决策树学习详解:构建与特征选择
需积分: 27 161 浏览量
更新于2024-09-12
收藏 260KB PDF 举报
"机器学习03--决策树01"
决策树是一种广泛应用的机器学习算法,它通过构建一种类似流程图的结构来进行分类或回归任务。在这个结构中,长方形节点代表决策(判断)模块,用于根据特定特征进行条件判断;椭圆形节点则代表终端(终止)模块,表示已经得出预测结果并结束流程。这些节点之间由分支(有向边)相连,形成一个从根节点到叶节点的多层次结构。
根节点是决策树的起点,通常代表整个数据集。从根节点出发,根据特征值的不同,数据会沿着不同的分支向下流动,直到到达叶节点,也就是决策结果。每个内部节点对应一个特征,其分支代表了特征的不同取值,而叶节点则对应于最终的分类或回归值。
在构建决策树的过程中,特征选择是关键步骤。这涉及到寻找能够最好地区分数据类别的特征。常见的选择标准是信息增益或信息增益比。信息增益是通过比较数据集在划分前后的熵变化来度量特征的重要性。熵,源自信息论,是衡量数据不确定性的指标,其计算基于各个类别出现的概率。特征的选择旨在最大化信息增益,从而找出最具区分力的特征。
例如,在贷款申请的场景中,决策树可能会根据申请人的年龄、工作等特征来决定是否批准贷款。选择年龄或工作的哪个特征作为根节点,取决于它们在划分数据时导致的信息增益大小。一旦选定特征,数据将被分割成子集,然后在子集上重复这一过程,直至达到预设的停止条件,如树的深度、节点的纯度等。
决策树构建完成后,为了防止过拟合,通常会进行修剪操作。修剪可能涉及删除一些分支,尤其是那些仅包含少数样本的叶节点,以简化模型并提高泛化能力。修剪策略包括预剪枝和后剪枝,前者在构建过程中设定提前停止条件,后者则是在树构建完毕后回溯并去除冗余部分。
决策树以其直观易懂的结构和相对简单的实现,成为了机器学习领域中的重要工具,广泛应用于各种预测问题。然而,需要注意的是,决策树容易受到数据噪声和不平衡的影响,因此在实际应用中,往往需要结合其他方法,如集成学习(如随机森林),以提高模型的稳定性和准确性。
数据科学 8 机学习: 决策树
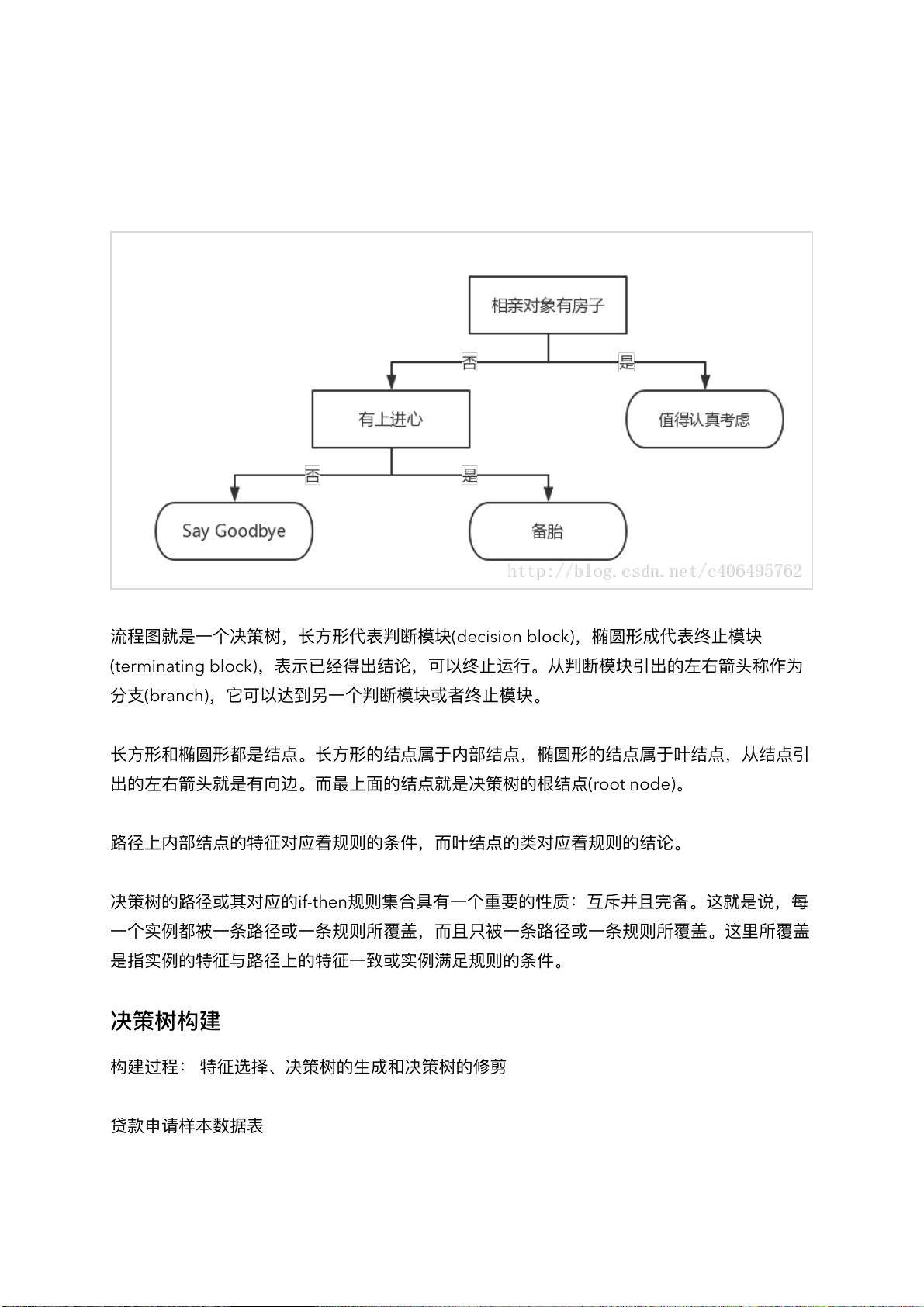
决策树(decision tree)是种基本的分类与回归法。
流程图就是个决策树,形代表判断模块(decision block),椭圆形成代表终模块
(terminating block),表示已经得出结论,可以终运。从判断模块引出的左右箭头称作为
分(branch),它可以达到另个判断模块或者终模块。
形和椭圆形都是结点。形的结点属于内部结点,椭圆形的结点属于叶结点,从结点引
出的左右箭头就是有向边。最上的结点就是决策树的根结点(root node)。
径上内部结点的特征对应着规则的条件,叶结点的类对应着规则的结论。
决策树的径或其对应的if-then规则集合具有个重要的性质:互斥并且完备。这就是说,每
个实都被条径或条规则所覆盖,且只被条径或条规则所覆盖。这所覆盖
是指实的特征与径上的特征致或实满规则的条件。
决策树构建
构建过程: 特征选择、决策树的成和决策树的修剪
贷款申请样本数据表
下载后可阅读完整内容,剩余7页未读,立即下载
2023-10-11 上传
2024-05-27 上传
2024-08-30 上传
2024-08-24 上传
2024-04-25 上传
2022-07-09 上传
2024-08-30 上传

清平乐的技术博客
- 粉丝: 1428
- 资源: 43
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
