Apache Flink流处理框架详解
"Flink介绍PPT - 快速学习Flink,了解最新批流处理框架"
Apache Flink是一个开源的流处理框架,以其低延迟、高吞吐量和状态管理能力而闻名。该项目由Apache软件基金会开发,自2016年3月发布1.0.0版本以来,已经在生产环境中广泛应用。Flink的设计目标是处理实时数据流,这与Hadoop引领的数据基础设施变革相呼应,标志着数据处理领域从批量处理向流处理的转变。
流处理是自Hadoop以来数据基础设施发生的最大变化,它带来了三个主要优势:
1. 极简化的基础设施:流处理系统简化了数据处理的复杂性,使数据处理更加高效。
2. 数据处理速度更快:实时响应数据流,能够快速分析和行动。
3. 完全包容批量处理:流处理框架可以同时处理批处理任务,提供统一的编程模型。
在实际数据环境中,数据通常是连续产生的。新系统如Flink和Kafka顺应了数据的流式特性。Flink的架构包括DataStream API(支持Java和Scala),用于处理无界和有界数据流,以及Dataset API,用于批处理。Flink可以在YARN或独立集群上运行,同时也支持本地执行模式。
Flink的核心特点使其“flink”:
1. 低延迟:Flink设计了高效的事件时间处理机制,确保了对实时数据的快速响应。
2. 高吞吐量:通过优化的数据传输和并行处理,Flink能够在大规模数据流中保持高吞吐。
3. 状态管理:Flink支持状态ful的计算,这意味着它可以记住处理过程中的中间结果,对于处理窗口或者复杂事件处理至关重要。
4. 一致性保障:Flink提供了一致性的检查点机制,确保在故障发生时能够恢复到一致的状态。
5. 自动容错:通过分布式快照和故障恢复机制,Flink可以自动从失败中恢复,保证了系统的高可用性。
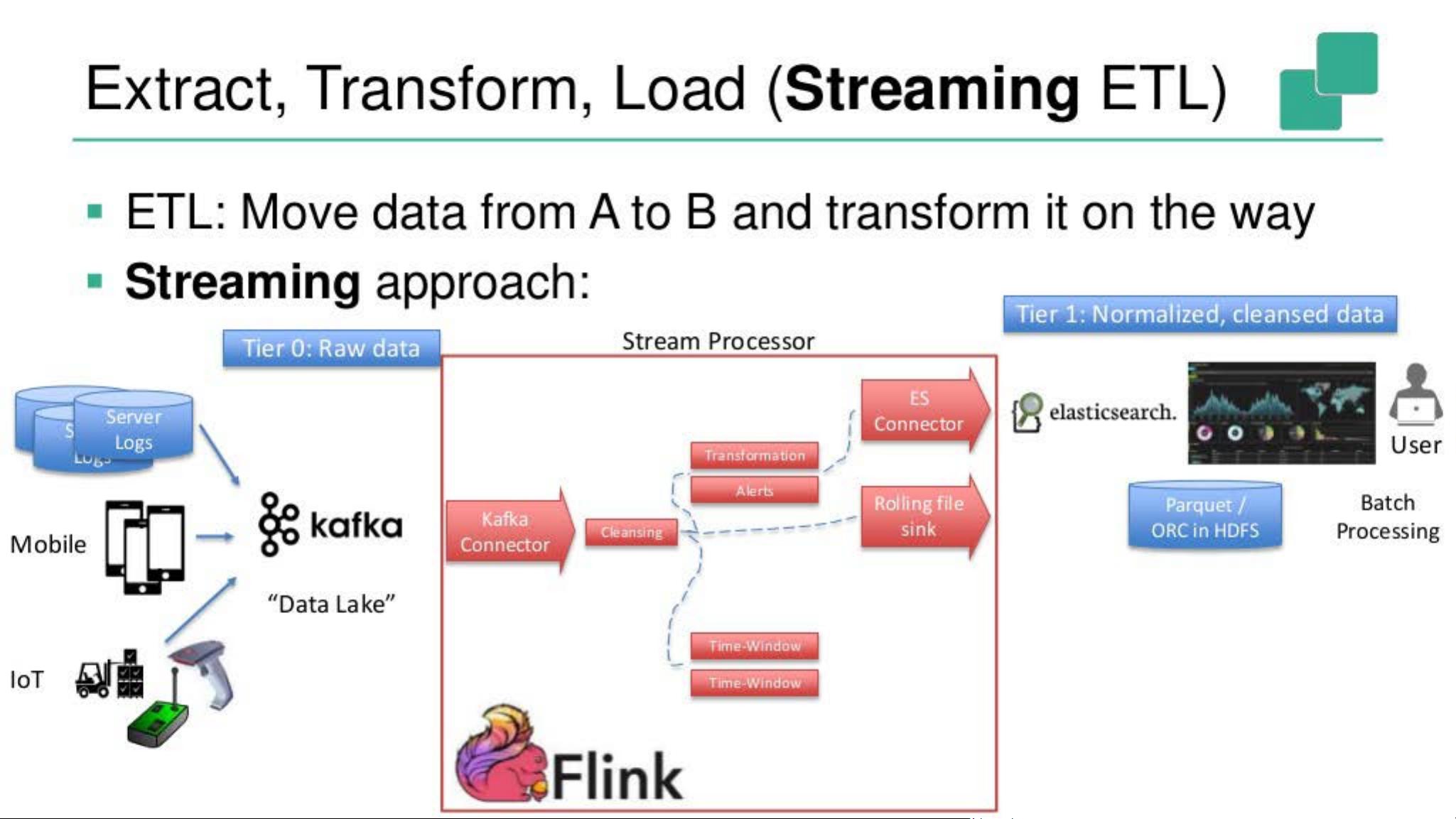
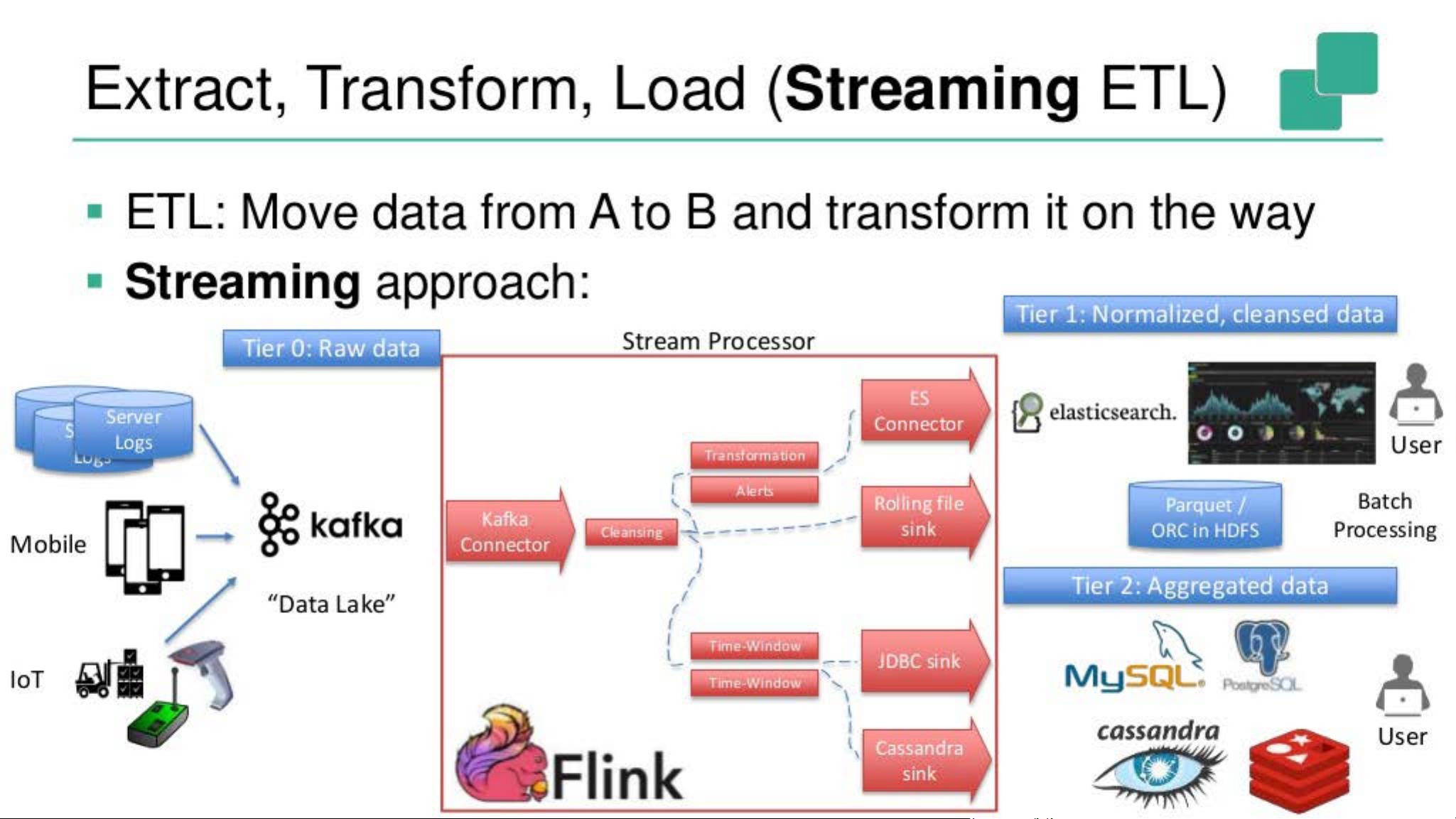
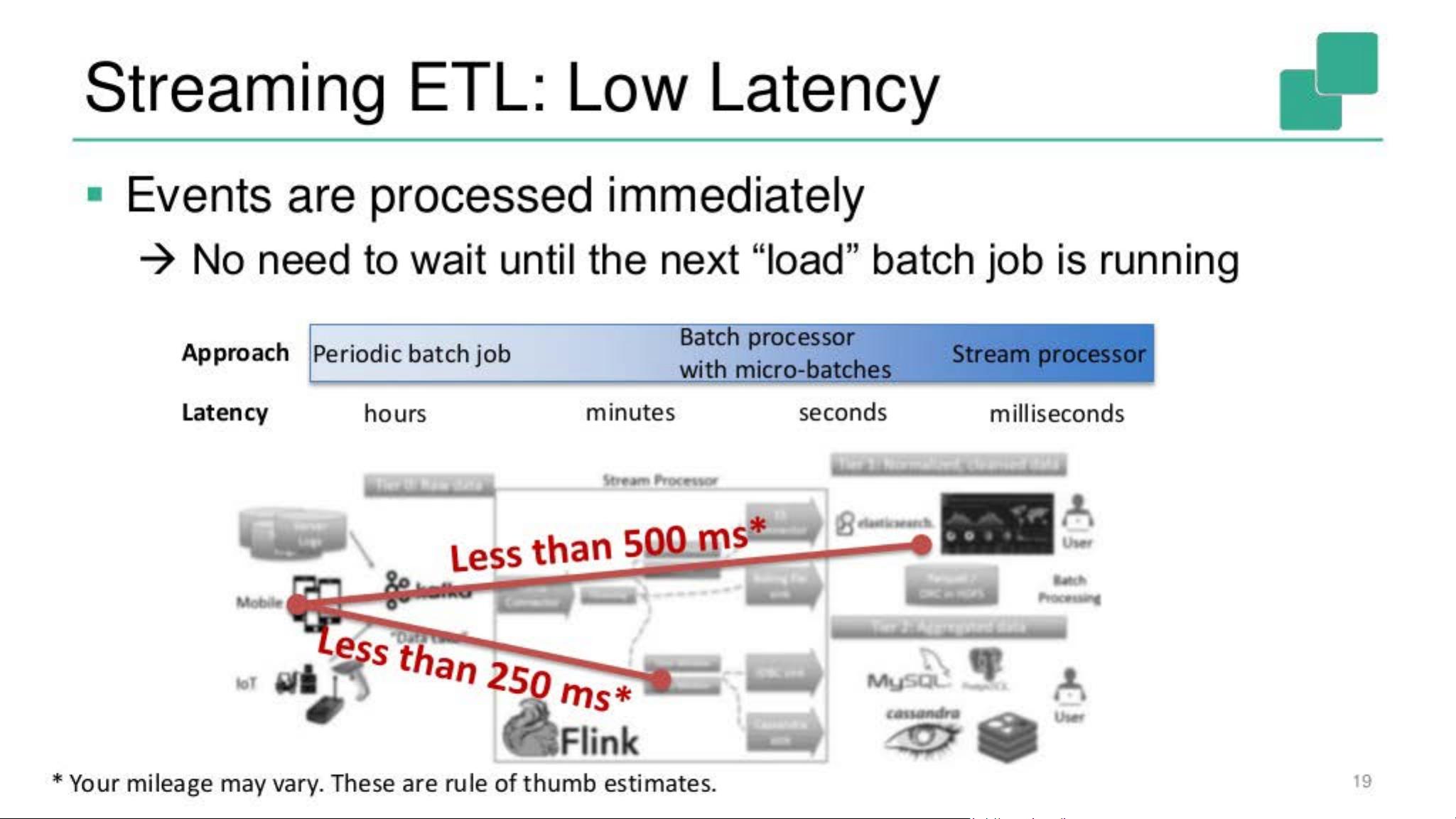
演示部分通常会展示如何将传统的数据分析模式转化为流处理模式,即“Streaming ETL”(流处理提取、转换和加载)。通过这种方式,用户可以实时地清洗、转换和加载数据,而不是等待批处理完成。
Apache Flink是应对现代大数据实时需求的重要工具,它提供了一个强大的平台,用于构建实时数据应用,帮助企业和组织实时洞察业务并作出快速决策。通过深入理解Flink的核心概念和功能,开发者可以有效地利用其能力来优化数据处理流程。
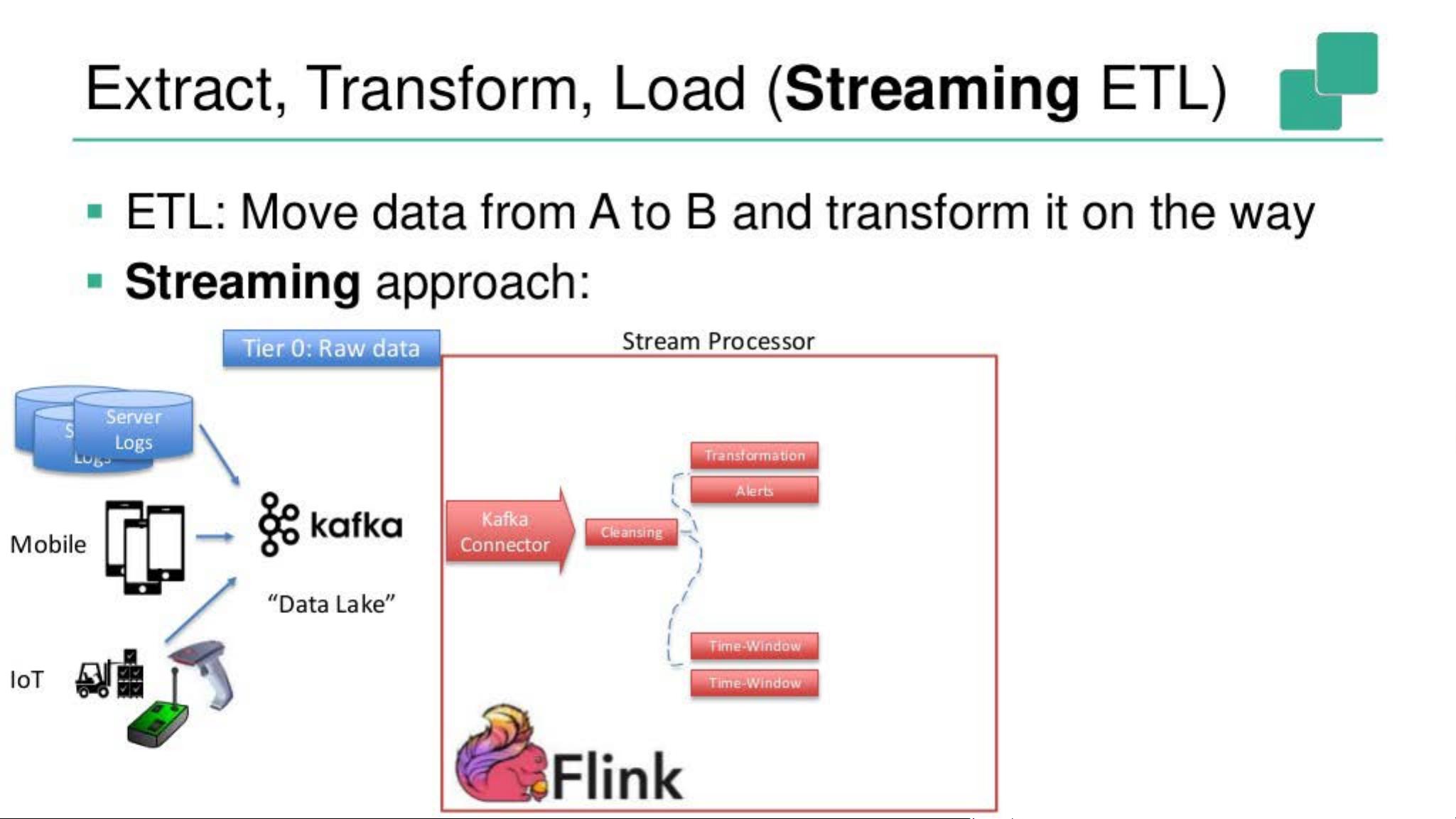
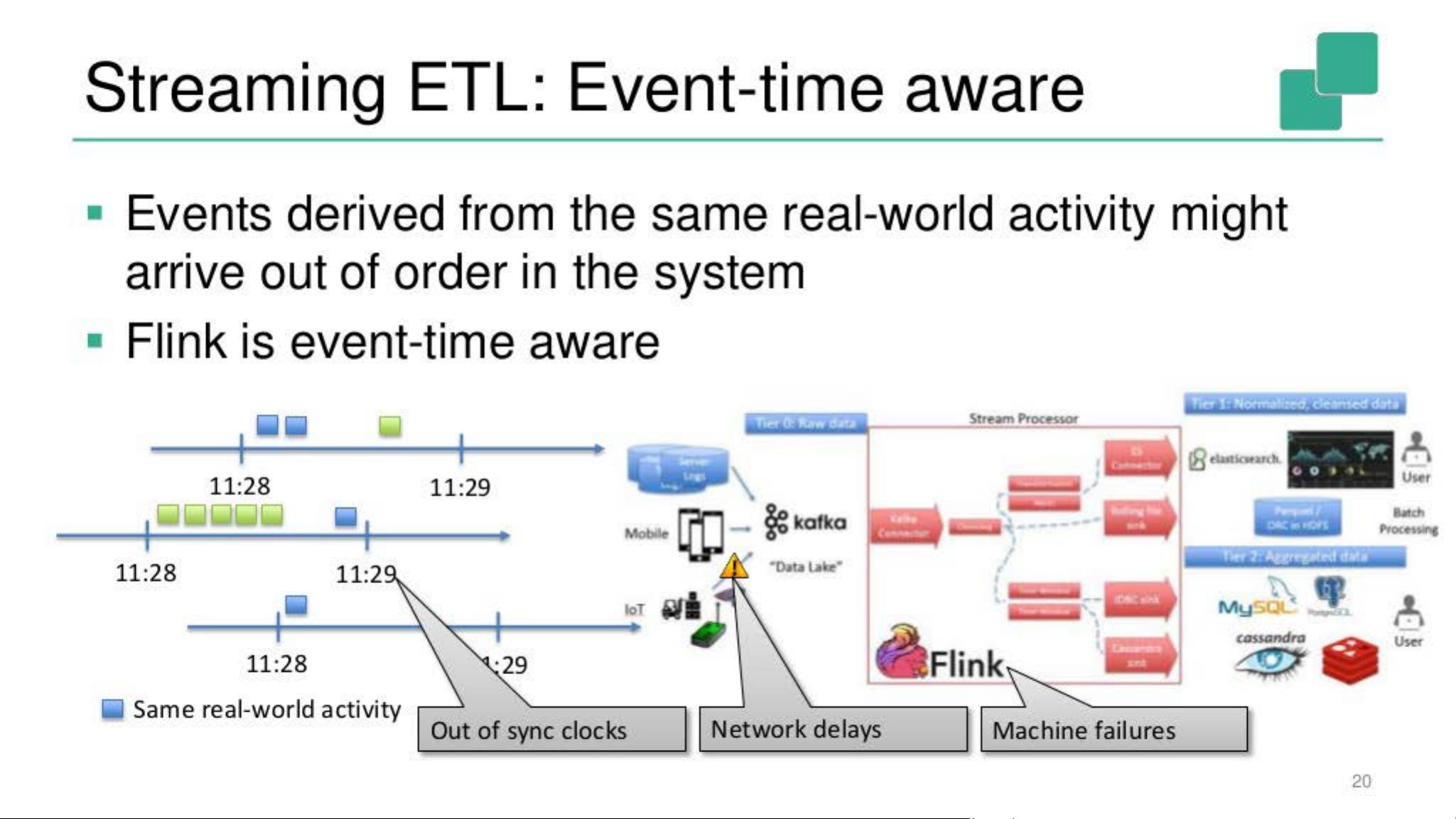
Extract, Transform, Load (Streaming ETL)
• ETL: Move data from A to B and transform it on the way
• Streaming approach:
\
Mo
bile
_
~
kafka
~
"Data
La
ke"
loT
.o
,
Stream Processor
Cl
em
1
'
_ \
'
I
I
I
I
I
'
I
l
-
Flink
剩余2370页未读,继续阅读
2021-03-15 上传
2018-10-03 上传
点击了解资源详情
2019-12-03 上传


milesandnick
- 粉丝: 6
- 资源: 24
 我的内容管理
展开
我的内容管理
展开







最新资源
- 单电源运放图集.pdf
- Wrox.Beginning.Algorithms.Nov.2005.eBook-LinG.pdf
- OpenCV设置方法
- PCI Local Bus Specification V3.pdf
- pecoff_v81_chs.pdf
- UNIX发展史 原创:孟晓亮
- JavaScript类库大全
- PXA255设计文档_原理图_布局图
- Protel DXP 常用元件
- 基于DSP的最小图像采集处理系统设计
- 《悟透JavaScript》初版.pdf
- keil C51入门必修课.PDF
- DSP dsp DSP (PDF)
- Excel基本操作技巧荟萃
- DSP入门教程(PDF)
- quickstart apache axis2
