深入理解Hadoop2.x:大数据处理的关键技术
需积分: 25 148 浏览量
更新于2024-07-18
收藏 12.67MB PPT 举报
"Hadoop介绍——深入浅出理解大数据处理框架"
Hadoop是一个开源的分布式计算框架,由Apache软件基金会维护,旨在实现对大规模数据集的高效、可靠和可伸缩的处理。Hadoop的诞生源于Google的一系列技术创新,尤其是Google File System (GFS)、MapReduce编程模型以及BigTable等大数据处理技术的启示。这些技术为解决海量数据存储和计算的问题提供了新的解决方案。
Hadoop的核心由两个主要组件组成:Hadoop Distributed File System (HDFS) 和 MapReduce。HDFS是分布式文件系统,设计目标是能在普通的硬件集群上存储和处理大量数据,提供高容错性和高吞吐量的数据访问。MapReduce则是一种并行计算模型,用于处理和生成大规模数据集,它将复杂的数据处理任务分解为“映射”(map)和“化简”(reduce)两个阶段,使得任务可以在多台机器上并行执行。
Hadoop的发展历程始于Doug Cutting创建的全文搜索库Lucene。随着Google的GFS和MapReduce论文发表,Doug Cutting受到启发,与其团队一起开发了Nutch,这是一个基于Lucene的搜索引擎项目。Nutch后来演变为包含DFS和MapReduce的Hadoop项目,最终在2005年成为Apache的顶级项目。
随着时间的推移,Hadoop生态系统不断扩展,包含了诸如HBase(分布式数据库)、YARN(资源调度器)、Hive(数据仓库工具)、Pig(数据分析平台)和Spark(快速计算引擎)等组件,为大数据处理提供了全面的解决方案。这些工具共同构建了一个强大的平台,支持各种大数据应用,如日志分析、推荐系统、实时流处理、机器学习等。
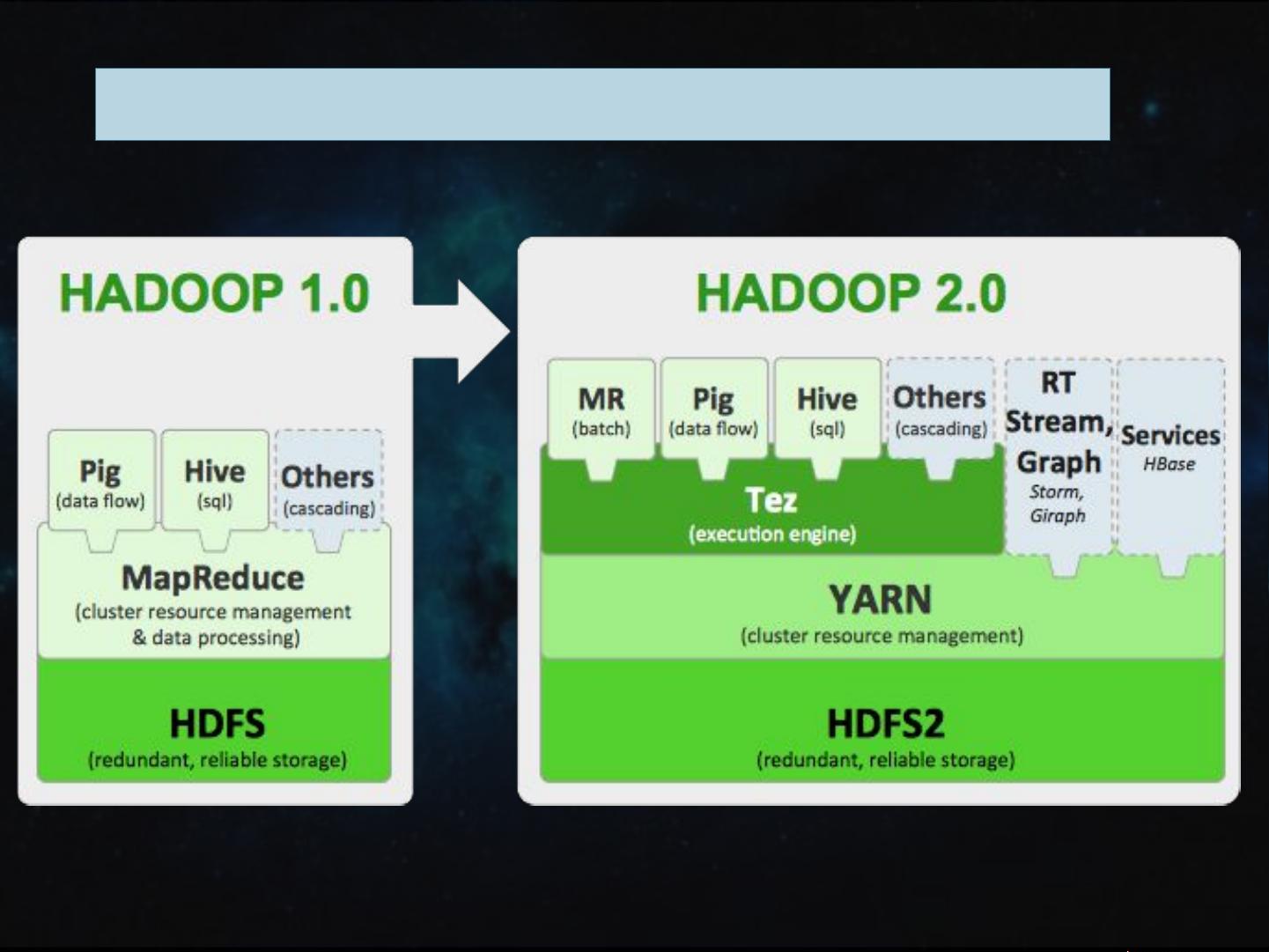
Hadoop 2.x版本引入了重要的改进,比如YARN(Yet Another Resource Negotiator),它分离了资源管理和计算任务调度,提高了系统的灵活性和资源利用率。此外,Hadoop 2.x还引入了HDFS的高可用性特性,通过NameNode的主备模式,确保了服务的连续性。
Hadoop不仅是一个分布式文件系统,更是一个大数据处理的生态系统,它改变了人们处理大规模数据的方式,为企业和研究机构提供了强大而灵活的数据处理能力。随着云计算的发展,Hadoop也逐渐融入云环境,提供了便捷的按需计算和存储服务,进一步推动了大数据时代的进步。

2019-02-21 上传
2023-07-13 上传
2023-04-06 上传
2023-07-14 上传
2023-06-12 上传
2024-02-03 上传
2023-05-09 上传

Easy618
- 粉丝: 7
- 资源: 31
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
