CUDA架构下的矩阵乘法优化与加速研究
29 浏览量
更新于2024-08-31
2
收藏 194KB PDF 举报
"本文主要研究了基于CUDA架构的矩阵乘法实现及其优化,通过在GPU上运用CUDA技术,实现矩阵乘法的高效计算。实验结果显示,CUDA矩阵乘法相较于CPU有显著的加速效果,最高加速比达1079.64,峰值比最高为30.85%,充分展示了GPU的浮点运算能力。CUDA编程模型允许CPU和GPU协同工作,CPU处理逻辑控制,GPU专注大规模并行计算,提高了整体计算效率。"
在当前计算领域,随着多核CPU和GPU的发展,计算模式已经转向CPU与GPU协同处理。CUDA作为一种由NVIDIA推出的统一计算设备架构,极大地增强了GPU的可编程性,使得GPU不再局限于图形渲染,而是能够应用于各种通用计算任务,包括矩阵乘法等高计算量的运算。
矩阵乘法是计算科学中的基础操作,尤其在图像处理、机器学习和科学计算等领域中不可或缺。然而,传统CPU在处理大规模矩阵乘法时,由于其架构限制,效率较低。相比之下,GPU因其并行计算能力强、浮点运算单元众多,成为解决此类问题的理想选择。在CUDA架构下,GPU的每个流多处理器(SM)包含多个流处理器(SP),可以同时处理大量数据,从而实现高效并行计算。
CUDA编程模型将CPU定义为主机,负责管理和调度任务,而GPU作为设备,执行计算密集型任务。这种分离使得CPU可以专注于串行逻辑控制,GPU则专注于执行并行计算,两者互补,实现了计算性能的大幅提升。在矩阵乘法的实现中,作者可能采用了两种不同的CUDA实现策略,并对其进行优化,以充分利用GPU的硬件资源。
实验结果显示,基于CUDA的矩阵乘法相比CPU矩阵乘法,不仅速度提升明显,而且在GPU的浮点运算能力利用率上也表现出色。加速比高达1079.64意味着GPU执行相同任务的速度比CPU快了近1080倍,而30.85%的峰值比表示GPU在计算过程中接近了其理论最大计算能力的三分之一,这在实际应用中是非常高的效率。
CUDA架构为解决大规模计算问题提供了新的途径,通过优化矩阵乘法等算法,可以在GPU上实现高效计算,显著提升了计算效率。这种技术的应用对于需要大量计算的领域具有重要意义,未来有望在更多领域得到推广和应用。
基于基于CUDA架构矩阵乘法的研究架构矩阵乘法的研究
首先介绍了CUDA架构特点,在GPU上基于CUDA使用两种方法实现了矩阵乘法,并根据CUDA特有的软硬件架
构对矩阵乘法进行了优化。然后计算GPU峰值比并进行了分析。实验结果表明,基于CUDA的矩阵乘法相对于
CPU矩阵乘法获得了很高的加速比,最高加速比达到1 079.64。GPU浮点运算能力得到有效利用,峰值比最高
达到30.85%。
摘摘 要:要: 首先介绍了
关键词:关键词: CUDA;矩阵乘法;加速比;峰值比
随着多核CPU和众核GPU的快速发展,计算行业正在从只使用CPU的“中央处理”向CPU与GPU并用的“协同处理”发展,并
行系统已成为主流处理器芯片。传统的GPU架构受其硬件架构的影响不能有效利用其资源进行通用计算,NVIDIA(英伟达)公
司推出的统一计算设备架构CUDA(Compute Unified Device Architecturem),使得GPU具备更强的可编程性,更精确和更高的
性能,应用领域也更加广泛。
矩阵乘法是一种大计算量的算法,也是很耗时的运算。CPU提高单个核心性能的主要手段比如提高处理器工作频率及增加
指令级并行都遇到了瓶颈,当遇到运算量大的计算,CPU进行大矩阵的乘法就变得相当耗时,运算效率很低下。因此,GPU凭
借其超强计算能力应运而生,让个人PC拥有了大型计算机才具备的运算能力。本文运用GPU的超强计算能力在CUDA架构上
实现了大矩阵乘法。
1 CUDA架构架构
NVIDIA及时推出CUDA这一编程模型,在应用程序中充分结合利用CPU和GPU各自的优点,特别是GPU强大的浮点计算能
力。CPU主要专注于数据高速缓存(cache)和流处理(flow control),而GPU更多地专注于计算密集型和高度并行的计算。尽管
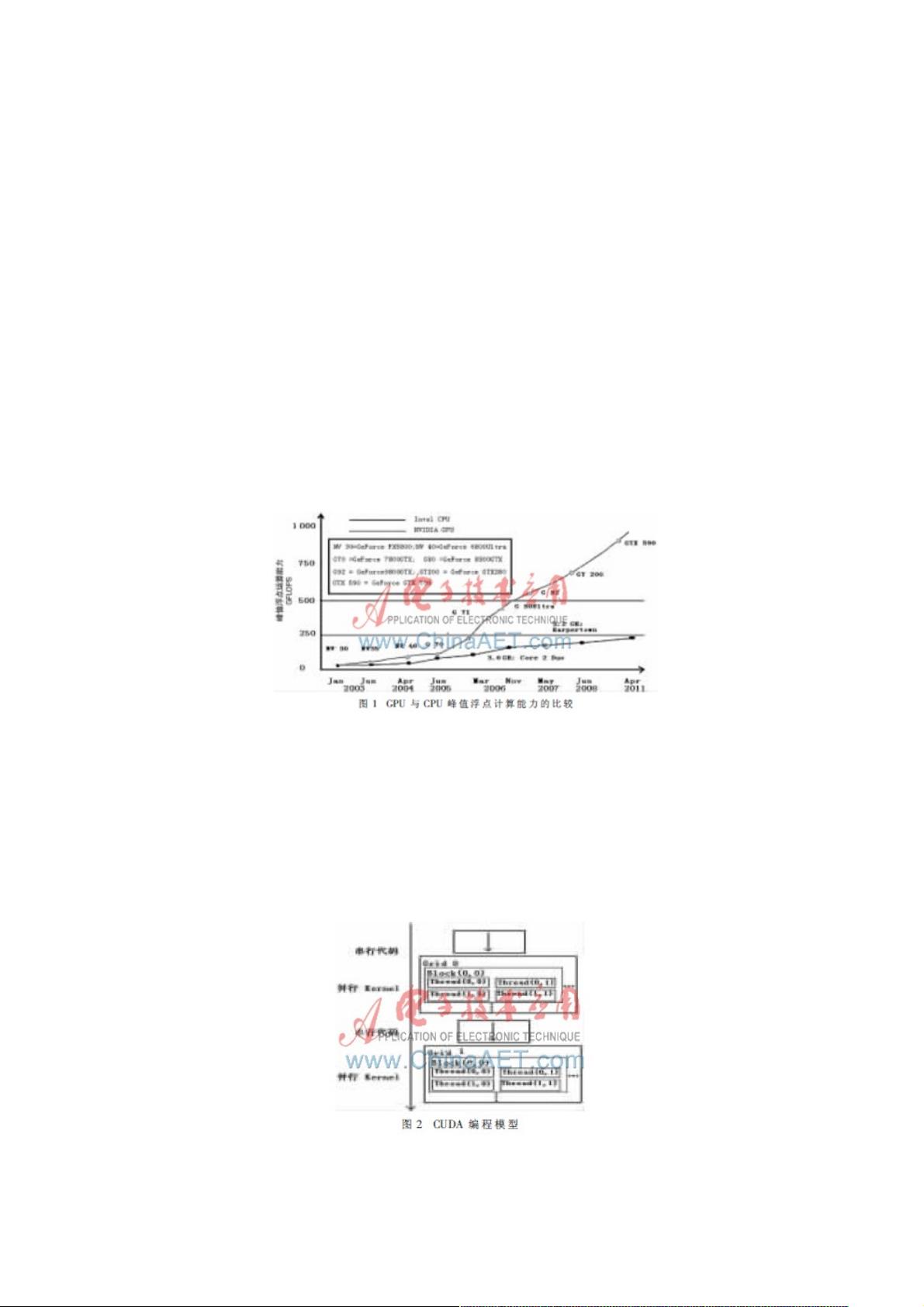
GPU的运行频率低于CPU,但GPU凭着更多的执行单元数量使其在浮点计算能力上获得较大优势[1]。当前的NVIDIA GPU中
包含完整前端的流多处理器(SM),每个SM可以看成一个包含8个1D流处理器(SP)的SIMD处理器。主流GPU的性能可以达到
同期主流CPU性能的10倍左右。图1所示为GPU与CPU峰值浮点计算能力的比较。
CUDA的编程模型是CPU与GPU协同工作,CPU作为主机(Host)主要负责逻辑性强的事务处理及串行计算,GPU作为协处
理器或者设备(Device)负责密集型的大规模数据并行计算。一个完整的CUDA程序=CPU串行处理+GPU Kernel函数并行处
理。
一个CUDA架构下的程序分为两个部分,即上述的Host端和Device端。通常情况下程序的执行顺序如下:Host端程序先在
CPU上准备数据,然后把数据复制到显存中,再由GPU执行Device端程序来处理这些数据,最后Host端程序再把结束运算后
的数据从显存中取回。
图2为CUDA编程模型,从中可以看出,Thread是GPU执行运算时的最小单位。也就是说,一个Kernel以线程网格Grid的形
式组织,每个Grid由若干个线程块Block组成,而每个线程块又由若干个线程Thread组成。一个Kernel函数中会存在两个层次
的并行,Grid中Block之间的并行和Block中Thread之间的并行,这样的设计克服了传统GPGPU不能实现线程间通信的缺点
[2]。
同一个Block下的Thread共用相同的共享存储器,通过共享存储器交换数据,并通过栅栏同步保证线程间能够正确地共享数
据。因此,一个Block下的Thread虽然是并行的,但在同一时刻执行的指令并不一定都相同,实现了不同Thread间的协同合
作。这一特性可以显著提高程序的执行效率,并大大拓展GPU的适用范围。
2 基于基于CUDA架构矩阵乘法的实现架构矩阵乘法的实现
2.1 一维带状划分一维带状划分
给定一个M×K的矩阵A和一个K×N的矩阵B,将矩阵B乘以矩阵A的结果存储在一个M×N的矩阵C中。此种矩阵乘法使用了一
下载后可阅读完整内容,剩余3页未读,立即下载
2010-02-21 上传
2018-05-04 上传
2011-07-07 上传
2021-10-10 上传
2012-12-01 上传
2012-11-23 上传
点击了解资源详情

weixin_38643307
- 粉丝: 8
- 资源: 925
 我的内容管理
展开
我的内容管理
展开







最新资源
- EventBus:事件总线
- raspberry
- 提取均值信号特征的matlab代码-Challenge2021_firstunofficial:Challenge2021_firstunof
- Fire-Detection:该项目的重点是尽早尝试识别和检测火灾。 那是从烟雾开始的地方。
- 程序猿ProMonkey V2.03
- LeetCode:LeetCode刷题
- pics
- tongxunlu,条形码嵌入式c语言生成源码,c语言程序
- ud_handles:轴/图形孩子的管理。-matlab开发
- OkeTerraform
- UrduSearchingDictionory.java
- LevelClientEvIO:ev.io客户端
- 提取均值信号特征的matlab代码-second_unofficial_entry2021:second_unofficial_entry20
- MusicCD,c语言socks5源码分析,c语言程序
- sphinx-php:我的Sphinx扩展
- 基于Spring + Spring MVC + MyBatis的图书馆管理系统,使用Maven进行包管理 主要功能包括:图书查询
