Apache Flink与Iceberg集成:应对Hive挑战与最佳实践
版权申诉
7 浏览量
更新于2024-07-04
收藏 11.7MB PDF 举报
Apache Flink集成Apache Iceberg的最佳实践是在2021年的Flink Forward Asia会议上探讨的一个关键主题,针对大数据处理场景中Hive表格式所面临的挑战提出了创新的解决方案。Flink和Iceberg的结合旨在优化大数据处理流程,特别是对于云计算环境下的挑战和对实时性要求较高的近实时数仓场景。
首先,Hive表格式在上云过程中遇到的主要问题包括:
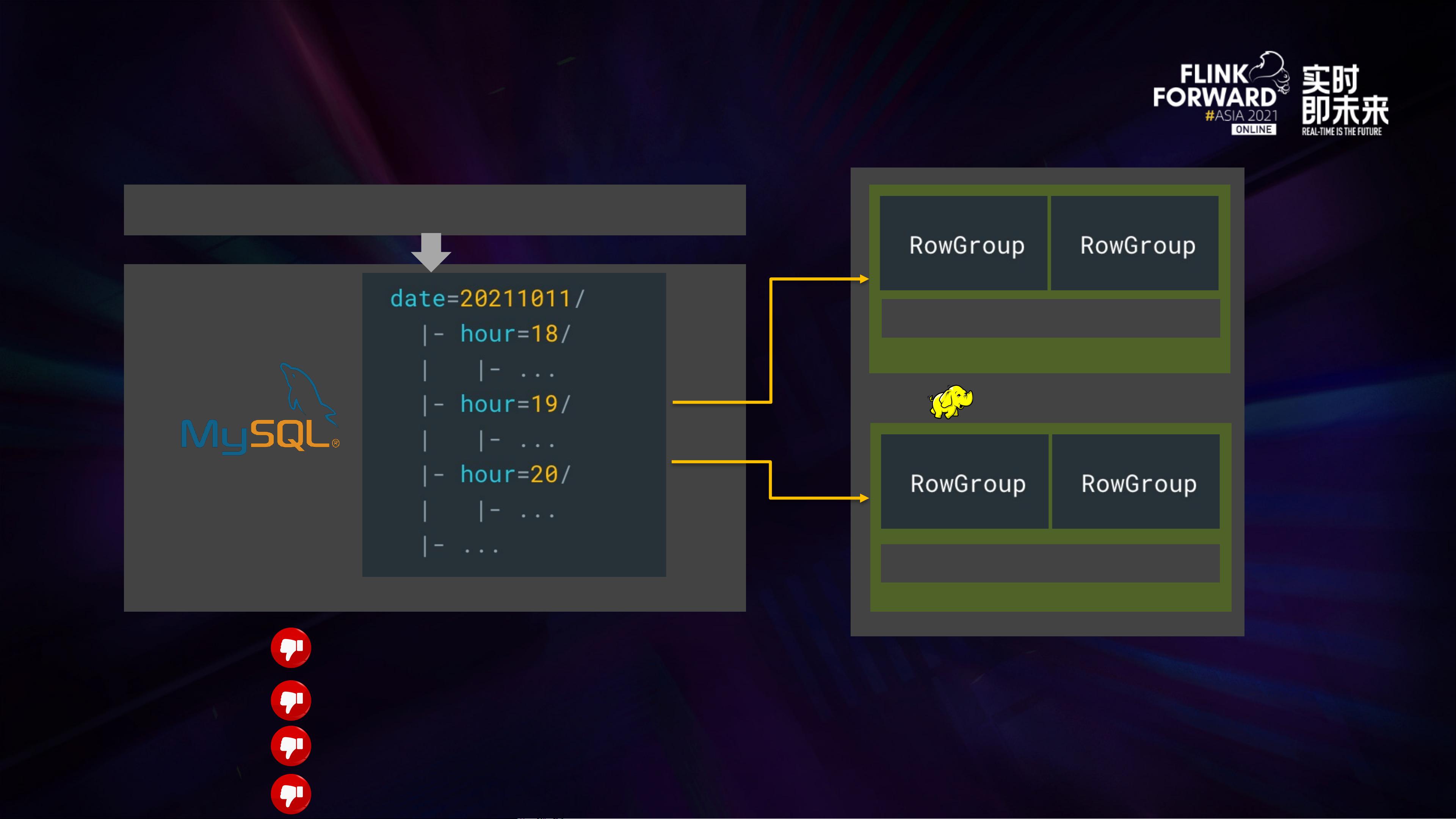
1. **存储与扩展性** - Hive Metastore作为中心化的元数据存储,随着数据量的增长和云厂商的多样化需求,其扩展性不足且依赖于Hadoop HDFS,导致成本高、缺乏弹性。此外,Hive的表级统计信息更新不及时,且文件级统计信息缺失,这在查询性能上造成瓶颈。
2. **兼容性和统一性** - Hive对多种对象存储的支持有限,比如阿里云OSS、Amazon S3和Google GCS,且存在文件格式的差异化细节,这使得数据管理和处理变得复杂。用户需要一个统一的Table语义,具有高抽象度和ACID特性,同时支持多种计算引擎如Hive、Spark、Flink和Presto的互操作。
3. **实时性要求** - 近实时数仓是业务的关键需求,Hive Table和Generic Table在入仓、查询和出仓过程中都有局限性。例如,Hive Metastore扩展性不足以满足分钟级的分区操作,查询时元数据索引效率低下,且缺乏增量数据查询功能。
Apache Iceberg作为一项新兴的列式数据存储格式,针对上述挑战提供了以下解决方案:
1. **去中心化元数据** - Iceberg的去中心化设计允许将元数据分布在多个节点上,解决了Hive Metastore扩展性的问题,同时减少对单一存储中心的依赖,使得数据存储更加灵活和低成本。
2. **统一的Table语义** - Iceberg提供了一个统一的表模型,支持多种文件格式,如Parquet、Avro和ORC,从而简化了数据处理流程,提高开发者的生产力。
3. **计算引擎集成** - Iceberg的设计使得它能够与Flink等现代计算引擎无缝集成,提供一致的接口和性能,满足近实时数据处理的需求。
4. **增强实时性能** - Iceberg通过优化写入路径(WritePath)和读取路径(ReadPath),提高了数据写入和查询的效率,特别是在处理大量小文件和频繁的更新操作时。
5. **弹性存储支持** - Iceberg天生支持多种对象存储,可以轻松地扩展到云环境,解决了Hadoop HDFS的成本和扩展性问题。
总结来说,Apache Flink与Apache Iceberg的集成实践是大数据处理领域的一个重要进步,通过解决Hive的局限性,提供了更高效、可扩展和实时的数据处理能力,为企业在云环境下构建实时数仓提供了强大工具。未来,随着技术的发展,这种集成模式有望进一步优化,推动大数据处理的演进。
挑战#2: 近实时数仓
Hive Table Generic Table
小时级时效性体验
分钟时级时效性体验
剩余38页未读,继续阅读
137 浏览量
119 浏览量
132 浏览量
170 浏览量
2022-04-29 上传
2022-04-29 上传
2022-04-29 上传

图灵智库
- 粉丝: 48
- 资源: 7018
 我的内容管理
展开
我的内容管理
展开







最新资源
- star NX-650 打印机说明书
- Simulink在直接扩频通信系统中的应用
- DIV+CSS布局大全
- 考研英语核心词汇.pdf
- 《eclipse基础教程中文版》
- Fundamentals of Digital Television Transmission
- Java+Servlet+API说明文档
- 网上书店需求分析书(很正规的一个模板啊)
- Linux Unicode Programming-CH
- 清华大学2005年第23届挑战杯精品集
- ATM Signalling PROTOCOLS AND PRACTICE
- 高质量C++编程指南
- essential c++英文版
- SQL Sever 2005专业教程(英文版)
- CHS]跟我一起写_Makefile
- Computer Arithmetic
