GPU加速不连续变形分析:优化计算效率的管道设计
61 浏览量
更新于2024-08-27
收藏 697KB PDF 举报
本文主要探讨了如何在图形处理器(GPU)上优化并实现不连续变形分析(Discontinuous Deformation Analysis, DDA)方法的计算管道。DDA作为岩体力学中的重要数值分析工具,因其大时间步长和大变形处理能力而广受欢迎,但相对较低的计算效率是其面临的主要挑战。为了克服这个瓶颈,作者提出了一种基于GPU的完整DDA解决方案。
首先,文章关注了GPU架构下的DDA流程重组,目标是减少主机和设备之间的数据传输,从而提高整体计算效率。这个流程包括关键步骤:接触检测、全局矩阵构建、线性方程求解以及穿透检查。接触检测是识别结构间的相互作用,矩阵构建则是根据这些交互生成所需的数学模型;线性方程求解是核心部分,文中特别提到了共轭梯度法(Conjugate Gradient Method, CGM),并比较了不同预条件器的应用,如块Jacobi方法和对称逐步松弛(Symmetric Successive Over-Relaxation, SSOR)等,以优化求解过程的收敛速度和性能。
在GPU环境下,利用并行计算的优势,每个计算单元可以同时处理多个元素,极大地提升了处理大规模问题的能力。此外,通过将任务分解为可并行执行的小任务,减少了内存访问和数据复制的开销。文章可能还讨论了如何设计有效的数据布局策略,以适应GPU的内存层次结构,以及如何利用GPU的纹理内存来加速数据访问。
为了充分利用GPU的性能,文章可能会涉及GPU编程模型(如CUDA或OpenCL),描述了如何编写高效的GPU代码,并可能讨论了性能基准测试和优化结果,以证明这种GPU版DDA方法在实际工程应用中的优势。
这篇研究论文旨在通过深入理解GPU架构和优化技术,提升不连续变形分析方法在GPU上的执行效率,这对于处理复杂岩体动力学问题和大规模工程模拟具有重要意义。它不仅提供了理论框架,还可能包含实用的代码示例和性能提升的关键洞察,对于从事岩土工程计算、GPU应用或者数值方法改进的科研人员具有参考价值。
Architecting the Discontinuous Deformation Analysis Method Pipeline on the GPU
Yunfan Xiao, Min Huang, Qinghai Miao*, Jun Xiao and Ying Wang
School of Engineering Science
University of Chinese Academy of Science
Beijing, China
E-mail: xiaoyunfan12@mails.ucas.ac.cn {huangm, miaoqh, xiaojun, ywang}@ucas.ac.cn
Abstract—As an important numerical analysis method of
rock mechanics, discontinuous deformation analysis (DDA)
has been widely used in rock engineering. DDA has certain
advantages such as the large time step and the large
deformation, at the cost of relatively low computing
efficiency. To address the efficiency bottleneck of DDA, this
paper proposes a complete graphics processing unit (GPU)-
based version. The entire DDA pipeline, involving contact
detection, global matrix building, linear equation solving,
and interpenetration checking, is restructured according to
the GPU architecture to minimize data transmissions
between the host and device. For the equation solver in
DDA, a comparison study of the conjugate gradient method
with different preconditioners, i.e., block Jacobi, symmetric
successive over-relaxation (SSOR) approximate inverse, and
ILU, is introduced first, and a novel sparse matrix-vector
multiplication (SpMV) method, intended for the sparse
block symmetry matrix with distinct features and which
outperforms cuSPARSE by 2.8 times, is proposed as well.
Schemes to solve memory write conflicts and branch
divergences on the GPU are also introduced in contact
detection, global matrix building, and interpenetration
checking. For the stable analysis of a slope, the proposed
GPU-based DDA with double precision achieved a speed-up
rate that was 48.72 times higher than that of the original
CPU-based serial implementation.
Keywords-Discontinuous Deformation Analysis, Graphics
Processing Unit (GPU), Sparse Matrix-vector Multiplication
(SpMV), Contact Detection, Memory Write Conflict, Branch
Divergence
I. INTRODUCTION
Discontinuous deformation analysis (DDA) is a type of
discrete element method originally proposed by Shi in
1988. It can analyze the mechanical response of blocky
systems under general loading and boundary conditions.
Large displacements and deformations are considered
under both static and dynamic loadings [1].
DDA simulates the interaction of discrete bodies with
multi-time steps as discrete element method (DEM), but
solves stress-displacement problems in each step as finite
element method (FEM). DDA derives the global
simultaneous equations from the minimum potential
energy principle and takes displacements as unknowns,
which are solved in each iterative step. On the other hand,
DDA gives a real dynamic solution with the correct energy
consumption by frictional resistance at contact and at the
velocities passing between the successive steps [2].
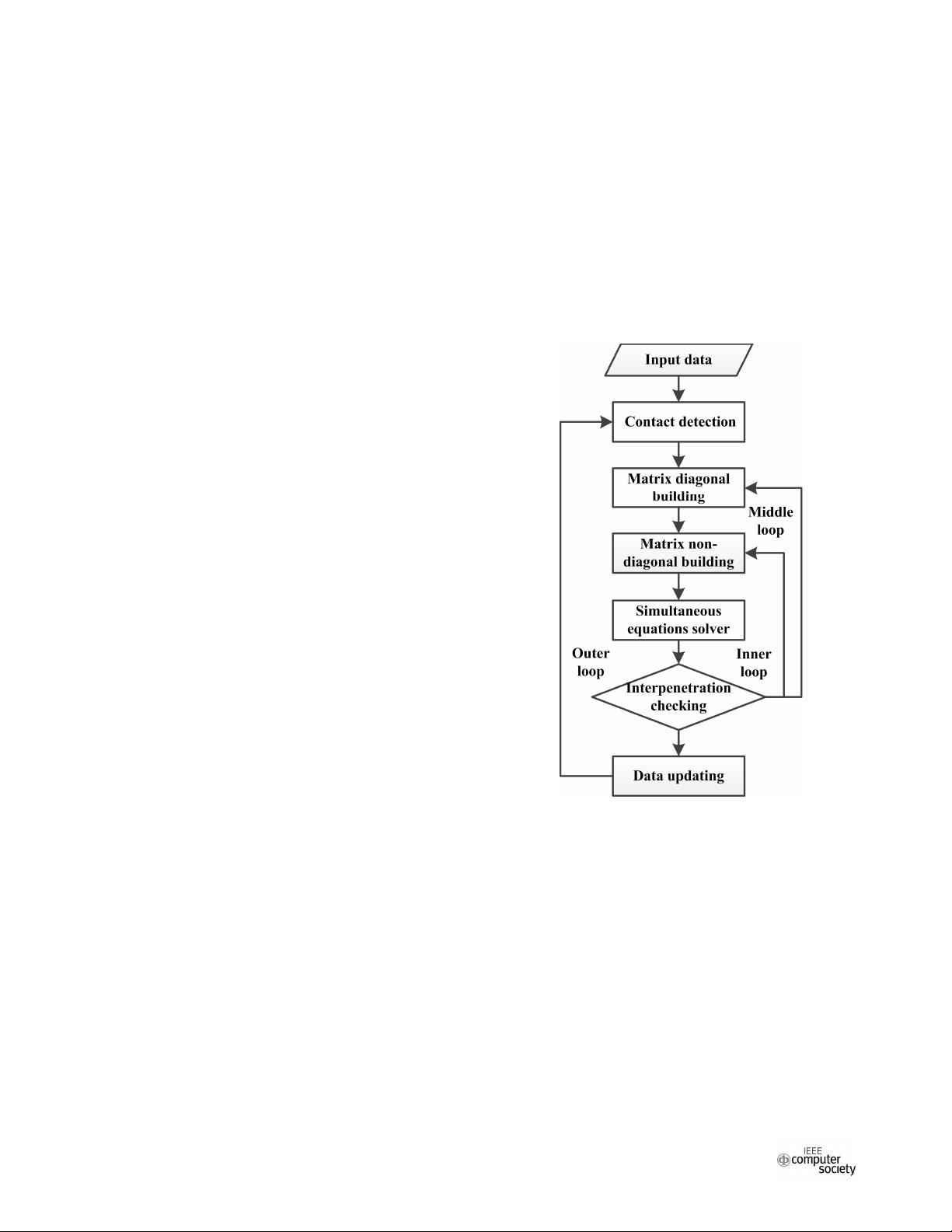
Figure 1. The pipeline of DDA on the CPU
These advantages of DDA lead to massive
computation. Besides data input, the pipeline of DDA
mainly includes six computing modules, including the
contact detection module, global stiffness matrix diagonal
building module, global stiffness matrix non-diagonal
building module, sparse linear symmetry equation solving
module, interpenetration checking module, and data
updating module. As illustrated in Fig. 1, the iterative loop
in the pipeline has three nested loops. The outer loop (loop
1) is the multi-time iterative step. The results of the
previous step will be the input data of the next step. This
iterative step allows DDA to simulate the large
displacement and deformation in blocky systems. The
middle loop (loop 2) is the maximum allowed
displacement iterative process. The displacement of each
block in the current step must be less than the double of
the maximum allowed displacement, which is a control
2017 IEEE International Parallel and Distributed Processing Symposium Workshops
978-0-7695-6149-3/17 $31.00 © 2017 IEEE
DOI 10.1109/IPDPSW.2017.93
1188
2017 IEEE International Parallel and Distributed Processing Symposium Workshops
978-1-5386-3408-0/17 $31.00 © 2017 IEEE
DOI 10.1109/IPDPSW.2017.93
1188
下载后可阅读完整内容,剩余9页未读,立即下载
2021-09-25 上传
2021-06-22 上传
2021-07-26 上传
2022-02-14 上传
2021-09-25 上传
2021-09-25 上传
点击了解资源详情
点击了解资源详情

weixin_38733355
- 粉丝: 4
- 资源: 897
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
