Flink剖析:Apache顶级项目的分布式数据流处理平台
183 浏览量
更新于2024-08-28
收藏 554KB PDF 举报
Flink剖析
Flink是Apache顶级项目之一,作为一个面向分布式数据流处理和批量数据处理的开源计算平台,能够基于同一个Flink运行时(Flink Runtime),提供支持流处理和批处理两种类型应用的功能。下面是Flink的详细剖析:
1. 概述
在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷。Flink是一个新的大数据处理引擎,目标是统一不同来源的数据处理。这与Spark的目标相似,但Flink和Spark的实现细节不同。
2. Flink概述
Flink是一个开源计算平台,能够基于同一个Flink运行时(Flink Runtime),提供支持流处理和批处理两种类型应用的功能。现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型,因为他们它们所提供的SLA是完全不相同的:流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理。
3. What's Flink
Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台。它能够基于同一个Flink运行时(Flink Runtime),提供支持流处理和批处理两种类型应用的功能。Flink从另一个视角看待流处理和批处理,将二者统一起来:Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
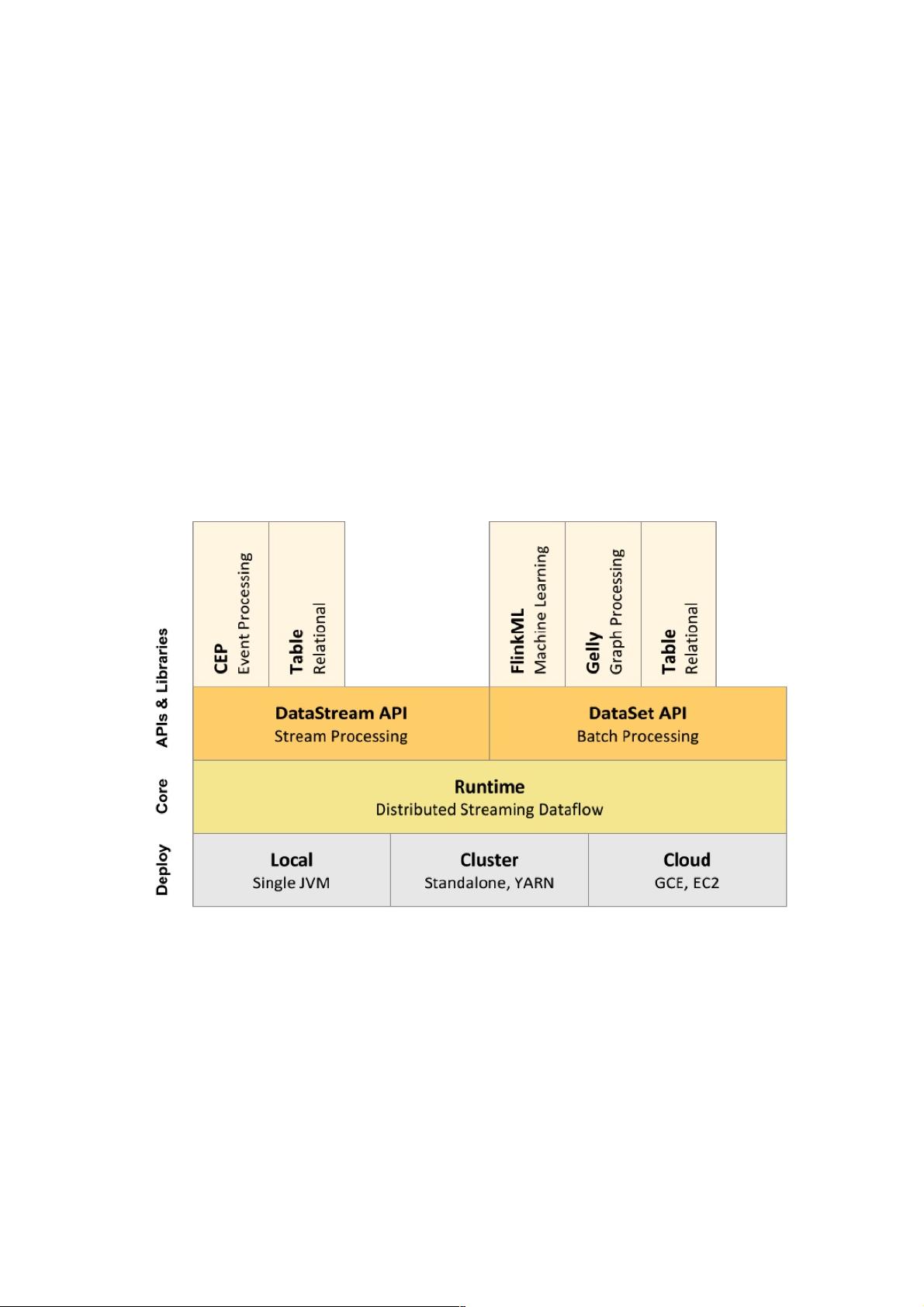
4. Flink技术栈
Flink技术栈是一个统一的平台,可以运行批量、流式、交互式、图处理、机器学习等应用。Flink技术栈的总览如图所示:
5. Compare with Spark
了解Flink的作用和优缺点,需要有一个参照物,这里,以它与Spark来对比阐述。从抽象层,内存管理,语言实现,以及API和SQL等方面来赘述。
5.1 Abstraction
Flink和Spark都有着相似的抽象层,但是Flink的抽象层更加灵活和强大。Flink可以处理流处理和批处理,而Spark主要处理批处理。
5.2 Memory Management
Flink和Spark都有着不同的内存管理机制。Flink使用了Netty来管理内存,而Spark使用了Tungsten来管理内存。
5.3 Language Implementation
Flink和Spark都支持多种语言的实现,包括Java、Scala、Python等。然而,Flink更加支持流处理和批处理的语言实现。
5.4 API and SQL
Flink和Spark都有着相似的API和SQL实现。然而,Flink的API和SQL更加灵活和强大,可以处理流处理和批处理的复杂应用场景。
Flink是一个功能强大且灵活的开源计算平台,可以处理流处理和批处理的复杂应用场景。它与Spark相比,具有不同的实现细节和技术栈,但是都可以作为大数据处理引擎使用。
Flink剖析剖析
1.概述
在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷。今天给大家分享一款产品—— Apache Flink,目前,
已是 Apache 顶级项目之一。那么,接下来,笔者为大家介绍Flink 的相关内容。
2.内容
2.1 What's Flink
Apache Flink 是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时(Flink
Runtime),提供支持流处理和批处理两种类型应用的功能。现有的开源计算方案,会把流处理和批处理作为两种不同的应用
类型,因为他们它们所提供的SLA是完全不相同的:流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞
吐、高效处理,所以在实现的时候通常是分别给出两套实现方法,或者通过一个独立的开源框架来实现其中每一种处理方案。
例如,实现批处理的开源方案有MapReduce、Tez、Crunch、Spark,实现流处理的开源方案有Samza、Storm。 Flink在实
现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来:Flink是完全支
持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为
有界的。基于同一个Flink运行时(Flink Runtime),分别提供了流处理和批处理API,而这两种API也是实现上层面向流处
理、批处理类型应用框架的基础。
Flink 是一款新的大数据处理引擎,目标是统一不同来源的数据处理。这个目标看起来和 Spark 和类似。这两套系统都在尝试
建立一个统一的平台可以运行批量,流式,交互式,图处理,机器学习等应用。所以,Flink 和 Spark 的目标差异并不大,他
们最主要的区别在于实现的细节。
下面附上 Flink 技术栈的一个总览,如下图所示:
2.2 Compare
了解 Flink 的作用和优缺点,需要有一个参照物,这里,笔者以它与 Spark 来对比阐述。从抽象层,内存管理,语言实现,以
及 API 和 SQL 等方面来赘述。
2.2.1 Abstraction
接触过 Spark 的同学,应该比较熟悉,在处理批处理任务,可以使用 RDD,而对于流处理,可以使用 Streaming,然其世纪
还是 RDD,所以本质上还是 RDD 抽象而来。但是,在 Flink 中,批处理用 DataSet,对于流处理,有 DataStreams。思想类
似,但却有所不同:其一,DataSet 在运行时表现为 Runtime Plans,而在 Spark 中,RDD 在运行时表现为 Java Objects。
在 Flink 中有 Logical Plan ,这和 Spark 中的 DataFrames 类似。因而,在 Flink 中,若是使用这类 API ,会被优先来优化
(即:自动优化迭代)。如下图所示:
下载后可阅读完整内容,剩余5页未读,立即下载
2021-01-07 上传
2020-06-28 上传
2022-04-20 上传
2019-04-19 上传
2019-09-18 上传
2021-03-25 上传
2024-12-01 上传
2024-12-01 上传

weixin_38703895
- 粉丝: 4
- 资源: 910
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
