互联网KPI异常检测:挑战与评估
下载需积分: 0 | PDF格式 | 1018KB |
更新于2024-08-05
| 178 浏览量 | 举报
"该资源主要关注的是KPI异常检测这一科研问题,特别是在互联网和移动互联网高速发展的背景下,如何通过算法来提升web服务的稳定性。KPI异常检测涉及到的关键点包括异常的低频率、多样性和数据的多样性。同时,资源提供了数据集供研究者下载,以提升异常检测算法的精度和效率。"
在现代互联网环境中,KPI(关键性能指标)异常检测是运维保障的重要组成部分。KPI异常检测的目标是识别出那些可能预示着系统问题的不正常行为。这通常涉及对时间序列数据的深度分析,以便在异常行为出现时能够及时发出警报。然而,这个任务具有若干挑战:
1. 异常低频:异常事件的发生频率相对较低,使得获取足够的异常样本进行训练变得困难。这要求算法能够在少量异常数据的情况下依然保持高识别能力。
2. 异常多样性:由于复杂的业务环境和不断变化的系统,异常可能以各种不同的形式出现,增加了识别的难度。
3. KPI多样性:KPI可以表现为周期性、稳定性或不稳定性,每种类型都有其独特的特征,需要算法具备灵活适应不同类型的KPI的能力。
为了解决这些问题,资料中提到了一个在线平台(http://iops.ai/),提供了真实场景下的KPI数据集,用于研究和改进异常检测算法。数据集经过脱敏处理,确保了隐私保护。通过参与竞赛和分析这些数据,研究人员和业界专家可以共同提升异常检测算法的精确度(precision)和召回率(recall),减少误报和漏报,从而帮助运维人员更高效地发现并处理问题。
评估异常检测算法性能的标准通常包括准确率和召回率。准确率是指被算法正确识别为异常的实例占所有异常实例的比例,而召回率则是指被正确识别的异常实例占所有实际异常实例的比例。一个理想的算法应同时具备高准确率和高召回率,以最大限度地减少运维人员的工作负担,并确保异常能够被及时准确地发现。
因此,对于算法开发者来说,关键在于设计出能够有效应对低频、多样性和多变性的KPI数据的模型。这可能涉及到深度学习、时间序列分析、统计建模等多种技术的结合,同时也需要考虑实时性、计算效率和可扩展性等因素,以适应大规模的互联网服务环境。通过不断地迭代和优化,期望能够大幅提升KPI异常检测的性能,进一步保障web服务的稳定运行。
KPI 异常检测科研问题的原始出处
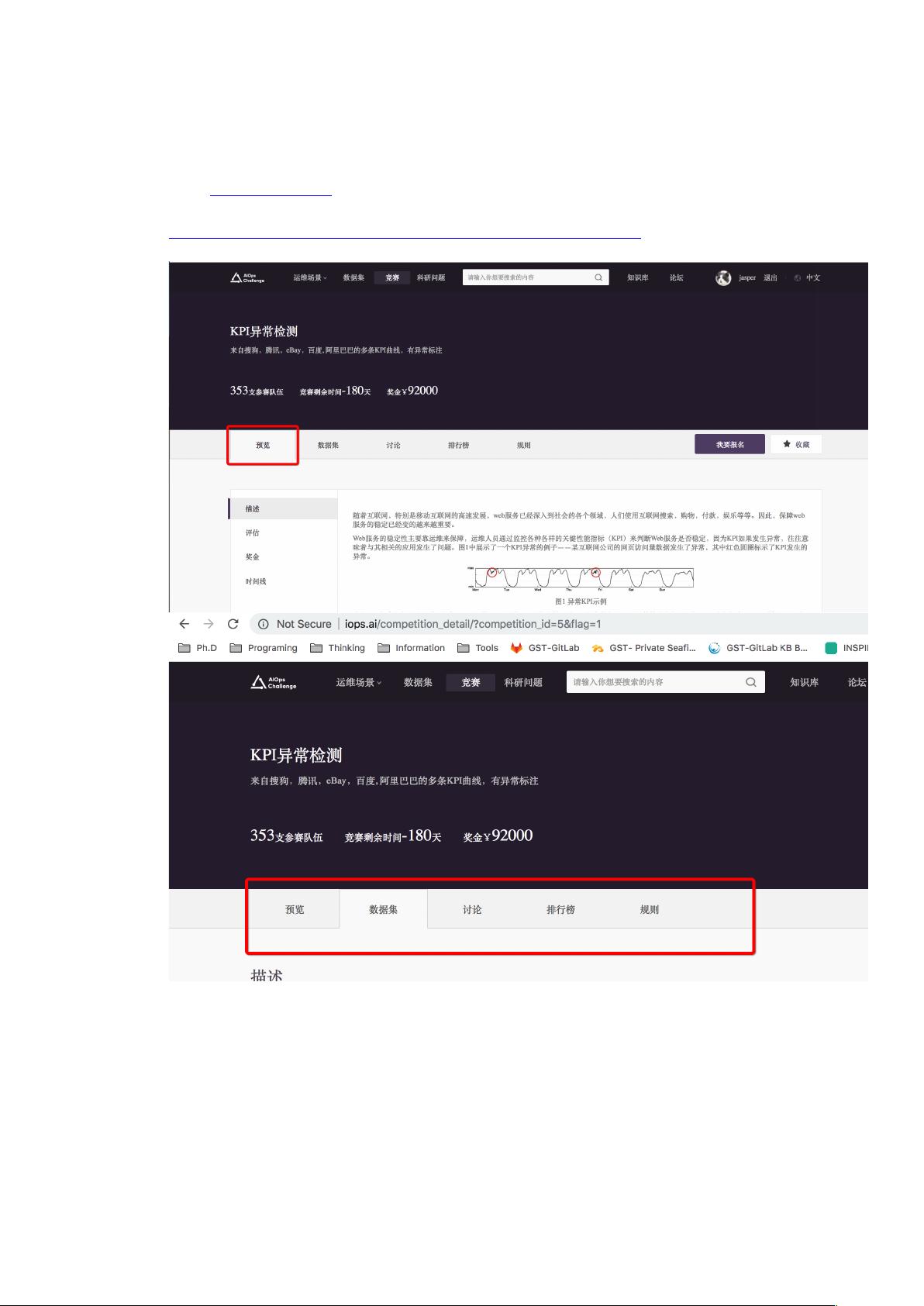
1. 登录 http://iops.ai/,注册账号
2. 进入到“竞赛”模块,找到 KPI 异常检测页面:
http://iops.ai/competition_detail/?competition_id=5&flag=1
3. 预览查看问题描述,并下载数据集
下载后可阅读完整内容,剩余4页未读,立即下载
相关推荐





经年哲思
- 粉丝: 25
- 资源: 329
 我的内容管理
展开
我的内容管理
展开







最新资源
- 2009年凌阳最新的芯片选型参考资料
- domino URL命令
- E3Guide e3:tree的开发指南
- Serv-U FTP的建立和维护手册(PDF)
- 基于S3C2440的嵌入式LINUX系统移植的研究与实现
- 基于ARM的嵌入式视频监控系统客户端设计实现
- LINUX操作系统实时性的分析与改进策略
- windows xp sp2不是提供远程桌面共享-远程计算机已结束连接
- SQL21自学通edit
- STM32硬件设计手册
- ubuntu_pocket_guide_and_reference.8109283240.pdf
- More Effective C++(中文版).pdf
- as3.0组件详细使用与开发教程
- 你必须知道的495个C语言问题
- Flex ActionScript 3.0 Cookbook 中文版
- 学习jsp自定义标签
