"hadoop完全分布式安装指南:Linux环境搭建、软件部署详解"
需积分: 3 39 浏览量
更新于2024-04-02
收藏 566KB DOCX 举报
Apache Hadoop 是一个开源的分布式计算平台,用于处理大规模数据。要在完全分布式模式下安装 Hadoop,首先需要在 Linux 环境下搭建并配置好必备软件环境。本文将介绍如何在 CentOS 7 64 位系统上安装 Hadoop 2.6.4 和 jdk-7u79,以及使用 VMware Workstation Pro 12 创建并克隆虚拟机的操作步骤。
首先,在 Windows 系统上安装 VMware Workstation Pro,并在其上创建虚拟机并安装 CentOS 操作系统。安装完成后,需确保开启 ssh 和 ftp 服务。为了搭建完全分布式的 Hadoop 环境,需要准备三台虚拟机,可以通过克隆已创建的虚拟机来快速建立新的虚拟机。克隆操作可以在前期安装配置完成后进行,以免后续需要重复配置。
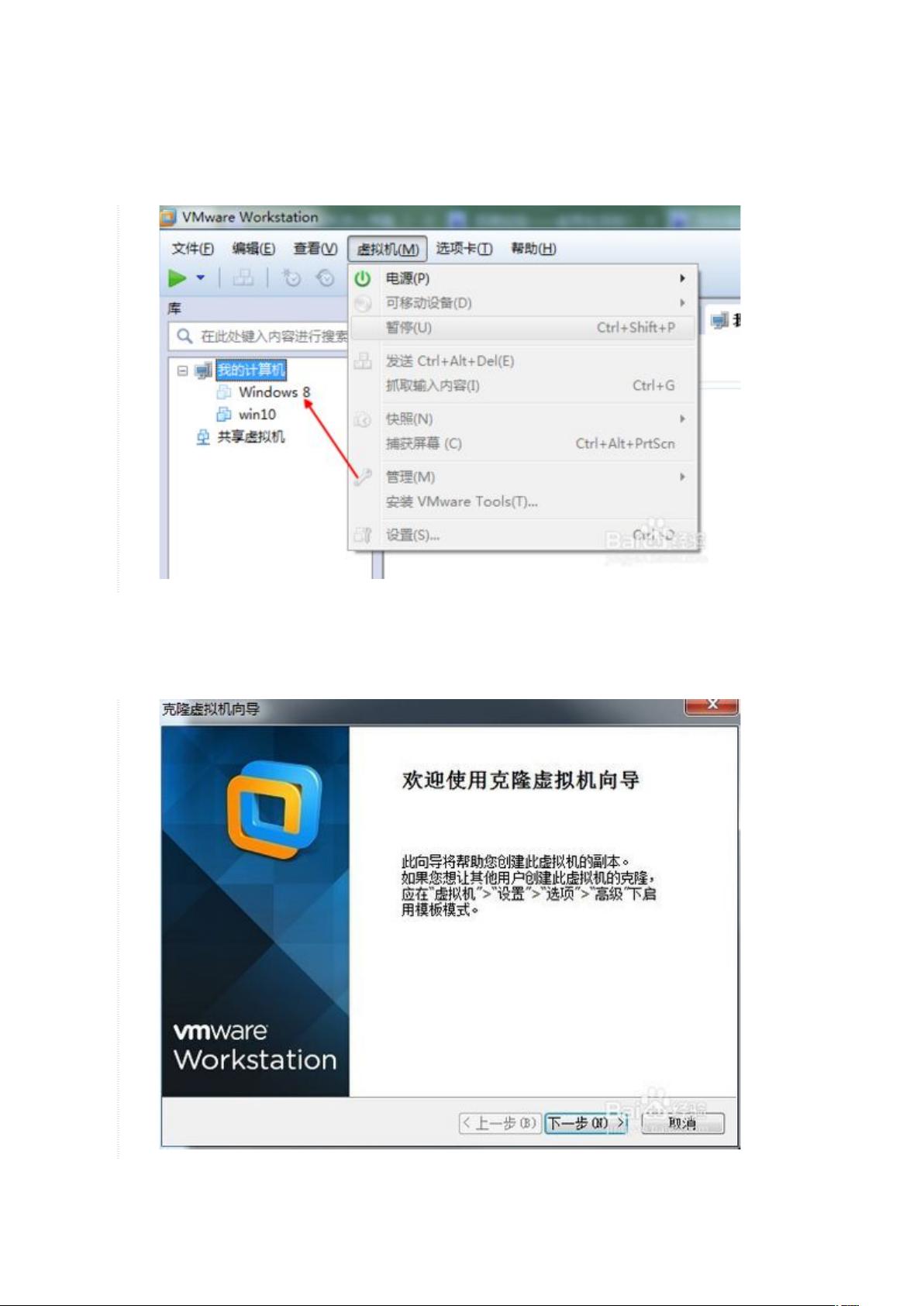
在 VMware 界面中,通过导航栏找到“虚拟机”并进入“管理”中的“克隆”选项。在克隆操作中,关闭要克隆的虚拟机系统,选中被克隆系统,并选择完整克隆或 q 链接克隆。等待克隆完成后,可以开始配置 Hadoop 完全分布式环境。
接下来,需要下载并安装 Hadoop 2.6.4 和 jdk-7u79,并进行必要的配置。在每台虚拟机上都需要设置环境变量和修改配置文件,包括 Hadoop 环境变量、hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml 和 yarn-site.xml。配置时需要确保每台虚拟机的配置一致,以确保 Hadoop 正常运行。
在配置完成后,启动 Hadoop 的各个组件,包括 NameNode、DataNode、ResourceManager、NodeManager 和 JobHistoryServer。通过 Web 界面或命令行工具,可以监控和管理 Hadoop 集群的运行状态。为了测试 Hadoop 的功能和性能,可以加载和处理一些测试数据,并执行 MapReduce 任务。
在安装和配置完全分布式 Hadoop 环境后,需要进行集群的优化和监控,以确保集群的稳定和高效运行。通过调整配置参数、监控资源利用情况和处理故障,可以提高 Hadoop 集群的性能和可靠性。
综上所述,搭建和配置完全分布式的 Hadoop 环境需要在 Linux 系统上安装必备软件环境,并使用虚拟机来创建和克隆多台虚拟机。通过正确的配置和管理,可以实现高效、可靠的大数据处理和分析。希望本文提供的安装文档和操作步骤能帮助您顺利搭建和运行 Hadoop 集群。
剩余19页未读,继续阅读
2023-12-20 上传
2015-08-24 上传
123 浏览量
178 浏览量
104 浏览量
114 浏览量
122 浏览量
113 浏览量

lsliliang
- 粉丝: 3
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- star NX-650 打印机说明书
- Simulink在直接扩频通信系统中的应用
- DIV+CSS布局大全
- 考研英语核心词汇.pdf
- 《eclipse基础教程中文版》
- Fundamentals of Digital Television Transmission
- Java+Servlet+API说明文档
- 网上书店需求分析书(很正规的一个模板啊)
- Linux Unicode Programming-CH
- 清华大学2005年第23届挑战杯精品集
- ATM Signalling PROTOCOLS AND PRACTICE
- 高质量C++编程指南
- essential c++英文版
- SQL Sever 2005专业教程(英文版)
- CHS]跟我一起写_Makefile
- Computer Arithmetic
