DEYO:一步到位的DETR+YOLO 实时目标检测
版权申诉
92 浏览量
更新于2024-08-03
1
收藏 5.23MB PDF 举报
DEYO是一种结合了YOLO(You Only Look Once)架构的改进版DETR(Detector Transformer),旨在解决目标检测任务中的端到端学习问题。传统的DETR依赖于ImageNet上的预训练,但其基于一对一匹配的策略提供的监督信号有限,导致颈部网络预训练不足,且训练初期匹配的不稳定会影响优化目标的一致性。为解决这些问题,研究者提出了一种创新的训练方法——分步训练。
在DEYO的设计中,首先进行两阶段的训练过程。在第一阶段,研究人员使用经典的检测器,采用一对多匹配策略进行预训练,这有助于初始化DETR的 backbone(特征提取部分)和 neck(将特征转化为检测区域表示的部分)。这种方法增强了特征表示的学习,使得后续端到端模型的性能得以提升。
在第二阶段,训练进入重点,backbone和neck被冻结,仅允许解码器(负责预测目标位置和类别)从头开始训练。这种分离式的训练策略有助于稳定解码器的学习,并确保优化目标的一致性。这样做的结果是,DEYO成为首个实时性良好的端到端目标检测模型,能够在保持高精度的同时实现较快的速度,无需额外依赖补充训练数据。
DEYO的独特之处在于它采用了纯卷积结构的编码器,这与传统的基于全连接层的Transformer架构有所不同,从而在硬件资源有限的情况下,如使用单个8GB的RTX 4060 GPU,也能完成COCO数据集的训练,显著降低了训练成本。DEYO系列的开源代码和预训练模型可以在指定的URL获取,使得更多研究者能够参与到这一领域的探索中来。
DEYO的出现革新了目标检测领域的训练策略,展示了深度学习特别是Transformer架构在实时目标检测中的潜力,同时也为其他端到端模型提供了有价值的训练范例。
DEYO: DETR with YOLO for End-to-End Object Detection
Haodong Ouyang
Southwest Minzu University
Chengdu, China
ouyanghaodong@stu.swun.edu.cn
Abstract
The training paradigm of DETRs is heavily contingent
upon pre-training their backbone on the ImageNet dataset.
However, the limited supervisory signals provided by the
image classification task and one-to-one matching strategy
result in an inadequately pre-trained neck for DETRs. Ad-
ditionally, the instability of matching in the early stages of
training engenders inconsistencies in the optimization ob-
jectives of DETRs. To address these issues, we have de-
vised an innovative training methodology termed step-by-
step training. Specifically, in the first stage of training, we
employ a classic detector, pre-trained with a one-to-many
matching strategy, to initialize the backbone and neck of
the end-to-end detector. In the second stage of training,
we froze the backbone and neck of the end-to-end detec-
tor, necessitating the training of the decoder from scratch.
Through the application of step-by-step training, we have
introduced the first real-time end-to-end object detection
model that utilizes a purely convolutional structure encoder,
DETR with YOLO (DEYO). Without reliance on any sup-
plementary training data, DEYO surpasses all existing real-
time object detectors in both speed and accuracy. Moreover,
the comprehensive DEYO series can complete its second-
phase training on the COCO dataset using a single 8GB
RTX 4060 GPU, significantly reducing the training expen-
diture. Source code and pre-trained models are available at
https://github.com/ouyanghaodong/DEYO.
1. Introduction
Object detection is a fundamental task within the field
of computer vision, tasked with the precise localization and
identification of various object categories within images or
videos. This technology is a cornerstone for many com-
puter vision applications, including autonomous driving,
video surveillance, facial recognition, and object tracking.
In recent years, advancements in deep learning, particularly
methods based on Convolutional Neural Networks (CNNs)
[12], have led to groundbreaking progress in object detec-
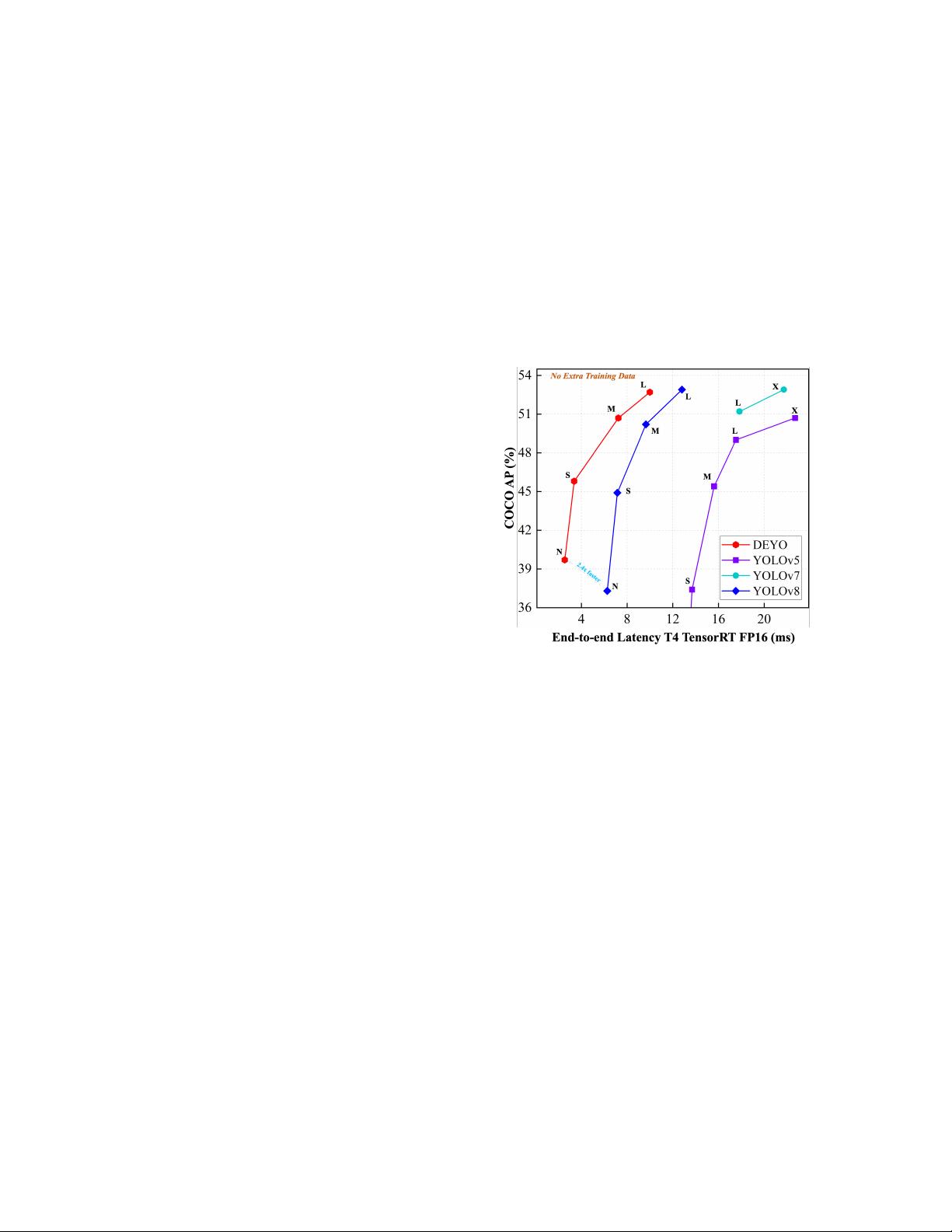
Figure 1. DEYO has surpassed other real-time object detectors in
speed and accuracy; all detectors were exclusively trained on the
COCO dataset without any additional datasets.
tion tasks, establishing themselves as the predominant tech-
nology in this domain.
DEtection TRansformer (DETR) [3] introduces an end-
to-end approach for object detection, comprising a CNN
backbone, transformer encoder, and transformer decoder.
DETR employs a Hungarian loss to predict a one-to-one
set of objects, thereby eliminating reliance on the manually
tuned component of Non-Maximum Suppression (NMS),
which significantly streamlines the object detection pipeline
through end-to-end optimization.
Although end-to-end object detectors based on Trans-
formers (DETRs) have achieved notable success in terms of
performance, these detectors typically rely on pre-training
their backbone networks on the ImageNet dataset. Should
a new backbone be selected, it necessitates pre-training on
ImageNet before training the DETRs or utilizing an exist-
ing pre-trained backbone. Such dependency limits the flexi-
bility in designing the backbone and escalates development
costs, and when the task dataset significantly diverges from
ImageNet, this pre-training strategy may result in subopti-
1
arXiv:2402.16370v1 [cs.CV] 26 Feb 2024
下载后可阅读完整内容,剩余9页未读,立即下载
2023-06-16 上传
2021-01-27 上传
2021-05-21 上传
2021-05-05 上传
点击了解资源详情
2024-10-24 上传
2024-10-24 上传


人工智能_SYBH
- 粉丝: 4w+
- 资源: 222
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Jive for Android SDK:示例应用的使用指南
- Python中的贝叶斯建模与概率编程指南
- 自动化NBA球员统计分析与电子邮件报告工具
- 下载安卓购物经理带源代码完整项目
- 图片压缩包中的内容解密
- C++基础教程视频-数据类型与运算符详解
- 探索Java中的曼德布罗图形绘制
- VTK9.3.0 64位SDK包发布,图像处理开发利器
- 自导向运载平台的行业设计方案解读
- 自定义 Datadog 代理检查:Python 实现与应用
- 基于Python实现的商品推荐系统源码与项目说明
- PMing繁体版字体下载,设计师必备素材
- 软件工程餐厅项目存储库:Java语言实践
- 康佳LED55R6000U电视机固件升级指南
- Sublime Text状态栏插件:ShowOpenFiles功能详解
- 一站式部署thinksns社交系统,小白轻松上手
