百度Paddle学习日志:初识神经网络与数据爬取
164 浏览量
更新于2024-08-28
收藏 550KB PDF 举报
"这篇日志记录了作者使用百度Paddle进行神经网络学习的第一天体验,主要包括检查Paddle库的安装和使用爬虫技术获取丁香网的疫情数据。作者建议遇到问题可参考百度AI Studio平台,并给出了爬虫的基本步骤:发送请求、接收响应、解析数据和保存数据。"
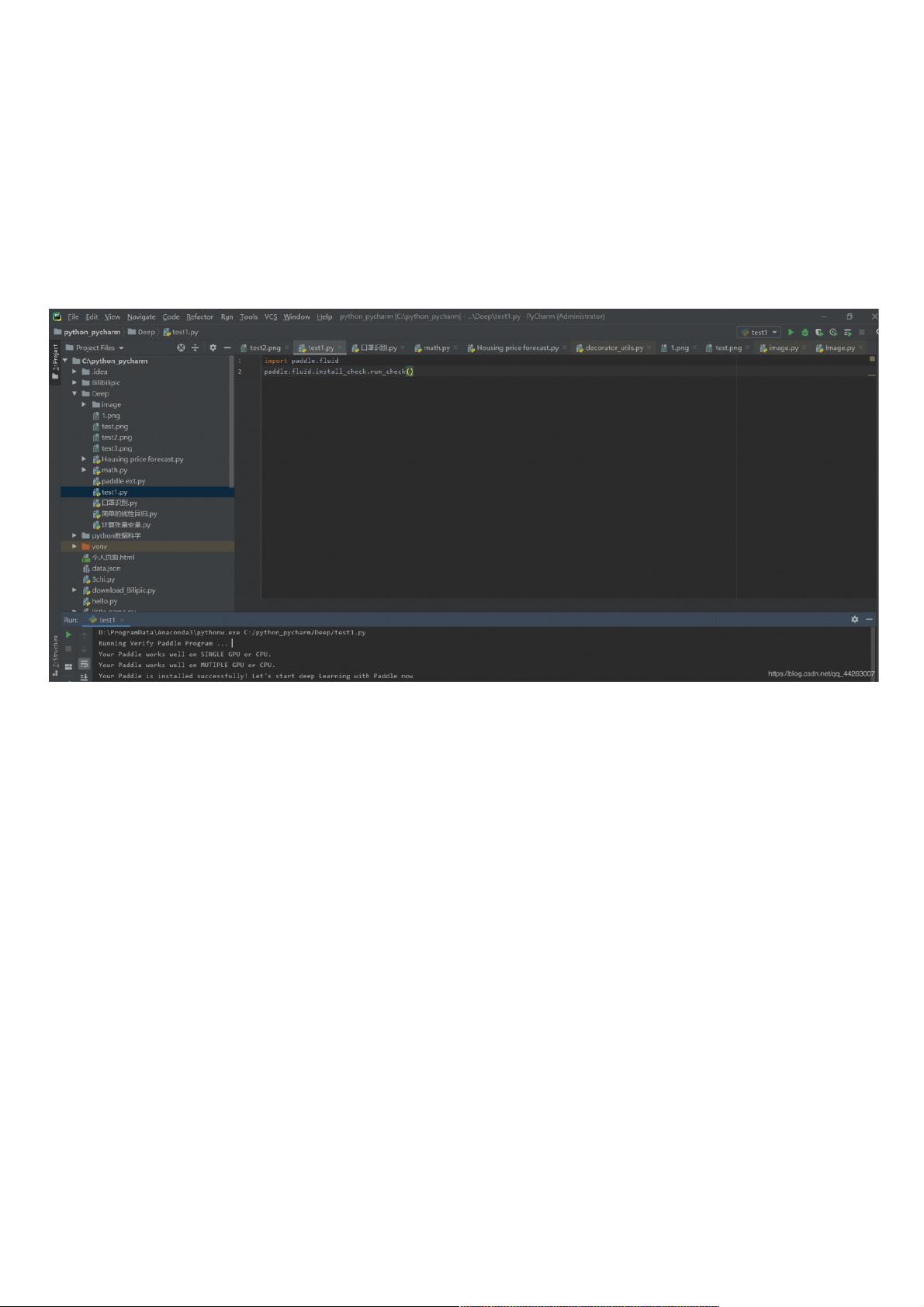
在深度学习领域,框架的选择至关重要,百度的PaddlePaddle(简称Paddle)是一个开源的深度学习平台,旨在提供便捷高效的神经网络训练和应用开发。本文的作者开始了他的Paddle学习之旅,首先验证了Paddle库是否已成功安装。在Python环境中,通过`import paddle.fluid`导入库,并调用`paddle.fluid.install_check.run_check()`来运行检查,确保环境配置无误。
接着,作者提到数据准备是机器学习项目的重要环节。他选择了爬取丁香网的疫情数据作为示例,展示了如何使用Python的`requests`库向网站发送HTTP请求,获取响应数据。`requests.get()`函数用于发起GET请求,获取网页内容。在收到响应后,通过`response.status_code`检查请求的状态码,确保请求成功。为了从HTML文本中提取所需信息,作者利用`re`(正则表达式)模块进行数据解析。正则表达式在处理结构化的文本数据时非常有效,这里使用`re.search()`查找特定模式,提取数据。
值得注意的是,作者还提到了在本地资源有限的情况下,可以使用百度的AI Studio平台进行编程。这是一个云端开发环境,提供了丰富的计算资源和便利的开发工具,对于初学者和大型项目的实施都非常有帮助。
通过这篇日志,读者不仅可以了解PaddlePaddle的基本使用,还能学习到数据爬取的基本流程,这在实际的机器学习项目中是非常实用的技能。在后续的学习日记中,作者可能会展开讨论更多关于PaddlePaddle构建神经网络模型、训练和优化等方面的内容。
百度百度paddle神经网络学习日记(一)神经网络学习日记(一)
百度paddle神经网络学习日记(一)
**
百度百度paddle神经网络学习的第一天神经网络学习的第一天
**
做为笔记来记录学习的七天,今天是第一天!
话不多说,直接进入主题。
**
1.查看是否安装查看是否安装paddle库:库:
任何疑问可以访问:https://aistudio.baidu.com/
自行查阅
import paddle.fluid
paddle.fluid.install_check.run_check()
可见运行成功 ,第一步成功!
第二步:
数据准备 通过爬取丁香网的数据获得疫情等信息
爬虫的过程:
1.发送请求(requests模块)
2.获取响应数据(服务器返回)
3.解析并提取数据(re正则)
4.保存数据
本地电脑受限也推荐使用百度的aistudio进行编程:https://aistudio.baidu.com
import json
import re
import requests
import datetime
today = datetime.date.today().strftime('%Y%m%d') #20200331
def crawl_dxy_data():
"""
爬取丁香园实时统计数据,保存到data目录下,以当前日期作为文件名,存JSON文件
"""
response = requests.get('https://ncov.dxy.cn/ncovh5/view/pneumonia') #request.get()用于请求目标网站
print(response.status_code) # 打印状态码
try:
url_text = response.content.decode() #更推荐使用response.content.deocde()的方式获取响应的html页面
#print(url_text)
url_content = re.search(r'window.getAreaStat = (.*?)}]}catch', #re.search():扫描字符串以查找正则表达式模式产生匹配项的第一个位置 ,然后返回相应的match对象。
url_text, re.S) #在字符串a中,包含换行符,在这种情况下:如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始;
#而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配。
texts = url_content.group() #获取匹配正则表达式的整体结果
content = texts.replace('window.getAreaStat = ', '').replace('}catch', '') #去除多余的字符
json_data = json.loads(content)
with open('data/' + today + '.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
except:
print('' % response.status_code)
def crawl_statistics_data():
"""
获取各个省份历史统计数据,保存到data目录下,存JSON文件
"""
with open('data/'+ today + '.json', 'r', encoding='UTF-8') as file:
下载后可阅读完整内容,剩余3页未读,立即下载
459 浏览量
312 浏览量
2895 浏览量
111 浏览量
824 浏览量
235 浏览量
1990 浏览量
202 浏览量
118 浏览量

weixin_38726255
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- AMeDAS降水量3D图演示:1小时数据分析
- React应用开发与部署指南:项目结构和脚本使用
- IIS虚拟服务器:网站搭建的利器
- 户户通机顶盒解锁及定位擦除工具使用指南
- Foobar2000:支持SACD播放的iOS文件拖拽式播放器
- Windows平台下的OpenBLAS库发布:X86与X64版本
- 经营怪物工厂挑战:打造最强恶魔之王游戏体验
- Eclipse SVN插件SVN-1.6.13安装配置教程
- TMS CETools 1.6.0.0 for PocketPC的发布与特性
- 批量导线数据简易处理与课程设计应用
- Excel VBA 2003程序员必备参考与源代码解析
- CMC5401开发资料压缩包下载
- FileZilla 3.5.3 FTP客户端安装文件解压缩指南
- 打造基础JavaScript项目框架教程
- DELPHI实现PBOC2.0核心算法工具包发布
- Java环境配置与演示程序部署流程指南
