Python性能优化24式:从分析到加速
5 浏览量
更新于2024-07-15
收藏 1MB PDF 举报
本文主要总结了24种优化Python代码速度的方法,涵盖了代码分析、数据结构选择、循环优化、函数优化、标准库利用、高阶函数应用、numpy库的使用、Pandas操作优化以及并行计算等多个方面。
一、代码运行时间分析
1. 测算代码运行时间:Python内置的`time`模块可以用来测量代码运行时间,但Jupyter环境中, `%timeit` 和 `%time` 魔术命令提供了更便捷的方式。
2. 测算多次运行平均时间:可以使用循环结合`time`模块来计算多次运行的平均时间,Jupyter环境中的`%timeit -n` 可以自动执行多次并计算平均值。
3. 按调用函数分析:`cProfile`模块用于函数级别的性能分析,Jupyter环境下的`%prun` 提供了类似功能。
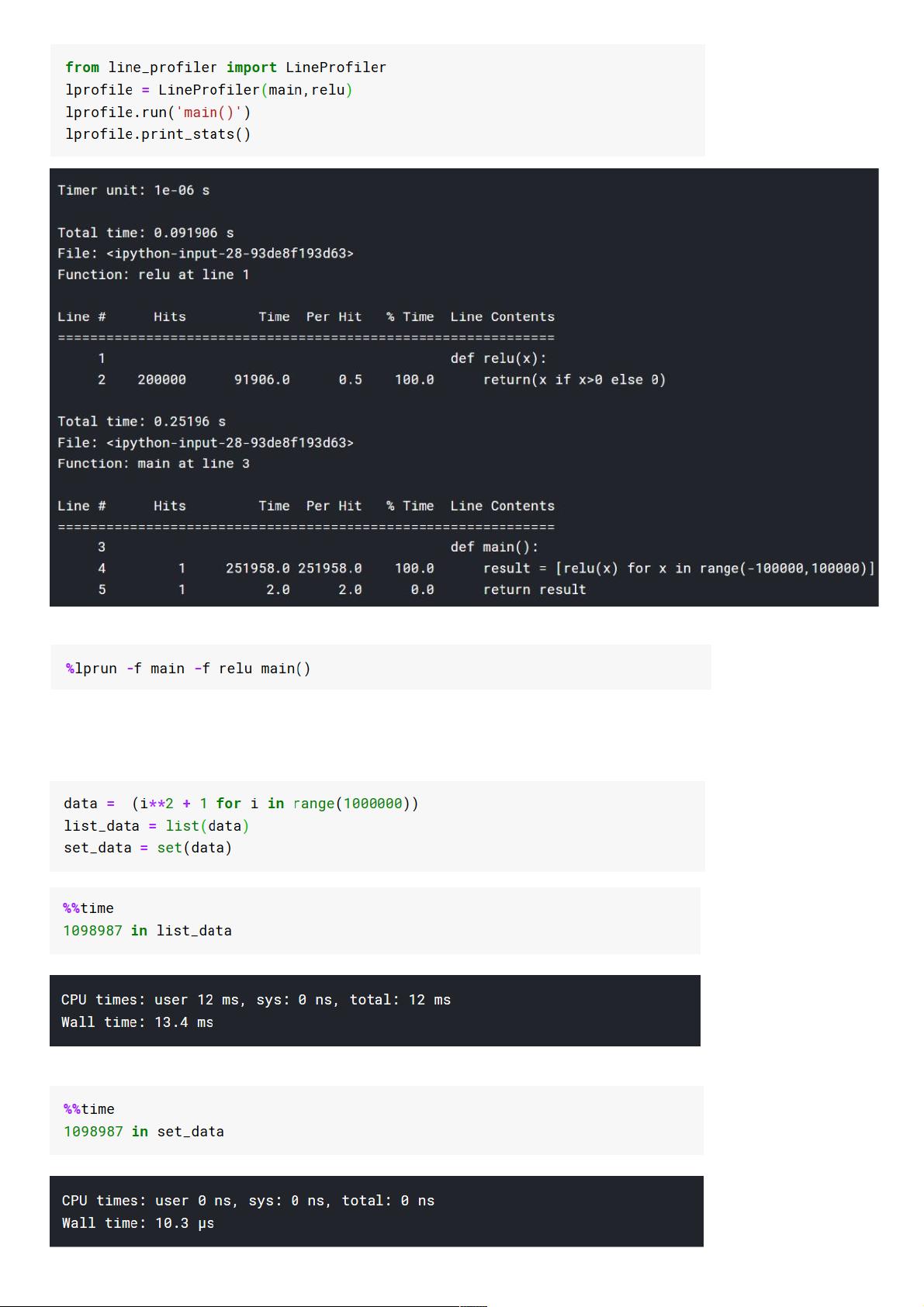
4. 按行分析代码运行时间:`line_profiler`库可以显示代码每一行的运行时间,与Jupyter的`%lprun` 结合使用非常方便。
二、数据结构选择
5. 使用`set`代替`list`进行查找:`set`的数据结构使得查找操作更快,因为其内部基于哈希表实现,时间复杂度为O(1)。
6. 使用`dict`代替两个`list`进行匹配查找:`dict`的键值对查找效率远高于两个`list`的线性查找。
三、循环优化
7. 优先使用`for`循环:在多数情况下,`for`循环比`while`循环更简洁且效率更高。
8. 在循环体中避免重复计算:如果某个值在循环中会被反复计算,可将其预先计算并存储,减少不必要的计算。
四、函数优化
9. 用循环机制代替递归函数:递归虽然优雅,但可能导致栈溢出,循环通常更为高效。
10. 用缓存机制加速递归函数:`functools.lru_cache` 可以缓存函数结果,避免重复计算,提升递归性能。
11. 用`numba`加速Python函数:`numba`库能将Python函数转换为机器码,显著提高运行速度。
五、使用标准库函数进行加速
12. `collections.Counter`加速计数:对于计数操作,`Counter`提供了高效的实现。
13. `collections.ChainMap`加速字典合并:`ChainMap`可以快速合并多个字典,避免了复制操作。
六、高阶函数应用
14. 使用`map`代替推导式:`map`函数可以并行处理序列,对于大量数据操作更有效率。
15. 使用`filter`代替推导式:`filter`函数同样可以并行处理,适用于筛选操作。
七、numpy向量化操作
16. 使用`np.array`代替`list`:`numpy`数组支持高效数组运算,适合大数据操作。
17. 使用`np.ufunc`代替`math.func`:`numpy`的通用函数(ufunc)对数组操作有优化,速度快于常规的数学函数。
18. 使用`np.where`代替`if`:`np.where`能够快速地根据条件返回数组的不同部分。
八、Pandas优化
19. 使用csv文件读写代替excel文件读写:csv文件体积小,读写速度更快。
20. 使用`pandas`的`pandarallel`工具:可以实现DataFrame操作的多核并行计算。
九、使用Dask进行加速
21. 使用`dask`加速`dataframe`:Dask提供分布式DataFrame,适合大数据处理。
22. 使用`dask.delayed`进行加速:`dask.delayed`可以将任务分解为延迟计算的任务,便于并行执行。
十、并行计算加速
23. 应用多线程加速IO密集型任务:Python的`concurrent.futures.ThreadPoolExecutor`可用于多线程执行IO密集型任务。
24. 应用多进程加速CPU密集型任务:`multiprocessing`库的`Pool`类可用于多进程计算,充分利用多核处理器资源。
这些优化策略旨在帮助开发者提升Python代码的执行效率,实现更流畅、更快速的程序运行。
快捷方法(jupyter环境)
二,加速你的查找二,加速你的查找
第第5式,用式,用set而非而非list进行查找进行查找
低速方法
高速方法
剩余14页未读,继续阅读
2336 浏览量
4106 浏览量
1478 浏览量
2020-09-21 上传
579 浏览量
点击了解资源详情
点击了解资源详情
215 浏览量
点击了解资源详情

weixin_38688956
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java源码实战经典:随书源码解析
- Java PDF生成器iText开源jar包集合
- Booth乘法器测试平台设计与实现
- 极简中国风PPT模板:水墨墨点创意设计
- 掌握openssh-5.9:远程Linux控制的核心工具
- Django 1.8.4:2015年最新版本的特性解析
- C# WinFrom图片放大镜控件的实现及使用方法
- 易语言模块V1.4:追梦_论坛官方增强版
- Yelp评论情绪分析方法与实践
- 年终工作总结水墨中国风PPT模板精粹
- 深入探讨雷达声呐信号处理与最优阵列技术
- JQuery实现多种网页特效指南
- C#实现扑克牌类及其洗牌功能的封装与调用
- Win7系统摄像头显示补丁快速指南
- jQuery+Bootstrap分页插件的四种创意效果展示
- 掌握karma-babel-preprocessor:实现ES6即时编译
