《红楼梦》统计分析:文笔鉴赏与风格变化
需积分: 1 13 浏览量
更新于2024-07-15
收藏 1.04MB PPTX 举报
"《用统计分析对《红楼梦》进行文笔鉴赏》答辩PPT.pptx" 是一份关于利用数理统计方法分析《红楼梦》文笔风格的研究报告,主要涉及了单因素方差分析、多元线性回归和秩和检验等统计学工具。
在这项研究中,作者吴彬首先探讨了《红楼梦》中同一作者使用的高频汉字的稳定性。通过分析1-80回的前100个高频字符,发现这些高频字符的种类相对稳定,并且前80回中的前100个高频字符占据了篇幅的60.05%。进一步分析显示,筛选出的79个高频汉字在曹雪芹所著部分占篇幅的比例超过一半。为了研究这些高频汉字在不同回数中的分布差异,采用了单因素方差分析。通过对每一回抽取样本进行统计,发现这些高频字在各回的出现密度存在显著差异。
接下来,研究者运用Kolmogorov-Smirnov拟合优度检验,探究了筛选后的79个高频汉字在每相邻5回中的密集程度差异,结果表明曹雪芹的文笔风格可能在5个回数内有显著变化,体现了其深厚的文学功底。这一发现也暗示《红楼梦》前80回中可能存在显著的情感和内容差异。
此外,研究还关注了句子长度的分布。通过对逗号、句号等标点符号进行句长划分标准,发现句长为4和6的句子频数最多,约占所有1到20句长句子的30.12%,这反映了《红楼梦》文风的短促有力和骈散结合的特点。通过统计不同长度句子在各部分(1-40回,41-80回,81-120回)的频数,发现各部分的句子长度分布比例相当稳定,但在句长为4、5、6的位置,不同部分之间存在显著差异,这表明三个部分在骈句和俪句的使用上有所区别。
最后,研究者试图找出句子长度频数与每个回的字符数之间的关系,可能采用的是多元线性回归模型(OLSRegressionResults)来分析这种潜在的相关性。这有助于揭示《红楼梦》文本结构的内在规律和作者在创作时的技巧运用。
这项研究通过统计分析揭示了《红楼梦》在词汇使用、句型结构等方面的独特性,展示了统计方法在文学鉴赏领域的应用价值。它不仅有助于理解曹雪芹的文笔风格,也为后续的文学作品分析提供了新的研究途径。
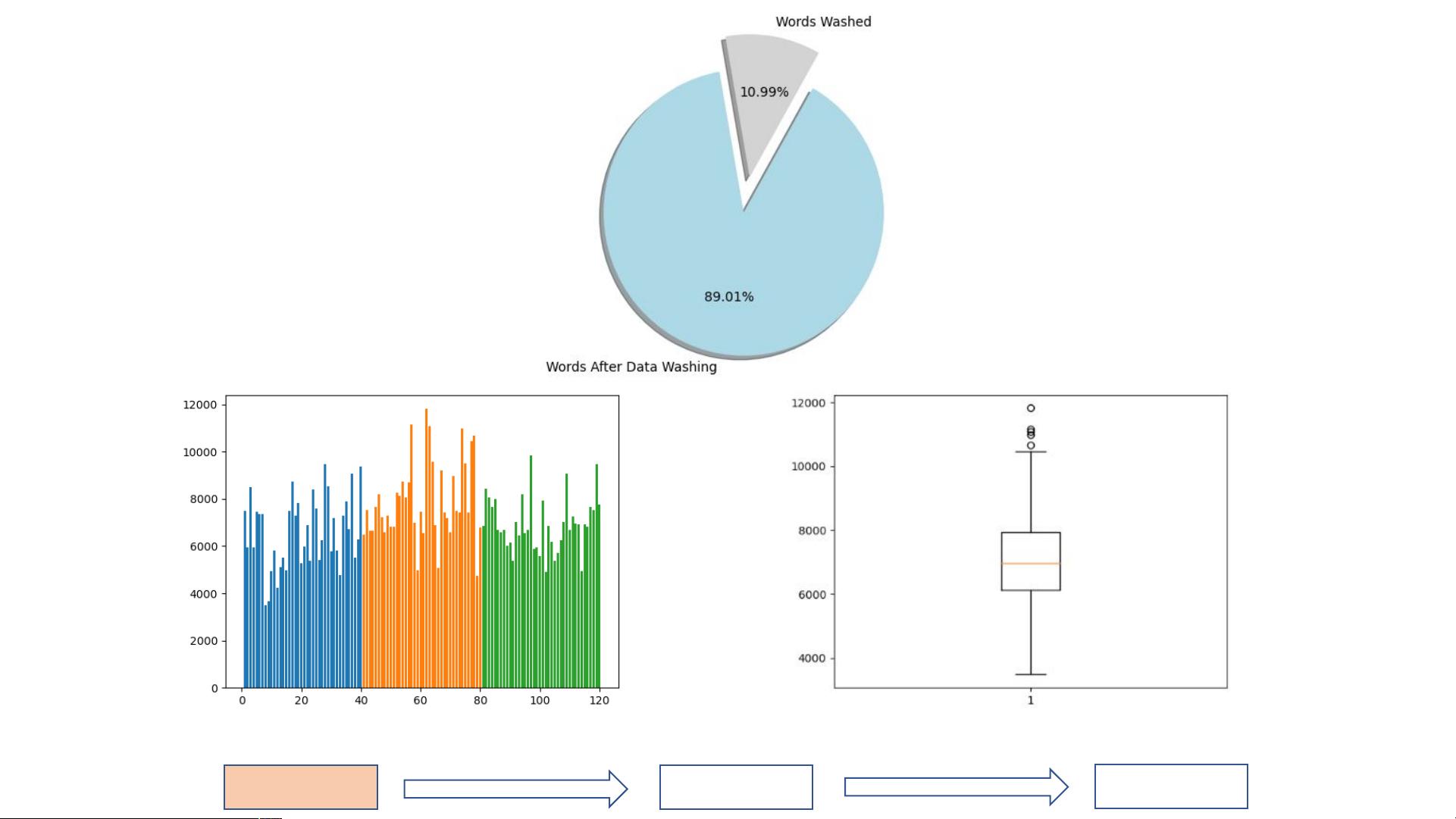
数据准备
文笔赏析
作者身份
剩余22页未读,继续阅读
2024-10-28 上传
2023-02-26 上传
2023-03-26 上传
2024-10-26 上传
2023-05-26 上传
2023-03-30 上传

此账号已停更
- 粉丝: 216
- 资源: 39
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python库 | mtgpu-0.2.5-py3-none-any.whl
- endpoint-testing-afternoon:一个下午的项目,以帮助使用Postman巩固测试端点
- 经济中心
- z7-mybatis:针对mybatis框架的练习,目前主要技术栈包含springboot,mybatis,grpc,swgger2,redis,restful风格接口
- Cloudslides-Android:云幻灯同步演示应用-Android Client
- testingmk:做尼采河
- ecom-doc-static
- kindle-clippings-to-markdown:将Kindle的“剪贴”文件转换为Markdown文件,每本书一个
- 减去图像均值matlab代码-TVspecNET:深度学习的光谱总变异分解
- 自动绿色
- Alexa-Skills-DriveTime:该存储库旨在演示如何建立ALEXA技能,以帮助所有人了解当前流量中从源头到达目的地所花费的时间
- 灰色按钮克星易语言版.zip易语言项目例子源码下载
- HTML5:基本HTML5
- dubbadhar-light
- 使用Xamarin Forms创建离线移动密码管理器
- matlab对直接序列扩频和直接序列码分多址进行仿真实验源代码
