"PolarDB-X:实现单机平滑演进分布式的三级数据分布与业务耦合内聚"
需积分: 0 199 浏览量
更新于2024-02-02
收藏 5.43MB PDF 举报
PolarDB-X 是一个云原生的分布式数据库,它具有极致的弹性和高可用性,能够处理金融级别的大规模数据,并具备千万级的吞吐能力。PolarDB-X 支持MySQL生态的语法和工具,同时还具备可复用的运维经验。
PolarDB-X 采用了三级数据分布的架构,包括数据节点(DN)、Table Group(TG)和Partition Group(PG)。这种架构既兼顾了数据的内聚性,又能够实现数据的切分,以满足不同业务的需求。其中,数据节点(DN)是最基本的单元,负责存储和处理数据;Table Group(TG)是逻辑上的数据集合,用于管理相关表的分布和复制;Partition Group(PG)则进一步将表的分区进行管理,以满足对数据更细粒度的操作。
PolarDB-X 的架构包括了多个关键节点,如Leader、Logger、Follower等。Leader节点负责对数据的写入和修改操作,Logger节点负责记录系统状态和变更历史,Follower节点则用于数据的备份和复制。这些节点之间通过Paxos-group来保持一致性,以确保数据的可靠性和一致性。
PolarDB-X 同时也具备了一系列的核心功能和组件,如计划缓存(Plan Cache)、事务管理(Transaction)、信息模式(Information Schema)和SQL解析器(SQL Parser)等。计划缓存可提高查询的性能,事务管理则保证了数据的一致性和完整性,信息模式则提供了对数据库元数据的访问和查询能力,SQL解析器则负责将用户的SQL语句解析成可执行的操作。
同时,PolarDB-X 还采用了Cascades Optimizer(RBO)作为查询优化器,能够根据查询的需求和系统的资源来选择最优的执行计划,提高查询的效率和性能。
总之,PolarDB-X 是一款性能强大、可靠稳定的分布式数据库,它采用了先进的架构和技术,能够满足用户在大规模数据处理和高并发场景下的需求。作为云原生的解决方案,PolarDB-X 在可扩展性、可靠性和弹性方面都具备了独特的优势,为用户提供了卓越的数据库服务体验。
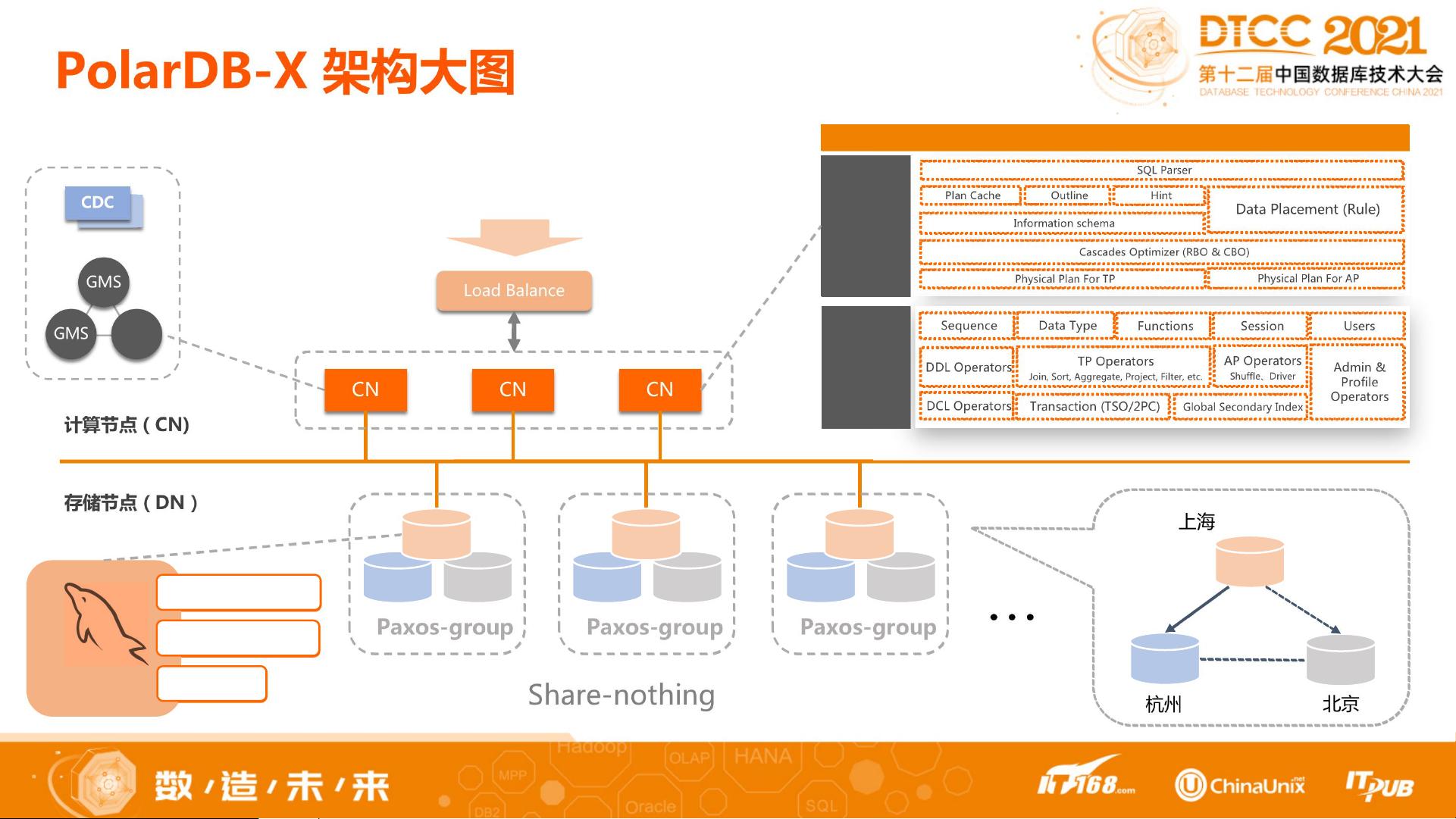
PolarDB-X 架构大图
Leader
Logger
Follower
上海
杭州
北京
CN
计算节点(CN)
存储节点(DN)
…
Load Balance
CN
…
CN
Follower Logger
Leader
Paxos-group
Follower Logger
Leader
Paxos-group
Follower Logger
Leader
Paxos-group
Share-nothing
Plan Cache Outline
Transaction (TSO/2PC)
Information schema
SQL Parser
Cascades Optimizer (RBO & CBO)
Physical Plan For TP
Physical Plan For AP
AP Operators
Shuffle、Driver
Functions
Sequence
Hint
Data Placement (Rule)
Data Type
TP Operators
Join, Sort, Aggregate, Project, Filter, etc.
MySQL Protocol
Session
Users
Admin &
Profile
Operators
DDL Operators
DCL Operators
Global Secondary Index
Optimizer
Executor
Private Protocol
CTs based MVCC
X-Paxos
MySQL
CDC
CDC
GMS
GMS GMS
剩余16页未读,继续阅读
2021-10-15 上传
2021-10-15 上传
2021-07-04 上传
2024-02-02 上传
2021-03-18 上传
2020-10-22 上传
2021-08-09 上传
2021-06-07 上传

林书尼
- 粉丝: 28
- 资源: 315
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
