Apriori算法实战:Java实现数据挖掘关联规则与频繁项集
需积分: 9 48 浏览量
更新于2024-07-27
1
收藏 205KB DOC 举报
本资源是一份关于数据挖掘Java源程序的教程,旨在帮助学习者深入理解和实践关联规则算法。实验的主要目标包括理解关联规则生成过程、Apriori算法的应用以及如何处理频繁项集和关联规则的生成。实验环境设定在Windows操作系统下的编程环境中。
实验的核心内容包括三个步骤:
1. Apriori算法的实现:首先,通过模拟数据集利用Apriori算法找出频繁项集,用户需要设置最小的支持度阈值,例如,当设置为2时,会得到相应的频繁项集示例。
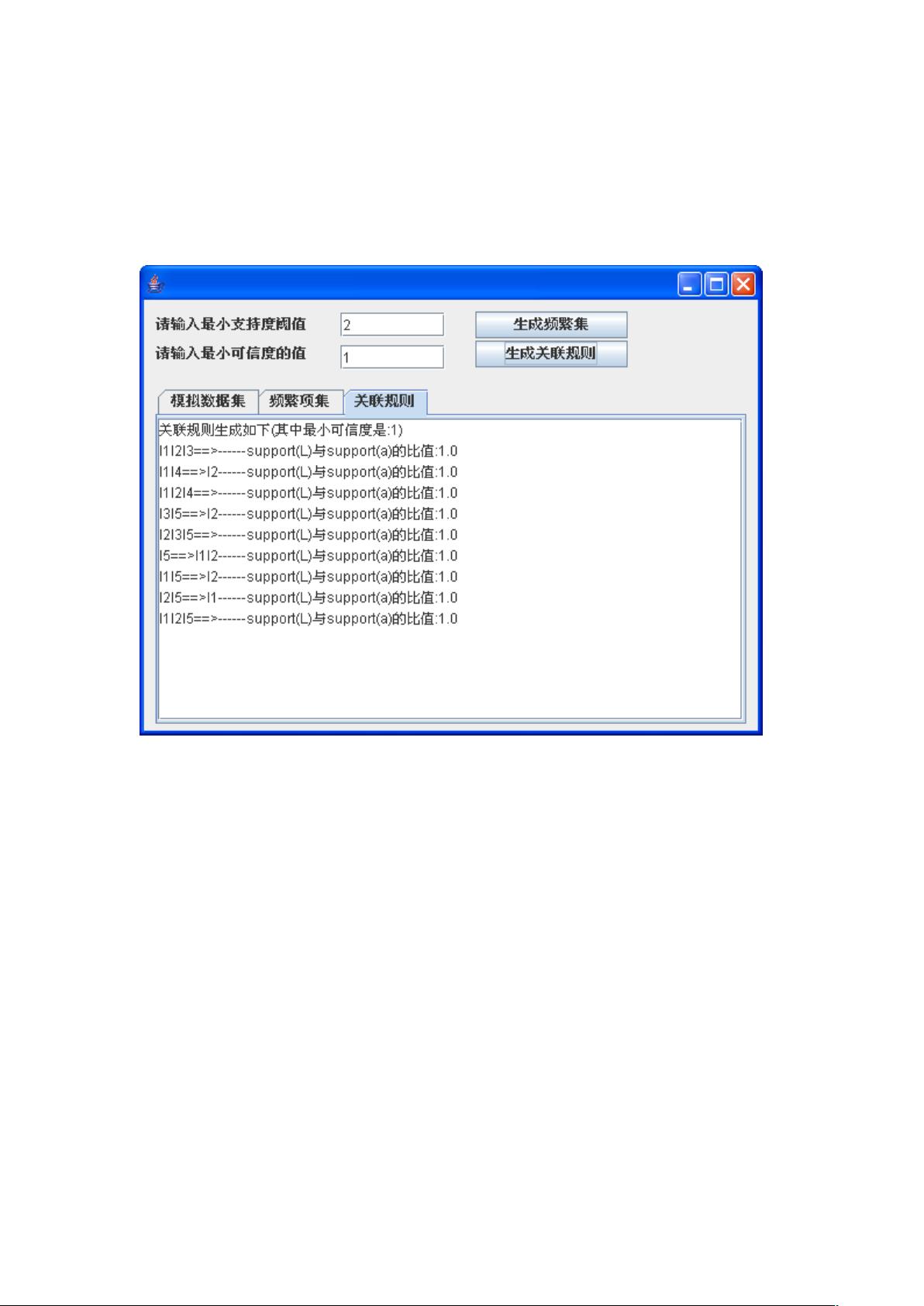
2. 生成关联规则:基于频繁项集,进一步生成关联规则。用户可以调整最小可信度阈值来控制规则的生成,如设置为1,可以看到生成的关联规则实例。
3. 问题与心得:实验中可能会遇到数据输入的问题,但通过实践,学习者能够加深对Apriori算法的理解,以及整个数据挖掘过程的构建。
在实验中,两个关键参数起着重要作用:
- 最小支持度阈值:决定了哪些项集被认为是频繁的,它与频繁项集的数量有直接关系,阈值越高,结果中包含的项集数量会减少。
- 最小可信度阈值:用于筛选关联规则的可靠性,设置较低的阈值将导致更多的规则被发现,但可能包含噪声或非实质性的联系。
在算法实现部分,使用了哈希表和二维数组作为核心数据结构,以高效存储和处理数据。伪代码展示了算法的基本流程,包括频繁项集的查找、候选集的生成和剪枝等关键步骤。源代码中包含详细的注释,使得理解和调试变得更加直观。
通过这个实验,学习者不仅能够掌握Apriori算法的具体操作,还能了解到数据挖掘项目中实际应用的策略和技巧,提升编程和数据分析能力。
最小支持度阈值表示数据项集在统计意义上的最低主要性,小于最低支持度的数据项
将会被丢弃,将影响频繁项集的结果。
2. 请设置不同的最小可信度阈值,观察得到的关联规则的数目,说说关联规则与最
小可信度阈值之间的关系。
答:输入的最小可信度的值为 1,生成的关联规则如下:
最小可信度阈值表示规则的最低可靠性,小于该设定的可靠性值的规则将会被丢弃。
3. 详细介绍各算法的流程图和所用到的数据结构,并附带源代码(源代码中应有必
要的注释信息)。
答:(1)算法用到的数据结构:哈希表和二维数组。
(2)算法的伪代码描述如下:
输入:交易数据库 D;最小支持度阈值 min_sup。
输出:D 中的频繁项集 L。
方法:
(1) L1=nd_frequent_1_itemset(D);找频繁项集 1-项集;
(2) for ( k=2; L
k-1
X <; min_sup)
{ apriori_gen(L
k-1
,min_sup) 连接和剪枝。用于在
第 k-1 次遍历中生成的 L
k-1
生成 C
k
for each t| D 扫描数据库,确定每个候选项集的支持频度
{ C
t
=subset(C
k
,t)获得 t 所包含的候选项集
for each cÎC
t
c.count++;
} }
(3) L
k
={ c ÎC
k
| c.count > min_sup }由 C
k
生成 L
k
剩余17页未读,继续阅读
2017-09-16 上传
192 浏览量
2023-04-07 上传
2021-05-20 上传
2017-09-16 上传
2020-08-31 上传
162 浏览量
2010-11-04 上传
2022-09-24 上传

闻道java
- 粉丝: 6
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
