Kettle数据处理全攻略:转换、步骤详解
需积分: 10 200 浏览量
更新于2024-07-22
收藏 4.56MB DOCX 举报
"kettle 详细使用手册"
Kettle,也称为 Pentaho Data Integration (PDI),是一款强大的ETL(Extract, Transform, Load)工具,主要用于数据的抽取、转换和加载,以支持数据仓库和大数据处理项目。它提供了丰富的数据处理组件,包括Job和转换,用于实现数据的采集、转换、导入、导出等多种功能。
1. **变量**:在Kettle中,变量是全局性的,可以在整个工作流或转换中使用,用于存储和传递数据。它们可以被不同步骤共享,增加了灵活性和可复用性。
2. **Job和转换**:Job是Kettle中的高级流程,由一系列相互关联的转换和控制结构组成,如条件分支、循环等。转换则专注于单一的数据处理任务,由多个步骤(Steps)按照特定顺序执行。Job可以调用转换,而转换也可以嵌套在Job中,形成复杂的工作流程。
3. **转换**:转换中的每个步骤都有特定的功能,例如数据读取、清洗、转换、写入等。步骤之间通过连线表示数据流的方向。连线的颜色代表不同的数据流动状态,例如错误、正常等。
4. **步骤类型**:Kettle支持多种数据输入和输出步骤,例如:
- 文本文件输入和输出:处理文本文件数据。
- 表输入和输出:从关系型数据库中读取或写入数据。
- 获取系统信息:获取运行环境的信息。
- 生成记录:用于创建指定数量的空白记录。
- Cube输入:处理多维数据。
- Excel输入和输出:处理Excel文件。
- XML输入和输出:处理XML文件。
- 获取文件名和行数:获取文件相关信息。
- 数据库查询和存储过程调用:执行SQL语句或数据库操作。
- 字段选择、过滤、排序:数据预处理操作。
- 序列化、去重、分组统计:数据管理操作。
- JavaScript值、执行SQL语句:允许自定义脚本和数据库操作。
- 映射(子转换):将一个转换嵌入另一个转换中,用于复用和模块化。
5. **控制流和数据流**:Kettle中的Job和转换不仅处理数据,还包含控制流元素,如决策、循环、跳过等,可以根据业务规则控制数据处理流程。
6. **数据库连接**:Kettle支持多种数据库,可以配置并保存数据库连接信息,方便在不同步骤中使用。
7. **数据处理组件**:从简单的数据过滤到复杂的字段计算,Kettle提供了大量的内置组件来满足各种数据处理需求。例如,字段选择用于选择或排除字段,计算器可以进行字段计算,行转列和列转行用于数据结构的转换,值映射用于字段值的替换,等等。
8. **性能优化**:Kettle还提供了如合并记录、排序合并、聚合记录等功能,用于优化数据处理效率,尤其是在处理大量数据时。
9. **与其他系统的集成**:Kettle可以通过HTTP客户端、Web服务器查询等方式与其他系统交互,支持实时数据处理和集成。
10. **异常处理**:例如Abort步骤用于在遇到特定条件时中断流程,而被冻结的步骤(BlockingStep)和记录关联(Cartesian Output)则用于处理特定的数据流控制和关联问题。
Kettle是一个功能全面且强大的ETL工具,其丰富的组件和灵活的工作流程设计使得数据处理变得简单易行,无论是在小型项目还是大型企业级应用中都能发挥重要作用。
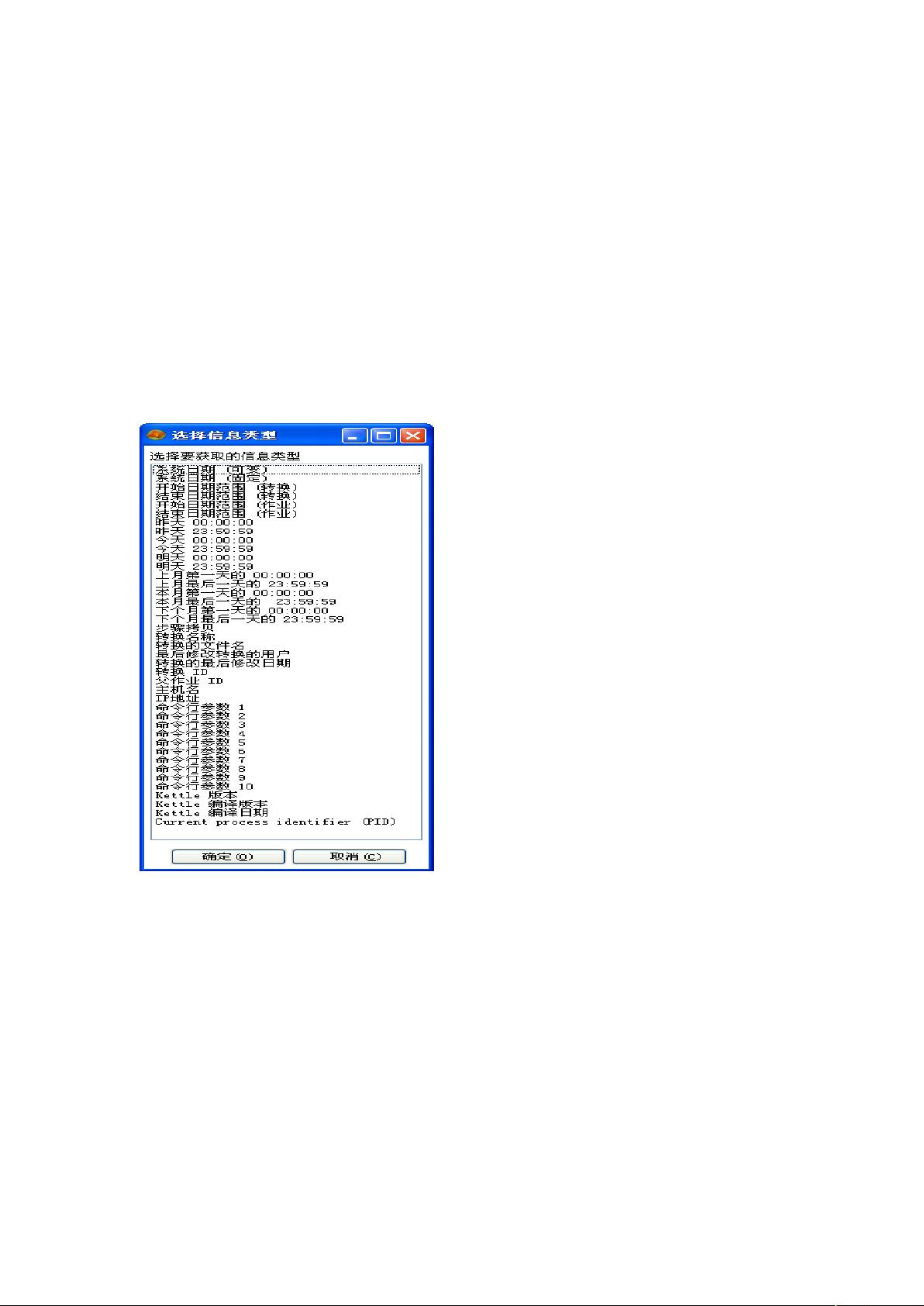
表输入
、 从步骤插入数据:指定我们期待读取数据的步骤名称,这些信息能被插入到 "# 语句。
例如:"#:#$%&'&((
()的数据来自其他步骤
获取系统信息
、系统日期*可变+:系统时间,每次访问
都在改变。
、系统日期*固定+:系统时间,有转换开
始来决定。即转换开始时间
、开始日期范围*转换+:根据 # 日志表的
信息,确定日期范围的开始。
、结束日期范围*转换+:根据 # 日志表的
信息,确定日期范围的结束。
、开始日期范围*作业+:根据 # 日志表的
信息,确定日期范围的开始
、结束日期范围*作业+:根据 # 日志表的
信息,确定日期范围的结束。
、昨天 !!)!!)!!:昨天的开始
、昨天 ) ) :昨天的结束
、今天 !!)!!)!!:今天的开始
!、今天 ) ) :今天的结束
、上个月第一天的 !!)!!)!!:上个月的
开始
、上个月最后一天的 ) ) :上个月
结束
、本月的第一天 !!)!!)!!:这个月的开始
、本月的最后一天 ) ) :这个月的结束
、步骤拷贝:复制步骤
、转换名称:转换的名称
、转换的文件名:转换的文件名*仅针对 ,-.+
、最后修改转换的用户
、转换的最后修改日期
!、转换 /:日志表中的批处理 / 值
、主机名:返回服务器的主机名
、0 地址:返回服务器的 0 地址
、命令行参数 :命令行的第一个参数。

剩余63页未读,继续阅读
1548 浏览量
1967 浏览量
2621 浏览量
254 浏览量
106 浏览量
107 浏览量
2024-10-18 上传
364 浏览量
104 浏览量

qq_25322853
- 粉丝: 0
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- Oracle10g系统表视图(高清晰版大图)
- JFFS2文件系统 PDF
- 09年嵌入式系统设计师考试大纲
- 电子书:电子DIY过程详解
- axure rp 原型设计软件教程
- jsp自动设置的若干问题
- 新型高性能开关电源电压型PWM比较器
- UML for Java Programmers中文版
- mpeg4--标准白皮书
- 单相并联型无源_有源混合滤波器的仿真研究
- Spring 开发指南
- 高质量C++编程指南
- Weblogic 8.1中配置JDBC
- 软考信息系统管理工程师考试大纲
- 在 Weblogic 8.1上配置 Hibernate 3.0
- Developing with Google App Engine
