheduler` 和 `DAGScheduler`。`SparkContext` 提供了提交和取消作业的主要接口,如 `submitJob()` 和 `cancelJob()`。
`DAGScheduler`(Directed Acyclic Graph Scheduler)是负责将用户定义的 RDD 操作转换为一系列 Stage(有向无环图的阶段)。例如,在一个 `rdd1.join(rdd2).groupBy().filter()` 的操作中,DAGScheduler 可能会识别出三个 Stage:Stage0、Stage1 和 Stage2,每个 Stage 包含一组可以并行执行的任务(TaskSet)。`DAGScheduler` 还处理 Stage 间的依赖关系,如 Shuffle 依赖,以确保数据正确传递。
`TaskScheduler` 接管了 `DAGScheduler` 创建的 TaskSet,并负责将它们转化为具体的任务实例,然后提交给集群管理器(如 Standalone、YARN 或 Mesos)。`TaskScheduler` 可以根据不同的调度策略选择合适的任务执行策略,例如,粗粒度调度(CoarseGrainedSchedulerBackend)或者本地调度(LocalSchedulerBackend)。
`SchedulerBackend` 是与底层资源管理系统交互的接口,它负责任务的分配、监控和资源回收。对于粗粒度调度,每个 Worker 节点通常会保持一个长期运行的 Executor 进程,Executor 内部有多个线程来执行任务。这样可以避免频繁启动和停止进程的开销,提高效率。
在集群管理器中,`ClusterManager` 负责管理和调度资源,如工作节点(Worker)和内存、CPU 等资源。当 `TaskScheduler` 提交任务时,`ClusterManager` 将任务分发到空闲的 Executor 上。同时,`BlockManager` 作为分布式内存管理系统的一部分,负责在节点间移动数据,以满足任务的执行需求。
Spark 的调度系统是一个复杂而高效的框架,通过将复杂的计算任务拆分为可并行执行的 Stage 和 Task,再通过优化的调度策略,确保在分布式环境中快速、有效地完成计算。理解这些原理对于优化 Spark 作业性能、提高资源利用率以及解决可能出现的调度问题至关重要。

RDD → Stage
RDD
RDD
Shuffled
RDD
MapPartitions
RDD
Stage0 Stage1
rdd1.join(rdd2).groupBy(...).filter(...)
Shuffled
RDD
MapPartitions
RDD
Stage2
剩余35页未读,继续阅读
681 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

hellogogo
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 自动生成CAD模型文件的测试流程
- 掌握JavaScript中的while循环语句
- 宜科高分辨率编码器产品手册解析
- 探索3CDaemon:FTP与TFTP的高效传输解决方案
- 高效文件对比系统:快速定位文件差异
- JavaScript密码生成器的设计与实现
- 比特彗星1.45稳定版发布:低资源占用的BT下载工具
- OpenGL光源与材质实现教程
- Tablesorter 2.0:增强表格用户体验的分页与内容筛选插件
- 设计开发者的色值图谱指南
- UYA-Grupo_8研讨会:在DCU上的培训
- 新唐NUC100芯片下载程序源代码发布
- 厂家惠新版QQ空间访客提取器v1.5发布:轻松获取访客数据
- 《Windows核心编程(第五版)》配套源码解析
- RAIDReconstructor:阵列重组与数据恢复专家
- Amargos项目网站构建与开发指南
