NVIDIA Fermi架构白皮书中文翻译详解
需积分: 10 132 浏览量
更新于2024-09-17
收藏 546KB PDF 举报
"Fermi+白皮书中文翻译v0.1版本"
NVIDIA的Fermi架构是继G80和GT200之后的又一重大GPU设计革新,专为通用计算和高性能图形处理而打造。G80是NVIDIA首次推出的通用计算GPU,能够同时处理图形和并行计算任务,而GT200在此基础上进行了扩展。Fermi架构则是基于用户对G80和GT200使用经验的反馈,几乎从头设计,以满足更高效能和功能的需求。
Fermi架构的主要设计改进点包括:
1. **大幅提升单精度计算性能**:Fermi提供了比桌面CPU快约10倍的单精度计算速度,同时也强化了双精度运算能力,这对于需要高精度计算的应用至关重要。
2. **引入ECC内存**:Fermi引入了错误校验和纠正(ECC)内存技术,增强了内存的容错能力,确保数据处理的准确性。
3. **增强内存访问效率**:考虑到并非所有并行计算都需要共享内存,Fermi增加了内存访问的缓存功能,以优化那些不依赖共享内存的计算任务。
4. **增加SM共享内存**:为了满足某些CUDA程序的需求,Fermi的每个流式多处理器(SM)的共享内存容量提升至16KB以上,以提高计算速度。
5. **快速资源切换**:Fermi优化了应用程序和图形显示间的资源切换,减少了延迟,提升了用户体验。
6. **加速原子操作**:通过改进的原子读写操作,Fermi能够更有效地执行并行程序,提升整体计算效率。
在硬件层面,Fermi架构的主要更新有:
- **第三代Streaming Multiprocessor (SM)**:每个SM包含32个CUDA核心,是GT200的四倍,且双精度浮点计算能力是其八倍。引入了双线程 warp调度,能够在单个时钟周期内启动两个线程块进行计算,提高了并发性。
- **第二代线程并行计算ISA架构**:实现了统一的地址空间,全面支持C++特性,优化了对OpenCL和DirectCompute的支持,使编程更加灵活和高效。
此外,每个SM还配备了64KB的RAM,可配置为共享内存或L1缓存,以适应不同的计算需求。
Fermi架构的这些改进不仅提升了GPU的计算能力,还加强了其在科学计算、数据分析、深度学习和图形渲染等领域的应用潜力,为后来的GPU设计奠定了坚实基础。
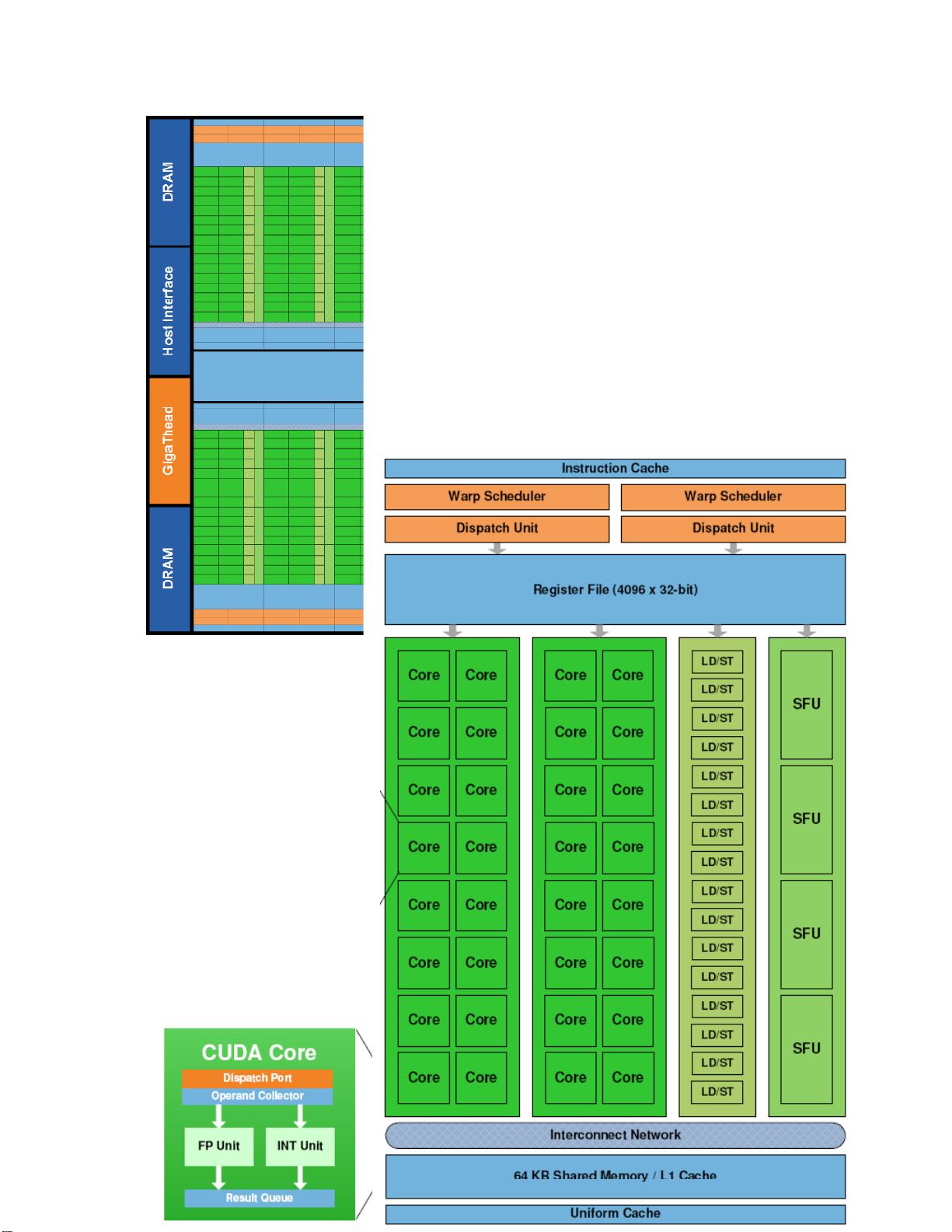
Third Generation
Streaming
Multiprocessor
第三代的 SM 架构不只是增强
了 SM 的计算能力,同时使得
可编程性和效率得到提高。
512个高性能的CUDA
计算core
每一个 SM 都包含 32 个 CUDA
计算 core,是以前架构的 4
每一个 core 都有完整的整数
倍。
剩余13页未读,继续阅读
141 浏览量
129 浏览量
397 浏览量
141 浏览量
167 浏览量
392 浏览量
109 浏览量
点击了解资源详情
213 浏览量

weizhen861207
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- ASP.NET集成支付宝即时到账支付流程详解
- C++递推法在解决三道经典算法问题中的应用
- Qt_MARCHING_CUBES算法在面绘制中的应用
- 传感器原理与应用课程习题解答指南
- 乐高FLL2017-2018任务挑战解析:饮水思源
- Jquery Ui婚礼祝福特效:经典30款小型设计
- 紧急定位伴侣:蓝光文字的位置追踪功能
- MATLAB神经网络实用案例分析大全
- Masm611: 安全高效的汇编语言调试工具
- 3DCurator:彩色木雕CT数据的3D可视化解决方案
- 聊天留言网站开发项目全套资源下载
- 触摸屏适用的左右循环拖动展示技术
- 新型不连续导电模式V_2控制Buck变换器研究分析
- 用户自定义JavaScript脚本集合分享
- 易语言实现非主流方式获取网关IP源码教程
- 微信跳一跳小程序前端源码解析
