Tensorflow2.0实战:Kaggle Titanic生死预测教程
173 浏览量
更新于2024-08-29
收藏 338KB PDF 举报
"Tensorflow2.0在kaggle Titanic生死率预测的应用"
在这个项目中,我们看到如何使用Tensorflow2.0进行结构化数据建模,以预测在泰坦尼克号灾难中乘客的生存概率。这是一个典型的二分类问题,目标是根据给定的乘客信息,如年龄、性别、票价等,判断他们是否能在船只沉没后幸存。以下是整个建模流程的详细步骤:
一,准备数据
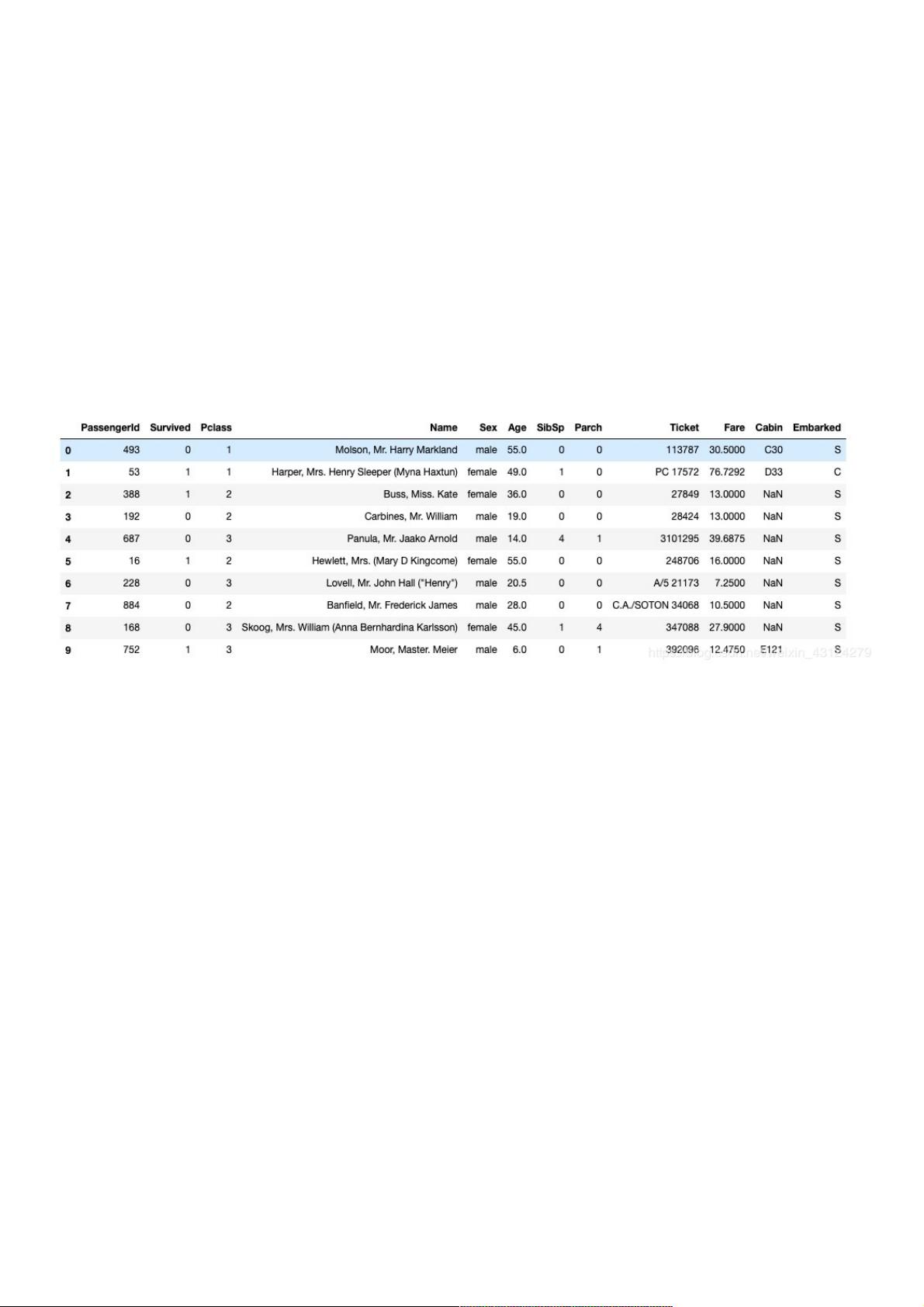
首先,我们导入必要的库,包括numpy、pandas和tensorflow。数据加载使用pandas的`read_csv`函数,将训练集和测试集分别存储在`dftrain_raw`和`dftest_raw`中。对数据进行初步查看以了解其结构。关键特征包括`Survived`(目标变量),`Pclass`(乘客等级,需one-hot编码),`Sex`(性别,转换为布尔特征),`Age`(年龄,可能有缺失值),`SibSp`(兄弟姐妹/配偶数量),`Parch`(父母/孩子数量),`Fare`(票价),以及`Embarked`(登船港口,需one-hot编码)。
在预处理阶段,需要处理缺失值,例如`Age`和`Embarked`,并创建新的特征,如`Age_isnull`表示年龄是否缺失,`Cabin_isnull`表示船舱信息是否缺失。同时,非数值特征如`Sex`和`Embarked`需要转化为数值或one-hot编码。
二,定义模型
使用Tensorflow2.0的Keras API构建模型。Keras提供了一种高级接口,用于快速构建和训练神经网络。可以创建一个Sequential模型,并逐层添加所需层,例如Dense层(全连接层)。对于这个二分类问题,可以选择激活函数为sigmoid的输出层,以得到0到1之间的概率值。
三,训练模型
在训练模型之前,需要对数据进行预处理,包括归一化、填充缺失值、one-hot编码等。然后,将数据分为训练集和验证集,以监控模型在未见过的数据上的表现。使用`compile`方法配置优化器(如Adam)、损失函数(如binary_crossentropy)和评估指标(如accuracy)。接着,通过`fit`方法进行模型训练,设置训练轮数(epochs)和批次大小(batch_size)。
四,评估模型
训练完成后,使用测试集评估模型性能。可以计算准确率、查准率、查全率、F1分数等指标。此外,绘制学习曲线以检查模型是否过拟合或欠拟合。
五,使用模型
对新数据进行同样的预处理步骤,然后使用训练好的模型进行预测。这一步通常涉及将新数据的特征转换为与训练数据相同的形式,然后通过模型的`predict`方法获得生存概率。
六,保存模型
为了将来能快速部署模型,将其保存为HDF5或其它可序列化的格式,以便于加载和使用。
在这个过程中,Tensorflow2.0提供了灵活性和效率,使得模型构建和训练更加直观。通过调整模型架构、优化器参数和训练策略,可以进一步优化模型性能,以达到更高的预测准确率。这个项目不仅展示了Tensorflow2.0的基础应用,也体现了在处理结构化数据时的数据预处理和模型调优的重要性。
【【Tensorflow2.0】】kaggle Titanic生死率预测生死率预测
目录目录前言1-1,结构化数据建模流程范例一,准备数据二,定义模型三,训练模型四,评估模型五,使用模型六,保存模型
前言前言
kaggle Titanic生死率预测–0.81准确率–python超详细数据分析–附源代码和报告的下载地址
该文章升级版本,以前是用sklearn进行的预测(机器学习),现在用Tensorflow2.0(深度学习)
1-1,结构化数据建模流程范例结构化数据建模流程范例
一,准备数据一,准备数据
titanic数据集的目标是根据乘客信息预测他们在Titanic号撞击冰山沉没后能否生存。
结构化数据一般会使用Pandas中的DataFrame进行预处理。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import models,layers
dftrain_raw = pd.read_csv('./data/titanic/train.csv')
dftest_raw = pd.read_csv('./data/titanic/test.csv')
dftrain_raw.head(10)
字段说明:
Survived:0代表死亡,1代表存活【y标签】
Pclass:乘客所持票类,有三种值(1,2,3) 【转换成onehot编码】
Name:乘客姓名 【舍去】
Sex:乘客性别 【转换成bool特征】
Age:乘客年龄(有缺失) 【数值特征,添加“年龄是否缺失”作为辅助特征】
SibSp:乘客兄弟姐妹/配偶的个数(整数值) 【数值特征】
Parch:乘客父母/孩子的个数(整数值)【数值特征】
Ticket:票号(字符串)【舍去】
Fare:乘客所持票的价格(浮点数,0-500不等) 【数值特征】
Cabin:乘客所在船舱(有缺失) 【添加“所在船舱是否缺失”作为辅助特征】
Embarked:乘客登船港口:S、C、Q(有缺失)【转换成onehot编码,四维度 S,C,Q,nan】
利用Pandas的数据可视化功能我们可以简单地进行探索性数据分析EDA(Exploratory Data Analysis)。
label分布情况
%matplotlib inline
%config InlineBackend.figure_format = 'png'
ax = dftrain_raw['Survived'].value_counts().plot(kind = 'bar',
figsize = (12,8),fontsize=15,rot = 0)
ax.set_ylabel('Counts',fontsize = 15)
ax.set_xlabel('Survived',fontsize = 15)
plt.show()
下载后可阅读完整内容,剩余6页未读,立即下载
2020-12-21 上传
2018-08-14 上传
2021-01-20 上传
2018-07-31 上传
2020-05-02 上传
2021-07-06 上传
2021-05-18 上传
2021-04-05 上传
2021-03-14 上传

weixin_38690545
- 粉丝: 4
- 资源: 927
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新代数控API接口实现CNC数据采集技术解析
- Java版Window任务管理器的设计与实现
- 响应式网页模板及前端源码合集:HTML、CSS、JS与H5
- 可爱贪吃蛇动画特效的Canvas实现教程
- 微信小程序婚礼邀请函教程
- SOCR UCLA WebGis修改:整合世界银行数据
- BUPT计网课程设计:实现具有中继转发功能的DNS服务器
- C# Winform记事本工具开发教程与功能介绍
- 移动端自适应H5网页模板与前端源码包
- Logadm日志管理工具:创建与删除日志条目的详细指南
- 双日记微信小程序开源项目-百度地图集成
- ThreeJS天空盒素材集锦 35+ 优质效果
- 百度地图Java源码深度解析:GoogleDapper中文翻译与应用
- Linux系统调查工具:BashScripts脚本集合
- Kubernetes v1.20 完整二进制安装指南与脚本
- 百度地图开发java源码-KSYMediaPlayerKit_Android库更新与使用说明
