华泰证券AI选股周报:Stacking长期胜出,多策略对比分析
需积分: 0 171 浏览量
更新于2024-06-22
收藏 603KB PDF 举报
华泰证券于2018年05月20日发布的《人工智能选股周报》指出,本周在不同的股票市场和策略配置下,不同的人工智能模型表现出不同的优势。报告主要关注了全A选股(非行业中性)、沪深300行业中性以及中证500行业中性三种情况下的选股策略。
首先,在全A选股(非行业中性)方面,XGBoost算法表现最为出色,它在本周获得了1.40%的绝对收益和1.34%的超额收益,显示出其在市场波动中的稳定性和盈利能力。XGBoost是一种集成学习方法,通过组合多个弱分类器来提高预测精度。
在沪深300行业中性策略中,Stacking算法成为赢家,尽管本周沪深300指数涨幅较小,但Stacking策略相对基准的超额收益为-0.07%,表明其在行业调整时可能有更好的风险控制能力。Stacking是一种模型融合技术,通过结合多个基础模型的预测结果来提高整体性能。
在中证500行业中性策略中,逻辑回归表现最佳,实现了0.81%的绝对收益和0.75%的超额收益,显示其对小盘股市场动态有较好的捕捉能力。
报告还提到了其他策略,如SVM和随机森林,它们在最近三个月和一年的超额收益上分别位居前列。SVM(支持向量机)以其在数据分类和回归问题上的优势,展现出了长期投资的价值;而随机森林则以其强大的预测和泛化能力,成为长期超额收益的主要贡献者。
值得注意的是,投资者在使用这些策略时,应结合市场环境和自身的投资目标,因为报告中提到的超额收益并不保证未来表现,且投资者需了解并遵循证券研究报告中的重要声明和华泰证券的股票和行业评级标准,以做出明智的投资决策。
总结来说,这份人工智能选股周报揭示了人工智能在股票投资中的应用潜力,展示了不同模型的优势和适用场景,同时也强调了投资者在应用这些技术时需要考虑的全面因素。通过理解和分析这些信息,投资者可以更有效地利用人工智能技术进行股票投资,提高投资组合的长期回报。
金工研究/量化投资周报 | 2018 年 05 月 20 日
谨请参阅尾页重要声明及华泰证券股票和行业评级标准 4
图表3: 华泰人工智能选股策略绩效(全 A 选股,非行业中性)
策略名称
比较基准
年化收益率
年化波动率
夏普比率
最大回撤
年化超额收
益率
年化跟踪
误差
超额收益
最大回撤
信息比率
Calmar
比率
相对基准
月胜率
月均双边
换手率
Stacking
中证 500
37.45%
30.01%
1.25
49.26%
33.22%
9.19%
11.97%
3.61
2.78
72.41%
147.52%
SVM
中证 500
17.15%
28.47%
0.60
46.88%
13.18%
7.32%
14.23%
1.80
0.93
65.52%
113.01%
朴素贝叶斯
中证 500
25.30%
26.35%
0.96
47.56%
20.09%
9.88%
11.11%
2.03
1.81
66.67%
112.15%
随机森林
中证 500
26.16%
28.58%
0.92
55.00%
21.71%
9.48%
21.43%
2.29
1.01
63.22%
145.89%
XGBoost
中证 500
30.94%
27.69%
1.12
50.96%
26.05%
9.17%
19.75%
2.84
1.32
68.97%
147.59%
逻辑回归
中证 500
22.77%
26.66%
0.85
51.03%
17.91%
8.36%
10.68%
2.14
1.68
66.67%
135.98%
神经网络
中证 500
16.82%
27.38%
0.61
49.86%
12.43%
8.22%
13.35%
1.51
0.93
64.37%
171.26%
中证 500
中证 500
3.66%
26.99%
0.14
54.35%
资料来源:Wind,华 泰证券 研究所
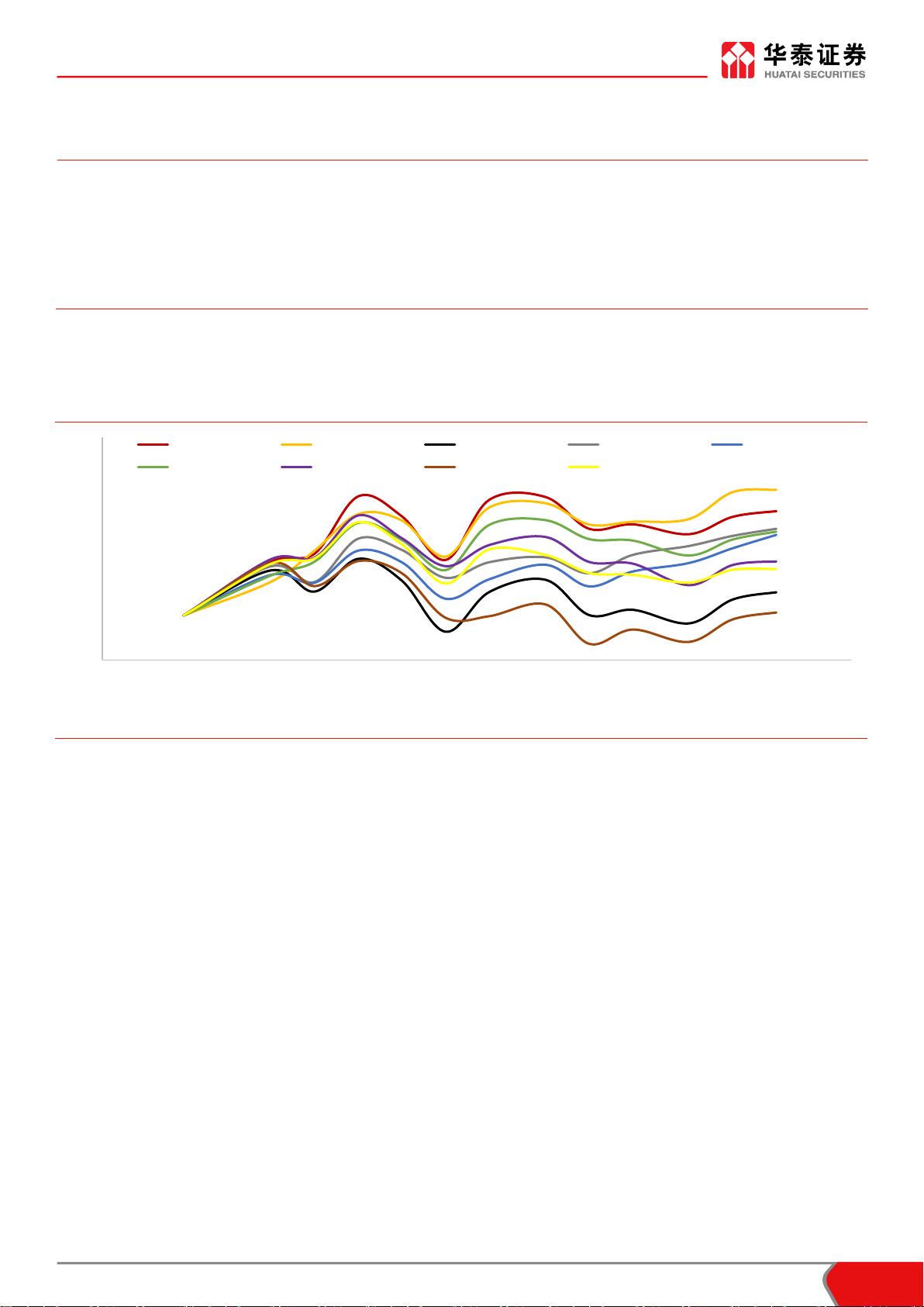
图表 4 显示了最近一季度华泰人工智能选股策略(全 A 选股,非行业中性)净值表现。
图表4: 华泰人工智能选股策略最近一季度净值表现(全 A 选股,非行业中性)
资料来源:Wind,华 泰证券 研究所
我们在 Wind 组合管理(PMS)平台上建立了模拟组合,每个月底选择最近 3 个月表现最
好的模型构建组合并上传到 PMS,组合名称关键字为“华泰 AI 选股(全 A 非行业中性)”,
欢迎搜索关注。
0.95
1
1.05
1.1
1.15
1.2
2018/1/30
2018/2/9
2018/2/19
2018/3/1
2018/3/11
2018/3/21
2018/3/31
2018/4/10
2018/4/20
2018/4/30
2018/5/10
2018/5/20
2018/5/30
Stacking SVM
朴素贝叶斯 随机森林
XGBoost
逻辑回归 神经网络 沪深300 中证500
剩余16页未读,继续阅读
2021-09-03 上传
2023-07-28 上传
2023-07-28 上传
2021-03-05 上传
点击了解资源详情
点击了解资源详情
2023-07-22 上传
2021-08-10 上传
2021-08-10 上传


qq_41146932
- 粉丝: 12
- 资源: 6307
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Python和Opencv的车牌识别系统实现
- 我的代码小部件库:统计、MySQL操作与树结构功能
- React初学者入门指南:快速构建并部署你的第一个应用
- Oddish:夜潜CSGO皮肤,智能爬虫技术解析
- 利用REST HaProxy实现haproxy.cfg配置的HTTP接口化
- LeetCode用例构造实践:CMake和GoogleTest的应用
- 快速搭建vulhub靶场:简化docker-compose与vulhub-master下载
- 天秤座术语表:glossariolibras项目安装与使用指南
- 从Vercel到Firebase的全栈Amazon克隆项目指南
- ANU PK大楼Studio 1的3D声效和Ambisonic技术体验
- C#实现的鼠标事件功能演示
- 掌握DP-10:LeetCode超级掉蛋与爆破气球
- C与SDL开发的游戏如何编译至WebAssembly平台
- CastorDOC开源应用程序:文档管理功能与Alfresco集成
- LeetCode用例构造与计算机科学基础:数据结构与设计模式
- 通过travis-nightly-builder实现自动化API与Rake任务构建
