Python数据分析:空值、缺失值与重复值处理技巧
版权申诉
12 浏览量
更新于2024-06-27
收藏 7.39MB PPTX 举报
"该资源为一个关于Python数据分析的PPT,主要探讨了如何处理空值、缺失值以及重复值的问题,旨在提升数据质量和确保数据的完整性、唯一性、权威性、合法性、一致性。"
在数据分析中,空值(Null)和缺失值(Missing Value)的处理是至关重要的步骤,因为它们可能导致分析结果产生偏差或错误。Python提供了多种方法来处理这些问题。首先,`isnull()`函数是用于检测数据集中是否存在空值或缺失值的工具。它会返回一个与原数据集大小相同的布尔型数组,其中True表示对应位置存在空值,False则表示无空值。
`dropna()`函数则用于删除含有空值的行或列。默认情况下,如果一行或多列中有任何空值,该行或列将会被整个删除。然而,这可能并不总是最佳策略,因为它可能会导致数据的丢失。因此,可以结合使用`dropna()`的`how`、`thresh`等参数来进行更精确的控制,例如仅删除完全由空值组成的行或列。
对于空值的填充,`fillna()`函数非常实用。它允许用户指定一个值(如0、'NA'等)来填充空值,或者使用方法(如前向填充`ffill`、后向填充`bfill`等)来根据已有数据进行填充。需要注意的是,`fillna()`的`Method`参数和`value`参数不能同时使用,因为它们分别代表不同的填充策略。
处理数据中的重复值是另一个关键任务。`duplicated()`方法用于检测数据集中是否存在重复的条目。它会返回一个布尔型数组,其中True表示某条记录已被标记为重复,False则表示记录是唯一的。`duplicated()`的默认行为是将首次出现的条目视为唯一,后续出现的相同条目视为重复。可以通过设置`keep`参数为'first'(默认)或'last'来改变这一行为,决定保留第一次出现的还是最后一次出现的重复项。
`drop_duplicates()`函数则用于删除重复的记录。默认情况下,它会删除所有重复的条目,只保留第一次出现的。`subset`参数可用来指定仅在特定列上检查重复性,而`inplace`参数控制是否直接在原始数据集上进行修改。如果`inplace=True`,则会在原数据集上删除重复项,否则不会改变原数据。
理解和熟练运用这些Python数据分析工具对于数据预处理和确保分析结果的准确性和可靠性至关重要。通过有效的数据清洗,我们可以减少潜在的错误源,提高分析的有效性,并为后续的数据挖掘和建模提供高质量的数据基础。
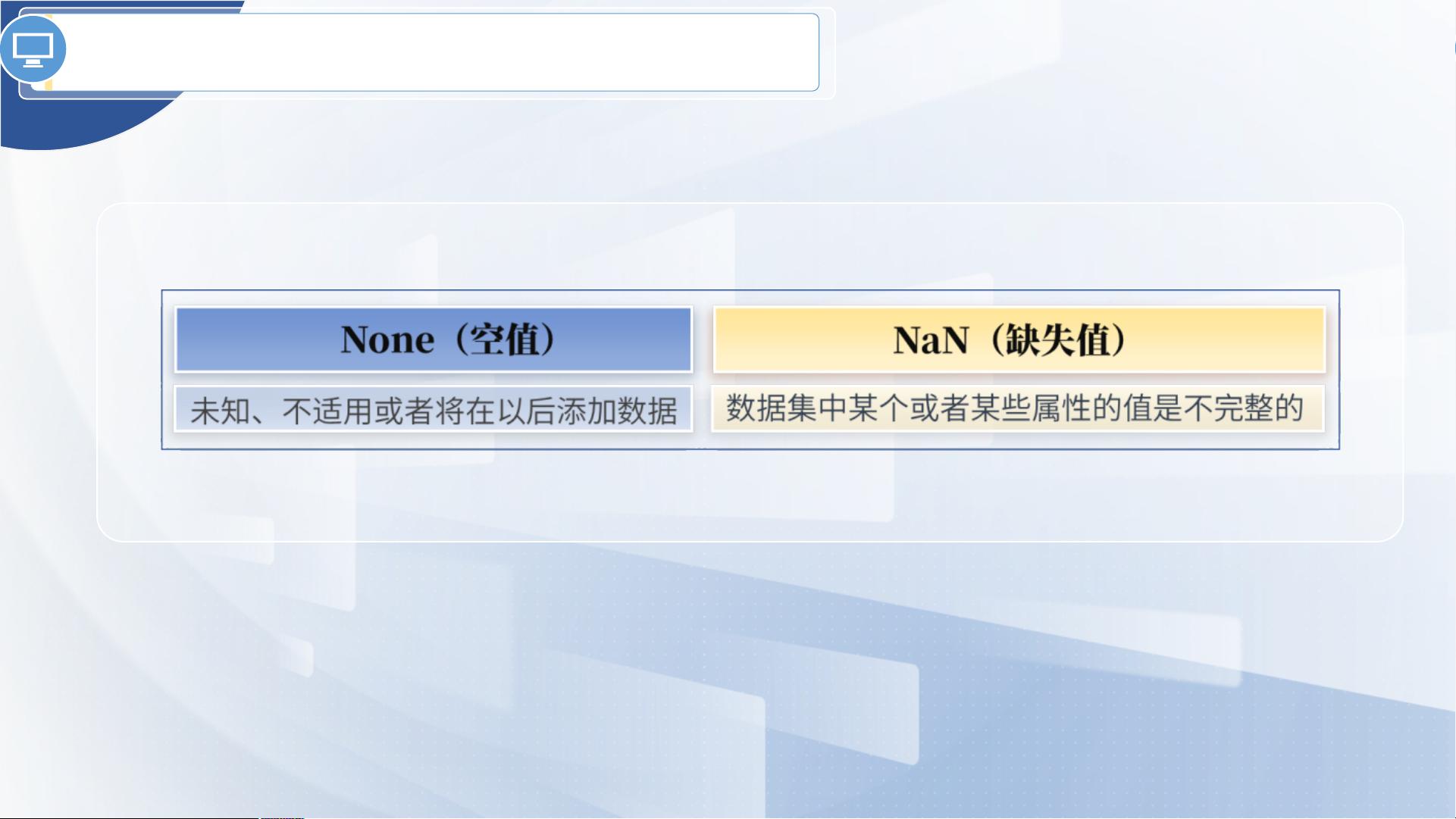
空值和缺失值的处理和重复值处理
剩余17页未读,继续阅读
2021-09-15 上传
2024-05-06 上传
2022-07-14 上传
2023-06-08 上传
2023-12-16 上传
2023-06-08 上传
2023-05-26 上传
2023-06-13 上传
2023-06-10 上传

知识世界
- 粉丝: 375
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
