搭建高可用Hadoop集群:NFS-Namenode,Zookeeper主节点选举
需积分: 50 32 浏览量
更新于2024-07-17
收藏 728KB DOCX 举报
"本文档介绍了如何搭建一个高可用的Hadoop集群,包括基于NFS共享磁盘的Namenode配置以及利用Zookeeper实现主节点的推举。集群包含Namenode、Datanode和Zookeeper节点,旨在提供稳定的数据存储和处理能力。"
在构建Hadoop集群时,首要任务是进行集群规划。在这个示例中,我们有两台服务器作为Namenode(10.25.24.92和10.25.24.93),三台服务器作为Datanode(10.25.24.89、10.25.24.90和10.25.24.91),以及Zookeeper用于实现高可用性推举机制。Namenode是Hadoop分布式文件系统(HDFS)的管理节点,负责元数据的管理和调度,而Datanode则负责实际数据的存储。
在服务器设置阶段,首先要确保所有机器的hostname正确设置。使用root用户进行操作,并重启网络服务以应用更改。接着,为了简化节点间的通信,需要配置SSH免密登录。通过`ssh-keygen`命令生成RSA密钥对,然后将公钥复制到所有节点的`~/.ssh/authorized_keys`文件中,并确保文件权限为600。
接下来,我们转向Zookeeper的配置。首先从Apache官网下载Zookeeper的最新版本(此处为3.4.13),上传到服务器并解压。创建Zookeeper的数据目录(例如`/home/oss/hadoop/zookeeper-3.4.13/zkData`),并编辑`conf/zoo.cfg`配置文件。在`zoo.cfg`中,需要配置`server.x`参数,其中`x`应与每个节点的`myid`文件中的ID相匹配,未使用的服务器行应注释掉。
Hadoop配置文件的设置是集群搭建的关键部分。首先,确保Hadoop环境已安装了正确的JDK。对于HDFS的配置,需要定义一个逻辑名称(如`mycluster`),这有助于识别不同的Hadoop集群。在`hdfs-site.xml`中,添加如下配置:
```xml
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
```
此外,还需要配置Namenode的高可用性,这通常涉及到NFS共享磁盘,使得两个Namenode可以访问相同的元数据。在NFS服务器上设置共享目录,并在Namenode节点上挂载该目录。同时,还需配置HA相关的参数,如`dfs.ha.namenodes.mycluster`和`dfs.namenode.shared.edits.dir`等。
对于YARN(Yet Another Resource Negotiator),在`yarn-site.xml`中配置 ResourceManager 和 NodeManager 的相关参数,以支持集群资源管理和任务调度。MapReduce的配置主要集中在`mapred-site.xml`中,指定JobHistory Server和MapReduce作业的运行方式。
完成上述步骤后,可以启动Zookeeper集群,然后启动Hadoop的各个组件,包括Namenode、Datanode、Secondary Namenode和ResourceManager等。监控日志和系统状态,确保所有服务正常运行,集群就成功搭建起来了。
在实际生产环境中,还需要考虑监控、安全、性能优化和故障恢复策略等因素,以确保集群的稳定性和高效性。此外,持续的维护和更新也是必不可少的,以适应不断变化的业务需求和技术发展。
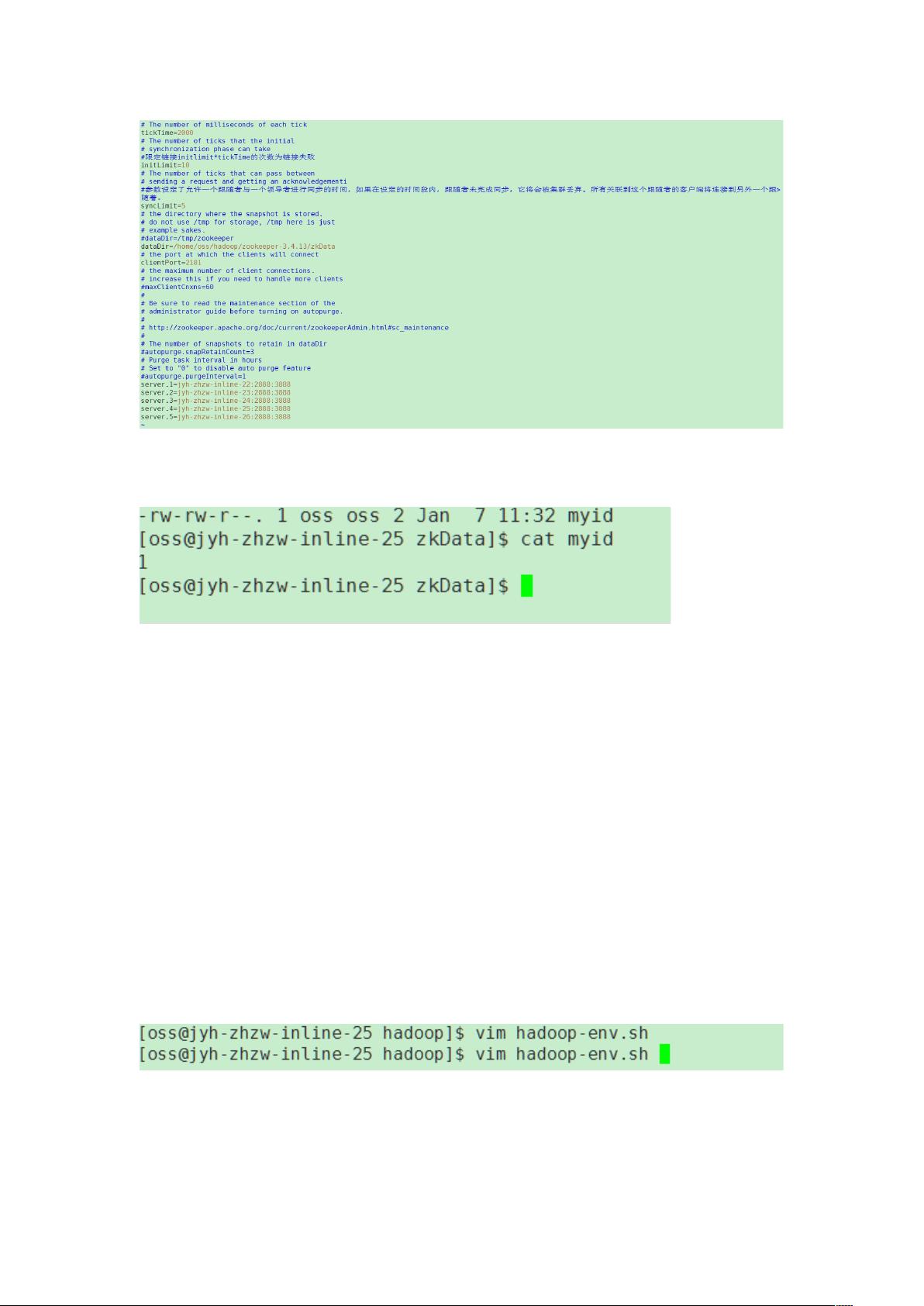
最后的 %65
注意 %65'这个 8 一定要和 对应起来,并且前面不用的服务器先注解调
4.设置 Hadoop 配置文件
4.1 设置 Hadoop 的 jdk 路径
剩余16页未读,继续阅读
2018-11-27 上传
2012-11-17 上传
2013-11-11 上传
2022-02-15 上传
点击了解资源详情

cutter_point
- 粉丝: 299
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- spark-study
- item_lister
- MAKEDATATIP:允许以编程方式将数据提示添加到任何有效的图形对象。-matlab开发
- [图片动画]Coppermine Photo Gallery v1.4.19 多国语言版_cpg1419.rar
- 锻炼追踪器
- Not today, Jeff-crx插件
- 参考资料-制冷系统气密性试验记录 (2).zip
- zmd:怎么的,假装自己是 markdown parser
- MATLAB7.8-image-process,matlab多旅行商问题源码,matlab源码下载
- cp-live-gmail-clone
- vue-reading:Vue源码阅读
- 简单清爽手机网站模板企业网站模板手机触屏版(单页)_网站开发模板含源代码(css+html+js+图样).zip
- pwr_kml_3d:从 [Time,Lat,Lon] 和 [Time,Depth/Altitude] 矩阵创建 3-D google earth KMZ 文件-matlab开发
- Brexit Stones-crx插件
- jest-json:玩笑匹配器可使用JSON字符串
- program-digital-clock,ide看c语言源码,c语言
