K均值聚类算法详解:基本与改进版本
需积分: 50 97 浏览量
更新于2024-07-19
2
收藏 691KB PPTX 举报
K均值聚类算法是一种常用的无监督机器学习方法,用于数据集的分群,目的是将数据划分为k个互不重叠的簇,每个簇内的数据点彼此相似度高,而不同簇之间的相似度低。该算法的基本思想是迭代地将数据点分配到最近的质心(簇中心),并更新这些质心的位置,直到聚类中心不再改变或达到预设的迭代次数。
PPT内容覆盖了以下几个关键部分:
1. **算法介绍**:
- 定义:聚类问题的目标是将元素集合划分为k个簇,每个簇内部差异小,簇间差异大。
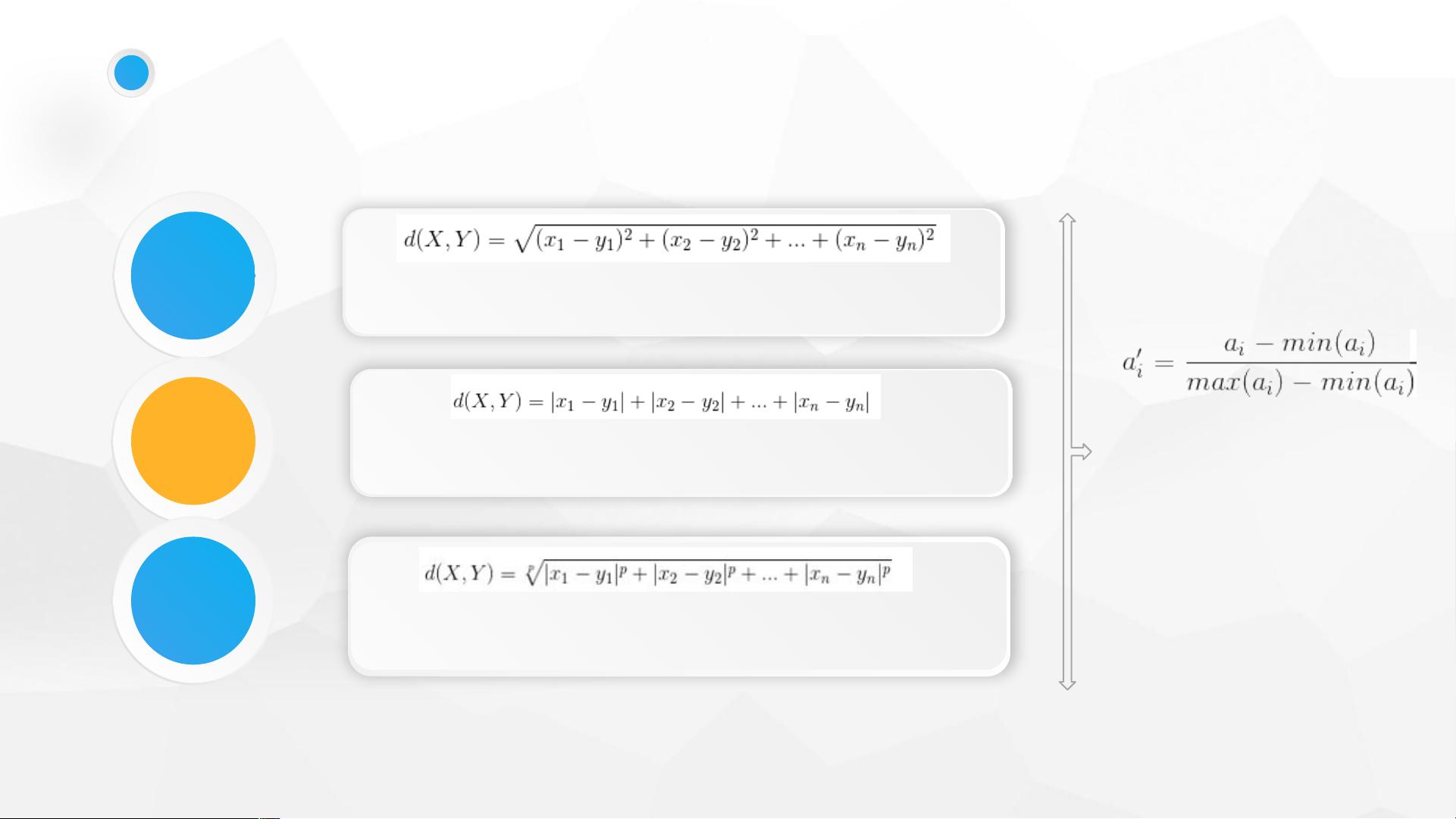
- **距离度量**:
- 欧几里得距离:固定直角坐标系中两点间的直线距离。
- 闵可夫斯基距离:欧几里得距离和曼哈顿距离的推广,适用于多维空间。
- 归一化处理:确保所有数据在比较时具有相同的尺度。
- **相异度计算**:
- 序数变量和分类变量的处理方式不同,前者通过秩值表示,后者通过属性差异率来衡量。
2. **算法流程**:
- 初始化:随机选择k个质心,或者使用改进算法如K-means++来初始化。
- 分配:将每个数据点分配到与其最近的质心所在的簇。
- 更新质心:计算每个簇的新质心,作为簇中心。
- 重复步骤2和3,直到簇中心不再改变或达到预设迭代次数。
3. **改进算法**:
- K-means++:一种有效的初始化策略,减少初始聚类中心的选择偏差。
- Isodate算法:可能是针对特定场景的优化版本,未详述。
- 二分K均值:将数据集二分处理,降低计算复杂度,适用于大规模数据集。
4. **应用示例**:
- 非人恶意流量识别
- 求职信息优化
- 生物种群分析
- 网站关键词和流量分析
- 保险投保者分组
- 用户画像建立
- 商业选址决策
5. **算法限制**:
- 对于数据分布、簇的形状和大小敏感
- 需要预先设定簇的数量K
- 受初始聚类中心的影响,可能得到局部最优解
- 不适合处理非凸形状的簇和大小悬殊的簇
K-means算法因其简单高效,在大数据处理中表现出色,但对于某些特定条件下的聚类效果可能不尽人意。在实际应用中,可能需要结合其他聚类算法或方法进行调整和优化。

相异度
标量也就是无方向意义的数字,也叫
标度变量
标量
二元变量是只能取 0 和 1 两种值变量,
通常用来标识是或不是这种二值属性
二元变量
分类变量是二元变量的推广,类似于
程序中的枚举变量
分类变量
01
0
2
0
3
序数变量是具有序数意义的分类变量,
通常可以按照一定顺序意义排列
序数变量
04
有大小而且有方向
向量
05
剩余25页未读,继续阅读
点击了解资源详情
1261 浏览量
点击了解资源详情
2021-10-02 上传
1261 浏览量
2024-11-10 上传
172 浏览量

yimingfei
- 粉丝: 3
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 2023-12版本ZLM流媒体平台Windows安装包
- MapReduce实现TopN中文词频统计+英文词频统计+中文词频统计
- c++信息学竞赛及算法4阶段60节体系课程PPT,循环嵌套,递归排序,贪心算法等
- 基于nodejs人事管理系统的设计与实现(论文+源码)-kaic.rar
- 计算机控制系统课程设计说明.rar+word格式
- 基于UDP的聊天机器人源码
- gan.rargan.rargan.rar
- 关于医院系统的mysql面试题及答案.rar
- C基础系列-第一个C程序HelloWorld
- log4j日志写入redis扩展
- springboot整合log4j入门程序
- STM32 密码锁程序加Proteus仿真
- CBM209X-UMPToolV7200(2020-05-20).zip
- C++ 数据结构知识点合集-C/C++ 数组允许定义可存储相同类型数据项的变量-供大家学习研究参考
- 快速搭建基本设计还原效果的 Android 项目QMUI-Android-master
- pdf转换工具-转换word、excel、PPT等
