ID3与C4.5策略实现决策树分类算法
"西电数据挖掘课程的上机作业,主要任务是实现基于决策树的分类算法,可以选择ID3或C4.5策略。提供的数据集包含五个属性:年龄、收入、是否为学生、信用评级和是否购买电脑,用于构建分类决策树。"
决策树是一种常用的数据挖掘和机器学习算法,它通过一系列规则来做出预测,这些规则以树状结构呈现,便于理解和解释。ID3算法是最早提出的一种基于信息熵的信息增益方法,而C4.5则是ID3的改进版本,处理了ID3的一些局限性,如处理连续属性和防止过拟合。
1. ID3算法的核心思想:
- **信息熵**:衡量数据集纯度的指标,纯度越高,熵越低。对于二分类问题,完全同质的数据集熵为0,完全异质的熵为1。
- **信息增益**:选择分裂属性时,计算当前数据集的熵与以每个属性为分裂条件后子集的加权平均熵之差,这个差值即为信息增益。
- **选择最佳属性**:在所有属性中,选取信息增益最大的属性作为分裂属性,不断进行分裂,直到所有实例属于同一类别或者没有可分裂属性为止。
2. C4.5算法改进:
- **信息增益比**:为了解决ID3对连续属性和离散属性处理不平等的问题,C4.5引入了信息增益比,它是信息增益与属性值的熵的比值,减少了对多值属性的偏好。
- **处理连续属性**:C4.5可以将连续属性离散化,通过设定阈值或使用分箱技术。
- **剪枝策略**:为了防止过拟合,C4.5引入了预剪枝和后剪枝策略,当树的复杂度超过一定阈值或训练集上的误差率低于一定阈值时,停止分裂并回溯。
3. 给定的编程实现:
- 源代码中定义了一个`Data`结构体,包含了示例数据的五个属性:年龄、收入、学生状态、信用评级和购买电脑的标签。
- `calculate`函数可能用于计算熵或信息增益等数学操作。
- `origin_entropy`函数可能是用于计算数据集的原始熵,这在ID3或C4.5算法的初始阶段是必要的。
- 编程实现需要完成计算熵、信息增益、选择最佳属性、构建决策树以及可能的剪枝步骤。
在实际应用中,决策树算法广泛应用于各种领域,如市场分析、信用评估、医疗诊断等。通过理解和实现ID3或C4.5算法,可以更好地理解决策树的工作原理,并能处理实际问题。
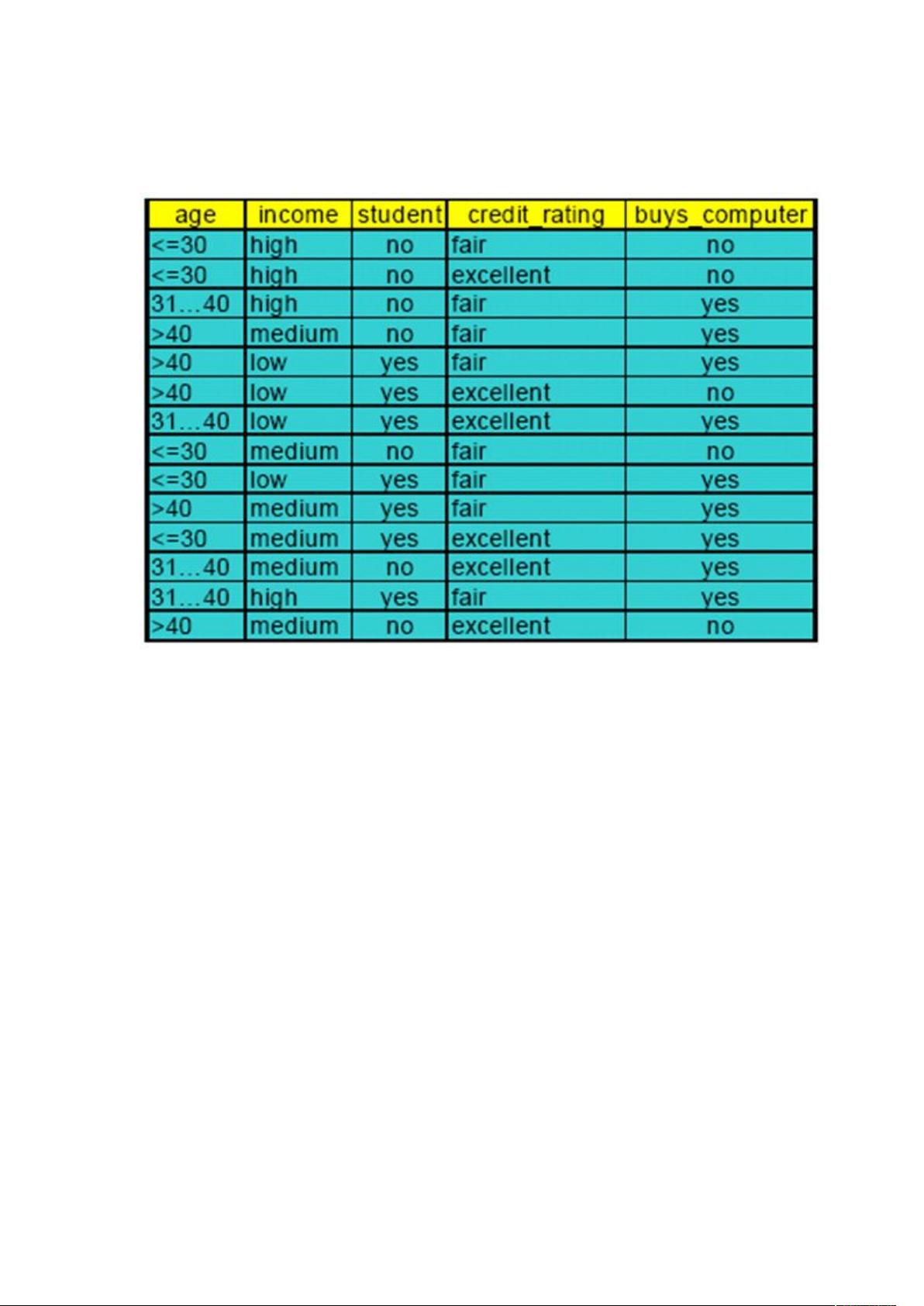
实习题 1 基于决策树的分类算法,属性的选择采用 ID3 或 C4.5 策略,采用如下
的数据建立分类决策树。
一. 算法思想描述:
ID3 选择具有最高信息熵增益的属性作为分裂属性,基于这种原则我们首先可以算出
初始集合的熵,然后分别求出以各个属性为分裂属性时的熵,然后将通过上面得到的
数据算出以各个属性为分裂属性时的信心增益,选择具有最大的信息增益属性作为我
们的分裂属性。
二. 编程实现(源代码)
#include <iostream>
#include <cmath>
#include <string>
using namespace std;
#dene SIZE 14
struct Data
{
string age;
string income;
string student;
string credit_rating;
string buys_computer;
};
Data data [SIZE]={{"<=30","high","no","fair","no"},
{"<=30","high","no","excellent","no"},
下载后可阅读完整内容,剩余7页未读,立即下载
2018-03-13 上传
2023-04-03 上传
2023-04-03 上传
2022-01-03 上传
2018-03-13 上传
2013-01-11 上传

Allenhui89
- 粉丝: 25
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
